2020-04-01 17:50:46 +08:00

先说情况在最后再提问题。
比如这个站: https://zidian.51240.com/
一开始是, 三个分类
拼音查字 部首查字 笔画数查字

然后分别点击进去后 是一类分类

然后再点进去 又是一类分类
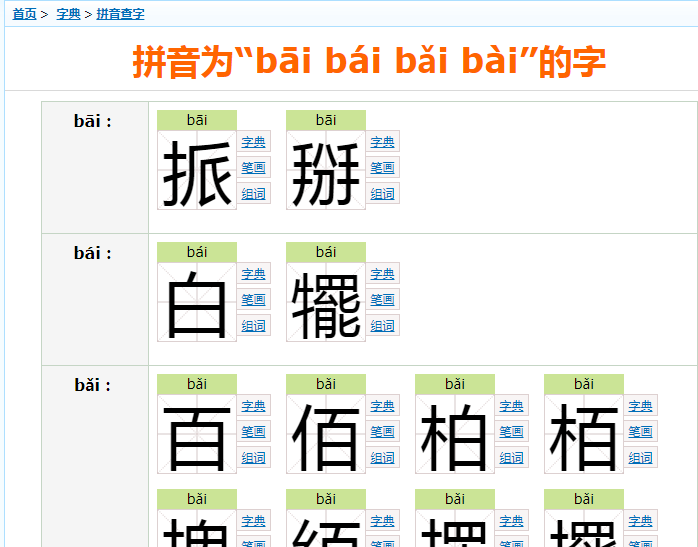
然后再 点进 字典 进去后才是字的具体含义
点进 组词 进去后 是这个字的各种组词
按 拼音 部首 笔画数 查到字后
在字里面又有对应的词,而且这些词都带链接上的,点进去后又会有详情的词。
没什么经历。感觉这些对应关系太复杂了
如果想用 python 采一下,存在 mysql 里不知道怎么设置数据库对应的关系, 用 django 模型设计怎么实现或者最接近这些关系?
不知道有什么好的思路?
这是一个专为移动设备优化的页面(即为了让你能够在 Google 搜索结果里秒开这个页面),如果你希望参与 V2EX 社区的讨论,你可以继续到 V2EX 上打开本讨论主题的完整版本。
V2EX 是创意工作者们的社区,是一个分享自己正在做的有趣事物、交流想法,可以遇见新朋友甚至新机会的地方。
V2EX is a community of developers, designers and creative people.