2022-09-25 10:06:33 +08:00

把 Tesseract.js 包装成直接能用的网站了,全程在你的浏览器中识别,不需要上传。
个人主要用来识别测试反馈的截图, 抓里面的 TraceID 和接口调用参数,使用体验还不错。
对英文的识别效果还可以,中文的有点菜。
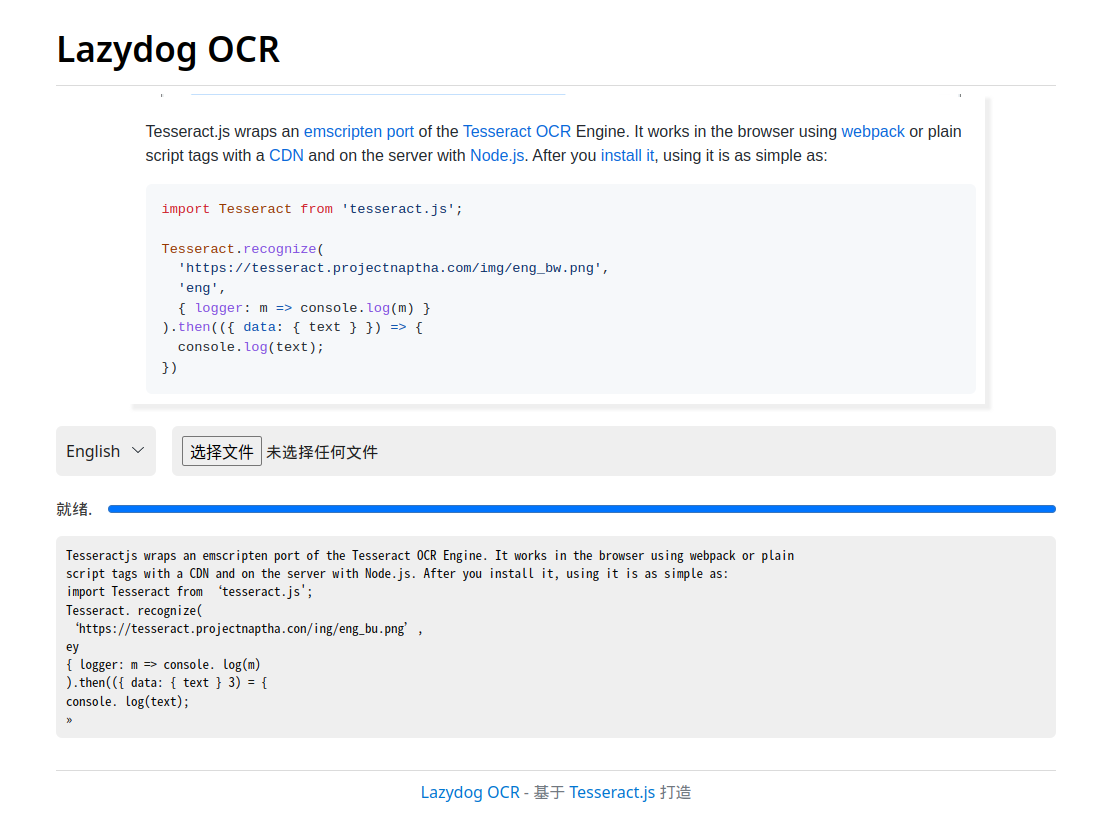
在线体验版: https://ocr.zjyl1994.com/
Github: https://github.com/zjyl1994/lazydogocr
注意:需要你的浏览器支持 WASM ,在线体验版部署在 CF Pages 上,加载训练数据需要 10 多 MB ,可能不会太快。








这是一个专为移动设备优化的页面(即为了让你能够在 Google 搜索结果里秒开这个页面),如果你希望参与 V2EX 社区的讨论,你可以继续到 V2EX 上打开本讨论主题的完整版本。
V2EX 是创意工作者们的社区,是一个分享自己正在做的有趣事物、交流想法,可以遇见新朋友甚至新机会的地方。
V2EX is a community of developers, designers and creative people.
