前言
梯度下降法( Gradient Descent )是机器学习中最常用的优化方法之一,常用来求解目标函数的极值。
其基本原理非常简单:沿着目标函数梯度下降的方向搜索极小值(也可以沿着梯度上升的方向搜索极大值)。
在《 [ Python 机器学习] 梯度下降法(一)》中简单分析了学习率大小对搜索过程的影响,发现:
学习率较小时,收敛到极值的速度较慢。
学习率较大时,容易在搜索过程中发生震荡。
本次介绍“冲量”的原理以及如何用“冲量”来解决上述两个问题。
冲量: momentum
“冲量”这个概念源自于物理中的力学,表示力对时间的积累效应。
在普通的梯度下降法 x += v 中,每次 x 的更新量 v 为 v = - dx × lr ,其中 dx 为目标函数 func(x)对 x 的一阶导数。
当使用冲量时,则把每次 x 的更新量 v 考虑为本次的梯度下降量 - dx × lr 与上次 x 的更新量 v 乘上一个介于 [0, 1] 的因子 momentum 的和,即 v = - dx × lr + v × momemtum 。
从公式上可看出:
当本次梯度下降 dx × lr 的方向与上次更新量 v 的方向相同时,上次的更新量能够对本次的搜索起到一个正向加速的作用。
当本次梯度下降 - dx × lr 的方向与上次更新量 v 的方向相反时,上次的更新量能够对本次的搜索起到一个减速的作用。
为了板式的清晰,完整实盘代码请戳:
https://uqer.io/community/share/58204d90228e5ba8f357140a为了查看 momentum 大小对不同学习率的影响,此处设置
学习率为 lr = [0.01, 0.1, 0.6, 0.9]
冲量依次为 momentum = [0.0, 0.1, 0.5, 0.9]
起始位置为 x_start = -5
迭代周期为 6
测试以及绘图代码如下:
https://uqer.io/community/share/58204d90228e5ba8f357140a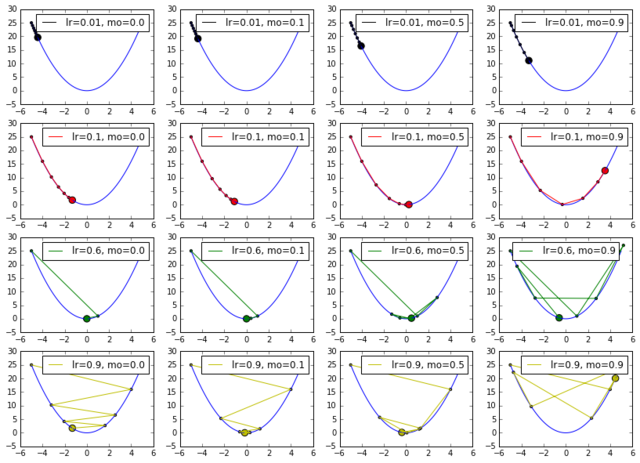
运行结果如上图所示,每一行的图的学习率 lr 一样,每一列的 momentum 一样,最左列为不使用 momentum 时的收敛情况。
从第一行可看出:在学习率较小的时候,适当的 momentum 能够起到一个加速收敛速度的作用。
从第四行可看出:在学习率较大的时候,适当的 momentum 能够起到一个减小收敛时震荡幅度的作用。
这是一个专为移动设备优化的页面(即为了让你能够在 Google 搜索结果里秒开这个页面),如果你希望参与 V2EX 社区的讨论,你可以继续到 V2EX 上打开本讨论主题的完整版本。
https://www.v2ex.com/t/324763
V2EX 是创意工作者们的社区,是一个分享自己正在做的有趣事物、交流想法,可以遇见新朋友甚至新机会的地方。
V2EX is a community of developers, designers and creative people.







