2021-06-17 19:08:55 +08:00

本文首发于 Nebula Graph 公众号 NebulaGraphCommunity,Follow 看大厂图数据库技术实践。

Nebula 2.0 中已经支持了基于外部全文搜索引擎的文本查询功能。在介绍这个功能前,我们先简单回顾一下 Nebula Graph 的架构设计和存储模型,更易于下边章节的描述。
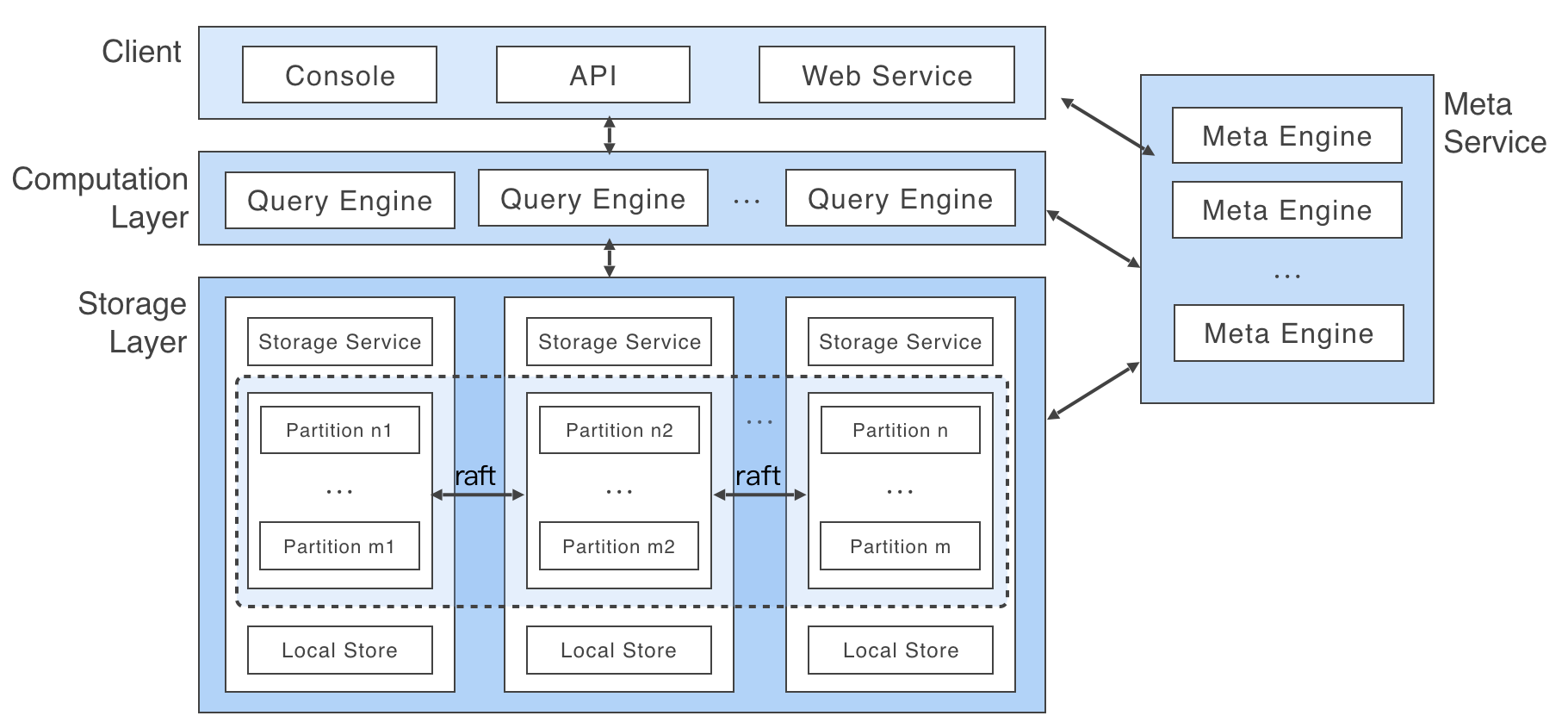
如图所示,Storage Service 共有三层,最底层是 Store Engine,它是一个单机版 local store engine,提供了对本地数据的get/put/scan/delete操作,相关的接口放在 KVStore / KVEngine.h 文件里面,用户完全可以根据自己的需求定制开发相关 local store plugin,目前 Nebula 提供了基于 RocksDB 实现的 Store Engine 。
在 local store engine 之上,便是我们的 Consensus 层,实现了 Multi Group Raft,每一个 Partition 都对应了一组 Raft Group,这里的 Partition 便是我们的数据分片。目前 Nebula 的分片策略采用了静态 Hash的方式,具体按照什么方式进行 Hash,在下一个章节 schema 里会提及。用户在创建 SPACE 时需指定 Partition 数,Partition 数量一旦设置便不可更改,一般来讲,Partition 数目要能满足业务将来的扩容需求。
在 Consensus 层上面也就是 Storage Service 的最上层,便是我们的 Storage Interfaces,这一层定义了一系列和图相关的 API 。 这些 API 请求会在这一层被翻译成一组针对相应 Partition 的 KV 操作。正是这一层的存在,使得我们的存储服务变成了真正的图存储,否则,Storage Service 只是一个 KV 存储罢了。而 Nebula 没把 KV 作为一个服务单独提出,其最主要的原因便是图查询过程中会涉及到大量计算,这些计算往往需要使用图的 Schema,而 KV 层是没有数据 Schema 概念,这样设计会比较容易实现计算下推。
Nebula Graph 在 2.0 中,对存储结构进行了改进,其包含点、边和索引的存储结构,接下来我们将简单回顾一下 2.0 的存储结构。通过存储结构的解释,大家基本也可以简单了解 Nebula Graph 的数据和索引扫描原理。
Nebula 数据的存储包含“点”和“边”的存储,“点” 和 “边” 的存储均是基于 KV 模型存储,这里我们主要介绍其 Key 的存储结构,其结构如下所示
Type: 1 个字节,用来表示 key 的类型,当前的类型有 vertex 、edge 、index 、system 等。PartID: 3 个字节,用来表示数据分片 partition,此字段主要用于 partition 重新分布( balance )时方便根据前缀扫描整个 partition 数据VertexID: n 个字节, 出边里面用来表示源点的 ID, 入边里面表示目标点的 ID 。Edge Type: 4 个字节, 用来表示这条边的类型,如果大于 0 表示出边,小于 0 表示入边。Rank: 8 个字节,用来处理同一种类型的边存在多条的情况。用户可以根据自己的需求进行设置,这个字段可存放交易时间、交易流水号、或某个排序权重。PlaceHolder: 1 个字节,对用户不可见,未来实现分布式做事务的时候使用。TagID:4 个字节,用来表示 tag 的类型。| Type (1 byte) | PartID (3 bytes) | VertexID (n bytes) | TagID (4 bytes) |
|---|
| Type (1 byte) | PartID (3 bytes) | VertexID (n bytes) | EdgeType (4 bytes) | Rank (8 bytes) | VertexID (n bytes) | PlaceHolder (1 byte) |
|---|
