2020-08-17 09:27:02 +08:00

strsim 是 golang 实现的字符串相识度库,后端集成多种算法,主要解决现有相似度库不能很好的处理中文
![]()
![]()
https://github.com/antlabs/strsim
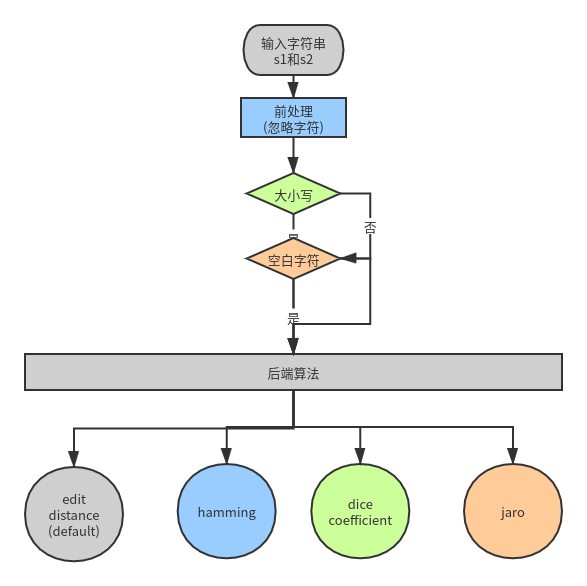
strsim.Compare("中国人", "中")
// -> 0.333333
strsim.FindBestMatchOne("海刘", []string{"白日依山尽", "黄河入海流", "欲穷千里目", "更上一层楼"})
strsim.Compare("abc", "ab")
// -> 0.6666666666666667
strsim.Compare("abc", "ab", strsim.DiceCoefficient(1))
//-> 0.6666666666666666
strsim.Compare("abc", "ab", strsim.Jaro())
strsim.Compare("abc", "ab", strsim.Hamming())
这是一个专为移动设备优化的页面(即为了让你能够在 Google 搜索结果里秒开这个页面),如果你希望参与 V2EX 社区的讨论,你可以继续到 V2EX 上打开本讨论主题的完整版本。
V2EX 是创意工作者们的社区,是一个分享自己正在做的有趣事物、交流想法,可以遇见新朋友甚至新机会的地方。
V2EX is a community of developers, designers and creative people.