2017-11-10 12:50:37 +08:00

从现在的结果来看,分词的版本( https://www.v2ex.com/t/404977#reply6 )准确率稍微高一点。
项目地址: https://github.com/fendouai/Chinese-Text-Classification
jieba 分词的版本在 master 分支,不分词的版本在 dev 分支。
训练过程:
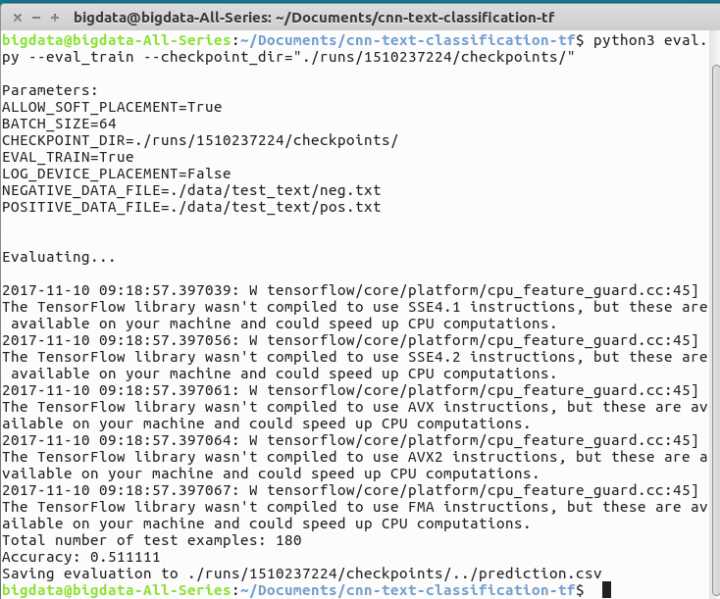
模型评估:
实验三,准备换一下数据集,用这里的数据集来跑这个模型: https://zhuanlan.zhihu.com/p/30736422



这是一个专为移动设备优化的页面(即为了让你能够在 Google 搜索结果里秒开这个页面),如果你希望参与 V2EX 社区的讨论,你可以继续到 V2EX 上打开本讨论主题的完整版本。
V2EX 是创意工作者们的社区,是一个分享自己正在做的有趣事物、交流想法,可以遇见新朋友甚至新机会的地方。
V2EX is a community of developers, designers and creative people.