| Type (1 byte) | PartID (3 bytes) | IndexID (4 bytes) | props binary (n bytes) | nullable bitset (2 bytes) | VertexID (n bytes) |
|---|
| Type (1 byte) | PartID (3 bytes) | IndexID (4 bytes) | props binary (n bytes) | nullable bitset (2 bytes) | VertexID (n bytes) | Rank (8 bytes) | VertexID (n bytes) |
|---|
由以上的存储结构推理可以看出,如果我们想要对某个 prop 字段进行文本的模糊查询,都需要进行一个 full table scan 或 full index scan,然后逐行过滤,由此看来,查询性能将会大幅下降,数据量大的情况下,很有可能还没扫描完毕就出现内存溢出的情况。另外,如果将 Nebula 索引的存储模型设计为适合文本搜索的倒排索引模型,那将背离 Nebula 索引初始的设计原则。经过一番调研和讨论,所谓术业有专攻,文本搜索的工作还是交给外部的第三方全文搜索引擎来做,在保证查询性能的基础上,同时也降低了 Nebula 内核的开发成本。
2.0 版本我们只对 LOOKUP 支持了文本搜索功能。也就是说基于 Nebula 的内部索引,借助第三方全文搜索引擎来完成 LOOKUP 的文本搜索功能。对于第三方全文引擎来说,目前只使用了一些基本的数据导入、查询等功能。如果是要做一些复杂的、纯文本的查询计算的话,Nebula 目前的功能还有待完善和改进,期待广大的社区用户提出宝贵的建议。目前所支持的文本搜索表达式如下:
这里所说的性能,指数据同步性能和查询性能。
LOOKUP 中通过第三方全文引擎支持了文本搜索,不可避免的性能会慢于 Nebula 原生的索引扫描,有时甚至第三方全文引擎自身的查询都会很慢,此时我们需要有一个时效机制来保证查询性能。即 LIMIT 和 TIMEOUT,将在下列章节中详细介绍。| 名称 | 说明 |
|---|---|
| Tag | 用于点上的属性结构,一个 vertex 可以附加多个 tag,以 tagId 标示。 |
| Edge | 类似于 tag,edge 是用于边上的属性结构,以 edgetype 标示。 |
| Property | tag 或 edge 上的属性值,其数据类型由 tag 或 edge 的结构确定。 |
| Partition | Nebula Graph 的最小逻辑存储单元,一个 Storage Engine 可包含多个 partition 。Partition 分为 leader 和 follower 的角色,raftex 保证了 leader 和 follower 之间的数据一致性。 |
| Graph space | 每个 graph space 是一个独立的业务 graph 单元,每个 graph space 有其独立的 tag 和 edge 集合。一个 Nebula Graph 集群中可包含多个 graph space 。 |
| Index | 下文中出现的 index 指 Nebula Graph 中点和边上的属性索引。其数据类型依赖于 tag 或 edge 。 |
| TagIndex | 基于 tag 创建的索引,一个 tag 可以创建多个索引。因暂不支持复合索引,因此一个索引只可以基于一个 tag 。 |
| EdgeIndex | 基于 edge 创建的索引。同样,一个 edge 可以创建多个索引,但一个索引只可以基于一个 edge 。 |
| Scan Policy | index 的扫描策略,往往一条查询语句可以有多种索引的扫描方式,但具体使用哪种扫描方式需要 scan policy 来决定。 |
| Optimizer | 对查询条件进行优化,例如对 WHERE 子句的表达式树进行子表达式节点的排序、分裂、合并等。其目的是获取更高的查询效率。 |
目前我们兼容的第三方全文搜索引擎是 ElasticSearch,此章节中主要围绕 ElasticSearch 来进行描述。
| partId(10 bytes) | schemaId(10 bytes) | encoded_columnName(32 bytes) | encoded_val(max 344 bytes) |
|---|
