2022-02-07 19:55:55 +08:00

一组歌曲的路径,已经从文件系统导入到 mongodb 里。
后端 python 从 mongodb 读出来供 web js 读取。
发现有几首歌放不出,看后台 nginx 的日志是 404 ,找不到文件。
F12 把路径拷出来,肉眼看路径是对的,但是 urlencode 后和正确的确是有不同,不知道为啥?
urlencode ,第一行可以读取,第二行报 404.

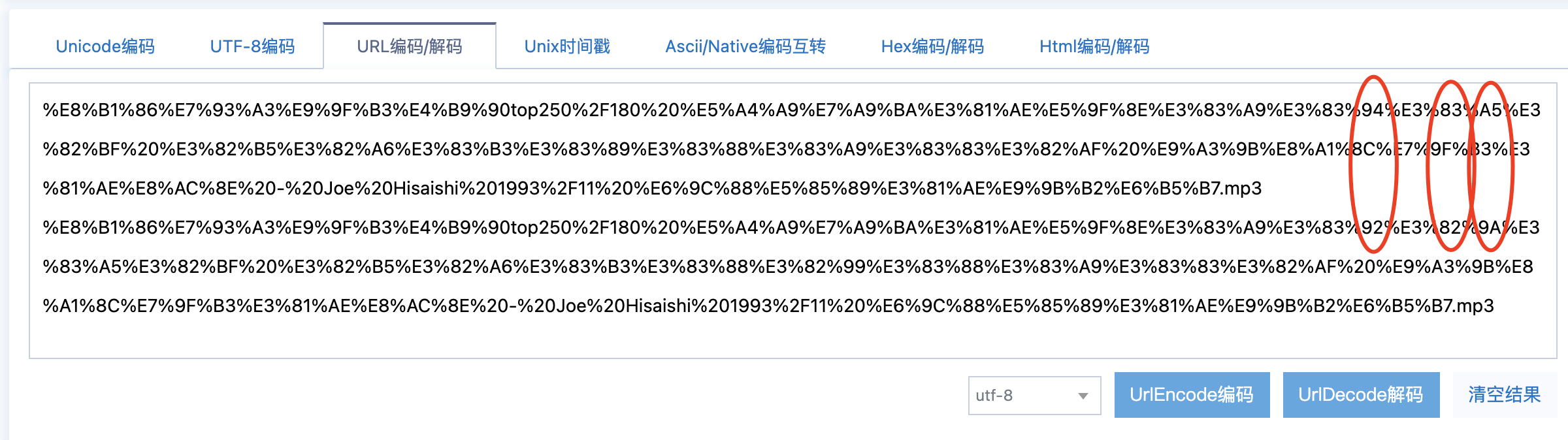
猜测是 unicode 编码的问题,但是不确定怎么解决。




这是一个专为移动设备优化的页面(即为了让你能够在 Google 搜索结果里秒开这个页面),如果你希望参与 V2EX 社区的讨论,你可以继续到 V2EX 上打开本讨论主题的完整版本。
V2EX 是创意工作者们的社区,是一个分享自己正在做的有趣事物、交流想法,可以遇见新朋友甚至新机会的地方。
V2EX is a community of developers, designers and creative people.
