比如我们以一台服务器为单位,每分钟的告警分系统和网络统一来处理。(当然可以以收件人,业务关联为单位)。对于传染型的故障,比如网站报了 500 错误,那么我们发现 500 错误的时候,在告警的时候是不是可以让他去错误日志里收集关于相同 IP 的 error ,一起发送
所以我们未来要做的就是要收集告警信息进行自动化处理,而不是通知运维上线处理。
我们要脱离那种每天等着告警信息去处理故障,要主动出击,不要等到故障了再去处理,及时处理好了,那么时间成本也是很高的。我们在做监控的时候需要 考虑很多不可控的因素。在写代码的时候 要首先考虑异常状态,否则造成二次故障,是我们不愿意看到的。当故障 IP 2 小时内不丢包,我们就把他去掉。下次切换的时候就可以用到,反之亦然。这里提示下,对于这种时间周期可以使用 redis , expire 指定他的 ttl
给大家一张图来理解下告警信息的分类
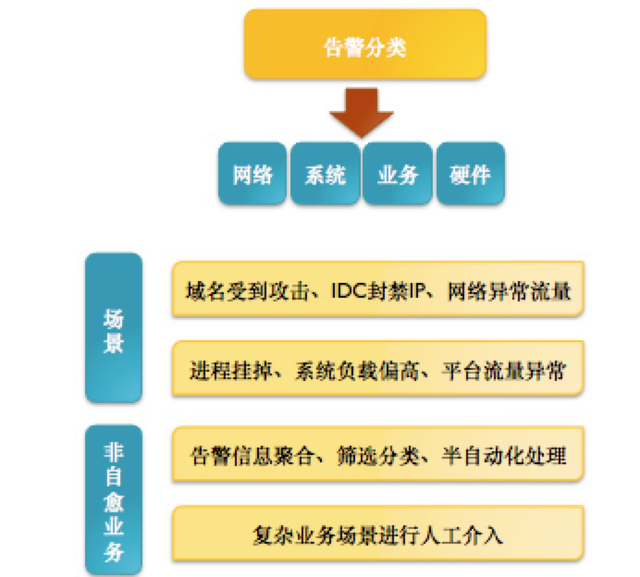
我们要做到能自动化的尽量自动化,不能够自动化的我们要让他半自动。人工处理是最后的方案,因为是人就会犯错,尤其在业务出现异常,操作都是不可控的。推荐大家试试监控宝:
http://www.jiankongbao.com



