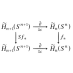@
lsww 题主不知入行多久,目前在做什么事情,直接点说,这个问题问的并不清楚:
首先:AI 卡可以理解为异构的 AI 计算加速卡。
如果是:`从操作系统角度理解其工作原理`,那么是不是在问:
`异构计算加速平台的计算调度在 OS 层面做哪些工作?`,那对用户来说其实就是:PCIe ,DMA 这些数据搬运相关的事情,其他的比如中断这些,都是厂商软件栈的事情了。
如果是:`AI 加速卡的工作原理`,那么是不是在问:
`AI 加速卡如何做到高效的并行计算,来提高计算效率的?`,那就从怎么做 GEMM 加速,并行计算,这些看起,#2 @
kakalala 提的 opencl 是理解并行计算的一个路径,还可以去看看 cuda 的文档,从硬件架构到 SIMT 到 Warp 都有图文并茂的解释。
另外,从技术角度,AI 训练和 AI 推理,看起来差不多,但是从操作系统来看,两者之间的软件差异其实非常大:
推理简单,把主机代码和设备代码确定了,workload 丢给 AI 卡,等回调,主机代码继续干后处理完事。
训练复杂,单机多卡,多机多卡集群,涉及到分布式计算,通讯,模型并行 /数据并行 /混合并行,等一大堆东西。