2017-06-05 18:20:32 +08:00

Mesos 1. 2 . 0 即将发布,这个版本会有一个非常全面的健康检查相关功能。
但是你知道吗,数人云Mesos 开源调度器Swan在设计之初就已经意识到 Marathon 健康检查的问题。同时在接口上兼容了 Marathon,方便用户从 Marathon 迁移任务到 Swan 上时做到无痛。
点击上面蓝色 Swan 即可体验,欢迎 Star & Fork。
言归正传,我们还是来说一说 Mesos 1. 2. 0 的健康检查。
即将发布的 Mesos 1.2.0 中包含了一个非常全面的健康检查相关功能,即 Mesos 原生健康检查。严格意义上来讲,自 Mesos 0.20 开始开始就已经内置了对健康检查的支持,不过一直被标记为实验版本,至此 1.2.0 版本的发布,才考虑将此功能标记为稳定版。
为什么是“原生支持”?第一,这样听起来很酷;第二,因为健康检查是由 Mesos-Executor 来执行并且通过 Mesos API 表现出来( HTTP API 和 Protobuf )。
本文将分两部分来说明健康检查的功能:
第一部分,将讨论一些关于设计决策和实现细节相关的内容。
第二部分,会着重说明一下关于配置可扩展性的健康检查以及 Marathon 的健康检查。
如果应用异常退出,那么一定是有程序内部哪里出了问题。Mesos 会检测且上报这样的错误到调度的 Framework。但是,并不是所有的应用都涉及成是“ fail fast ”,有可能出了问题以后还继续执行,不过展现出的行为已经出错了。如何检测这样的程序问题是很难的,为了解决这样的问题,一些 Mesos Framework 比如 Marathon 或者 Aurora 实现了自己的健康检查模块。
下面来看一下 Marathon 是如何解决 HTTP 的健康检查的。用户在应用的描述文件中指明需要 HTTP 层面的健康监测,Marathon 根据用户的请求分析出实例的具体运行时 IP 和端口,定时发送 HTTP 请求到用户的应用上,分析返回结果。Marathon 的这种直观易用的健康检查方式存在了两年以上了。过去两年中也暴露了一些问题,比如:
Marathon 的健康检查方式仅限于 Marathon 自己,Mesos 层面没有支持,导致用户使用其他 Framework 时会产生兼容性的问题。
健康检查的检测进程和实例进程不在同一主机上,增加了额外的网络负担,由于网络环境的不稳定可能导致健康检查的错误结果。
Marathon 作为一个调度框架来说,同时做健康检查可能引起过高的 IO 负载。
这就是为什么要实现 Mesos 层面健康检查的原因,一个更统一而且可扩展的解决方案。
其初衷是解放 Framework 开发者设计自己健康检查 API,在所有调度器和执行器过程中定义健康检查的保准化,设计了针对 TCP、HTTP、COMMAND 三种健康检查的方式,每种都有不同的参数需要用户提供。
统一的 API 只是一半的工作,大家知道不同的 Executor 下执行健康检查的方式区别很大,兼容所有 executor 的健康检查是非常繁重的工作。为此,其设计了一套独立的健康检查模块来帮助 Framework 开发者减轻工作量。
内置的几种 Executor 也使用了这一套新的健康检查模块,自定义的 Executor 也同时可以使用,不管 executor 是进程、或线程还是其他。
健康检查模块最主要的工作是进入到合适的实例网络 namespace 里面,这样健康检查的执行环境就一直是 127.0.0.1,尽可能离要检查的实例网络近一些。而且越过了比如 overlay 网络,或者负载均衡等。这样意味着当网络不稳定时也不会影响到健康检查。
因 Mesos 原生的健康检查是执行在不同的 Agent 之上,所有健康检查的负载分布在不同机器上,这样的话横向扩展就不会增加 Mesos Master 节点的压力。
每次健康检查时都有单独的命令在 Agent 上执行。
凡事有两面性,Mesos 原生健康检查会消耗 Agent 上的资源,另外,fork-execing (发起自进程的一种办法)然后进入实例的 namespace 会有不小的消耗,下面会详细地说明损耗。
因为进入到进程的 namespace 执行,所以健康检查的进程消耗会计算到实例的损耗里面,故而前期做资源消耗计算时要考虑健康检查。
健康检查程序是和实例运行在相同的 cgroup 和 namespace 里面,所以健康检查程序的执行会受到实例的影响,比如有可能健康检查程序由于实例过于消耗资源而得不到执行。即使设置了 CFS 标示。由于健康检查是检查本地 127.0.0.1 的网卡上,所以健康检查的安全性很高,不过同时要求实例应用需要监听 loopback 上,但由于生产环境 Marathon 之类通过负载均衡把服务暴露出去,所以实例要在保证健康检查的同时需要和负载均衡可达到的任务,需监听更多网卡。
通过一些实验,会发现 Marathon 的 HTTP 健康检查在探测 1900 个实例以后开始出现失败。
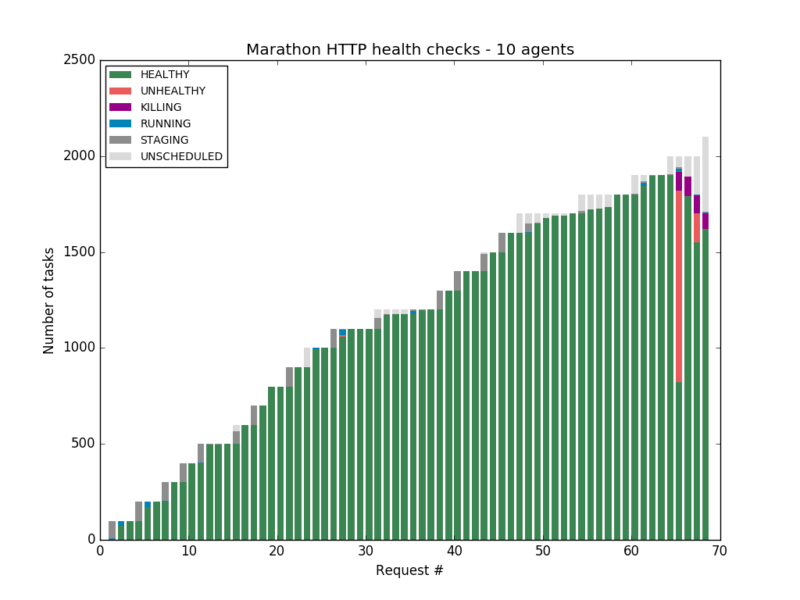
tcp 情况会好一些,不过 3700 个实例之后 Marathon 开始变得完全不动。
而 Mesos 原生健康检查完全克服了这个问题, 对 Master 没有任何压力。
本文作者在此 blog 的第二部分中,详细描述了对比试验的过程:在 AWS 上搭建 Mesos、Marathon 的集群,通过 Python 脚本分别测试了 Marathon 的 HTTP,TCP 健康检查, 以及 Mesos 内置的 HTTP 和 TCP 健康检查。
通过对比实验发现,Marathon 的健康检查在实例达到一定数量之后都有着严重的性能瓶颈,而 Mesos 原生健康检查没有此类瓶颈。
原文作者:Gaston Kleiman
这是一个专为移动设备优化的页面(即为了让你能够在 Google 搜索结果里秒开这个页面),如果你希望参与 V2EX 社区的讨论,你可以继续到 V2EX 上打开本讨论主题的完整版本。
V2EX 是创意工作者们的社区,是一个分享自己正在做的有趣事物、交流想法,可以遇见新朋友甚至新机会的地方。
V2EX is a community of developers, designers and creative people.