2017-03-16 18:14:33 +08:00

从今天开始一步步完成 Python 日记计划,和 Python 相关的收录待用,修改转载已取得腾讯云授权
在以上两篇文章中我们已经在腾讯云服务器上搭建好了 Python 爬虫环境了,下一步就是在云服务器上爬上我们的爬虫,抓取我们想要的数据: [腾讯云的 1001 种玩法] 云服务器搭建 Python 环境 [腾讯云的 1001 种玩法] 云服务器搭建 Python 爬虫环境
今天我们要抓去的目标网站是,国内最大的年轻人潮流文化娱乐社区:哔哩哔哩 - ( ゜- ゜)つロ 干杯~ - bilibili B 站自建站以来已经收纳了大约六百多万的视频,那么今天我们就写一个爬虫去征服这六百多万条视频信息。
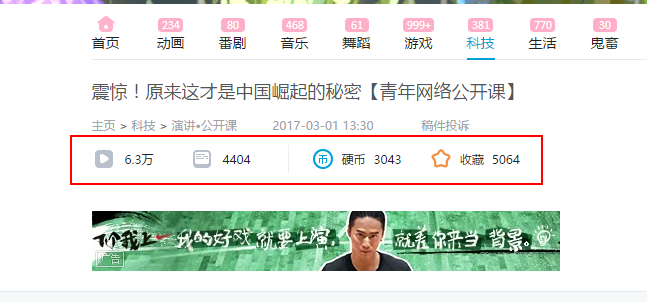
我们想抓取的就是上面的播放次数、评论数量、硬币数量以及收藏数量,接着我们开始。
1 、先分析
首先第一步这些数据在哪里?我们第一个想到的就是在网页源码里面,于是我们查看源码,搜索相关信息。

遗憾的是我们会发现,信息并不在源码中;紧接着我们打开 chrome 开发者工具查看请求信息。
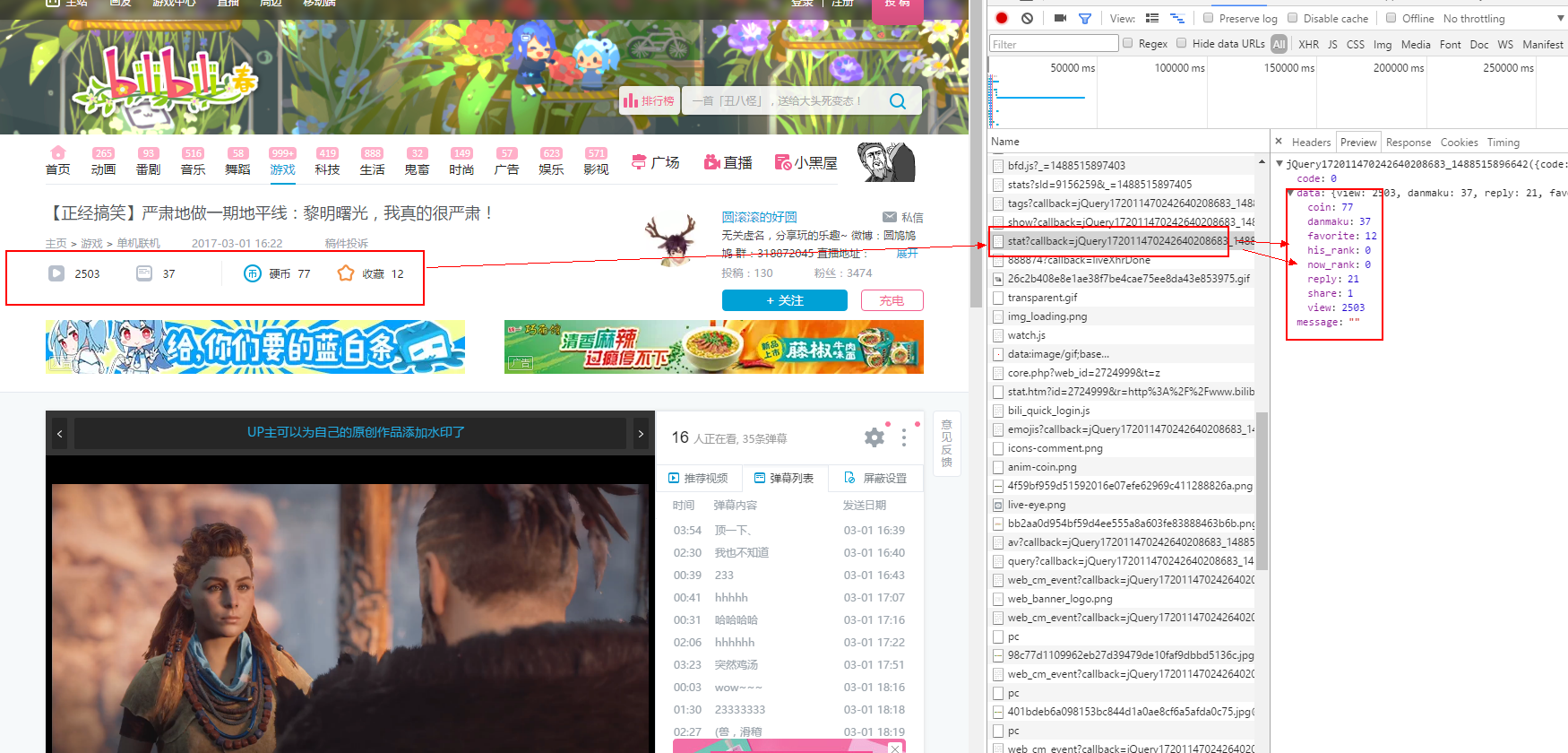
我们可以对以上的 url 进行修剪,删除一些不是必须要的参数。我们先观察这个 url , aid 是这个视频的 id 唯一标识不能删除,我们可以先把其余的参数都删掉试试看,如果不成功我们在一一加参数测试。
http://api.bilibili.com/archive_stat/stat?aid=8904657
显然,删除了非必要参数之后对内容毫无影响,所以我们只需要知道每个视频的 aid 就可以抓取所有的视频信息了。那么 B 站的视频 aid 是怎么编号的呢?我们可以多观察以下 aid 会发现这个 aid 是一个自动增长的主键,从 1 开始递增。于是我们代码思路有就了。
2 、写代码
使用 requests 库来请求获取数据,并使用 Python 的内置库 Json 来提取数据。
现在已经可以抓取单个视频信息了,让你的小爬虫遍历整个 B 站的视频。
现在你只需要把你的爬虫一直开在服务器上就 ok 了。
原文来自: https://www.qcloud.com/community/user/635207001488413960
这是一个专为移动设备优化的页面(即为了让你能够在 Google 搜索结果里秒开这个页面),如果你希望参与 V2EX 社区的讨论,你可以继续到 V2EX 上打开本讨论主题的完整版本。
V2EX 是创意工作者们的社区,是一个分享自己正在做的有趣事物、交流想法,可以遇见新朋友甚至新机会的地方。
V2EX is a community of developers, designers and creative people.