2019-11-26 21:00:31 +08:00

这是我们的一个大三课程的课程设计,我自认为做的还可以,就发上来,请各位看官点评一下,谢谢。
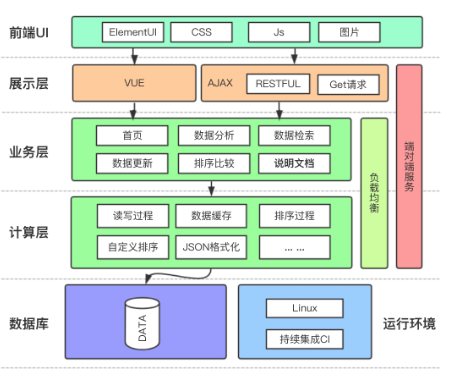
其实对于特定数据分布的排序,我们是可以通过看数据知道一些规律的:
比如 LINKID 字段,可以认为是均匀分布,因为是自增的关键字。对于这个字段的排序就比较适合桶排序(在 ID 不是特别多的情况下)。
再比如数量和番号字段,他们都是 20 以下的数,可以用较少的桶,但是每个桶内存放的 id 超过一个,就需要链表或者是预分配足够大的数组存,一个直接的改进思路就是通过两次扫描,第一次获取每个桶的元素数量,第二次就可以直接计算出这个元素的在排序好数组中的下标,然后直接做赋值操作即可。
对于字符串的字段,很多道路段共享着一个道路名称。我们可以结合倒排索引和桶排序的方法来做。
下图为在 LinkID 场景下的排序速度,可以看出改进方法在 N>25000 时,算法运行时间显著的小于最快的 BucketSort。在实际场景之下,N 往往大于 25000。
下图为在道路番号场景下的排序速度,效果还是不错的。
https://github.com/chengsyuan/MapSystem
顺便包装到了 Docker 里面,就当练手了。用了 Daocloud 做持续集成。我觉得 Daocloud 现在没以前好用了。

这是一个专为移动设备优化的页面(即为了让你能够在 Google 搜索结果里秒开这个页面),如果你希望参与 V2EX 社区的讨论,你可以继续到 V2EX 上打开本讨论主题的完整版本。
V2EX 是创意工作者们的社区,是一个分享自己正在做的有趣事物、交流想法,可以遇见新朋友甚至新机会的地方。
V2EX is a community of developers, designers and creative people.