Leader & Listener
上边的章节中简单介绍了数据异步同步的逻辑,此逻辑将在本章节中详细介绍。介绍之前,先让我们认识一下 Nebula 的 Leader 和 Listener 。
nebula-stoage.conf决定。nebula-stoage-listener.conf 决定。Listener 作为一个监听者,会被动的接收来自于 Leader 的 WAL,并定时的将 WAL 进行解析,并调用第三方全文引擎的数据插入 API 将数据同步到第三方全文搜索引擎中。对于 ElasticSearch,Nebula 支持 PUT 和 BULK 接口。接下来我们介绍一下数据同步逻辑:
INSERT 请求发送到相关 Partition 的 LeaderINSERT 请求,并将 WAL 同步到 Listener 中PUT 或 BULK 接口写入到 ElasticSearch 中。在以上步骤中,如果因为 ElasticSearch 集群挂掉,或 Listener 进程挂掉,则停止 WAL 同步。当系统恢复后,会接着上次成功的 Log ID 继续进行数据同步。在这里有一个建议,需要 DBA 通过外部监控工具实时监控 ES 的运行状态,如果 ES 长期处于无效状态,会导致 Listener 的 log 日志暴涨,并且无法做正常的查询操作。
由上图可知,其文本搜索的关键步骤是 “Send Fulltext Scan Request” → "Fulltext Cluster" → "Collect Constant Values" → "IndexScan Optimizer"。
C1 == "A1" OR C1 == "A2"。LIMIT 和 TIMEOUT 机制,实时中断 ES 端的查询。对于 ES 集群的部署,这里不再详细介绍,相信大家都很熟悉了。这里需要说明的是,当 ES 集群启动成功后,我们需要对 ES 集群创建一个通用的 template,其结构如下:
{
"template": "nebula*",
"settings": {
"index": {
"number_of_shards": 3,
"number_of_replicas": 1
}
},
"mappings": {
"properties" : {
"tag_id" : { "type" : "long" },
"column_id" : { "type" : "text" },
"value" :{ "type" : "keyword"}
}
}
}
nebula-storaged-listener.conf./bin/nebula-storaged --flagfile ${listener_config_path}/nebula-storaged-listener.confnebula> SIGN IN TEXT SERVICE (127.0.0.1:9200);
nebula> SHOW TEXT SEARCH CLIENTS;
+-------------+------+
| Host | Port |
+-------------+------+
| "127.0.0.1" | 9200 |
+-------------+------+
| "127.0.0.1" | 9200 |
+-------------+------+
| "127.0.0.1" | 9200 |
+-------------+------+
CREATE SPACE basketballplayer (partition_num=3,replica_factor=1, vid_type=fixed_string(30));
USE basketballplayer;
nebula> ADD LISTENER ELASTICSEARCH 192.168.8.5:46780,192.168.8.6:46780;
nebula> SHOW LISTENER;
+--------+-----------------+-----------------------+----------+
| PartId | Type | Host | Status |
+--------+-----------------+-----------------------+----------+
| 1 | "ELASTICSEARCH" | "[192.168.8.5:46780]" | "ONLINE" |
+--------+-----------------+-----------------------+----------+
| 2 | "ELASTICSEARCH" | "[192.168.8.5:46780]" | "ONLINE" |
+--------+-----------------+-----------------------+----------+
| 3 | "ELASTICSEARCH" | "[192.168.8.5:46780]" | "ONLINE" |
+--------+-----------------+-----------------------+----------+
此时建议字段 “name” 的长度应该小于 256,如果业务允许,建议 player 中字段 name 的类型定义为 fixed_string 类型,其长度小于 256 。
nebula> CREATE TAG player(name string, age int);
nebula> CREATE TAG INDEX name ON player(name(20));
nebula> INSERT VERTEX player(name, age) VALUES \
"Russell Westbrook": ("Russell Westbrook", 30), \
"Chris Paul": ("Chris Paul", 33),\
"Boris Diaw": ("Boris Diaw", 36),\
"David West": ("David West", 38),\
"Danny Green": ("Danny Green", 31),\
"Tim Duncan": ("Tim Duncan", 42),\
"James Harden": ("James Harden", 29),\
"Tony Parker": ("Tony Parker", 36),\
"Aron Baynes": ("Aron Baynes", 32),\
"Ben Simmons": ("Ben Simmons", 22),\
"Blake Griffin": ("Blake Griffin", 30);
nebula> LOOKUP ON player WHERE PREFIX(player.name, "B");
+-----------------+
| _vid |
+-----------------+
| "Boris Diaw" |
+-----------------+
| "Ben Simmons" |
+-----------------+
| "Blake Griffin" |
+-----------------+
对于系统环境的搭建过程中,可能某个步骤错误导致功能无法正常运行,在之前的用户反馈中,我总结了三类可能发生的错误,对分析和解决问题的技巧概况如下
IP:Port 不和已有的 nebula-storaged 冲突IP:Port 正确,这个要和 nebula-storaged 中保持一致nebula-storaged-listener.conf 配置文件中 –listener_path 的目录下是否有文件。UPDATE CONFIGS storage:v=3),并关注 log 中 CURL 命令是否执行成功,如果有错误,可能是 ES 配置或 ES 版本兼容性错误UPDATE CONFIGS graph:v=3),关注 graph 的 log,检查 CURL 命令是什么原因执行失败交流图数据库技术?加入 Nebula 交流群请先填写下你的 Nebula 名片,Nebula 小助手会拉你进群~~
想要和其他大厂交流图数据库技术吗? NUC 2021 大会等你来交流:NUC 2021 报名传送门
这是一个专为移动设备优化的页面(即为了让你能够在 Google 搜索结果里秒开这个页面),如果你希望参与 V2EX 社区的讨论,你可以继续到 V2EX 上打开本讨论主题的完整版本。
V2EX 是创意工作者们的社区,是一个分享自己正在做的有趣事物、交流想法,可以遇见新朋友甚至新机会的地方。
V2EX is a community of developers, designers and creative people.
{kind=link}