2022-02-05 18:05:17 +08:00

散列表也叫哈希表( Hash table ),是根据关键字( key )而直接访问在内存存储位置的数据结构。
在很多高级语言中都有哈希表的身影,比如在 Python 中,有一种数据结构叫做dict,中文翻译是字典,应该是基于哈希表实现的。下面以生活中查电话号码作为一个通俗的例子,讲解什么是哈希表。
可以把哈希表想象成一本按照人名首字母顺序排列电话簿,当我们要查找张三的电话号码时,可以轻易得知张三的首字母是Z。理想情况下,张三可能在电话簿 Z 开头的第一个,不理想的情况下,可能要往后再找几个人。
显然,根据姓名首字母查找电话,要比挨个查找快很多,这就是哈希表的特点,快。
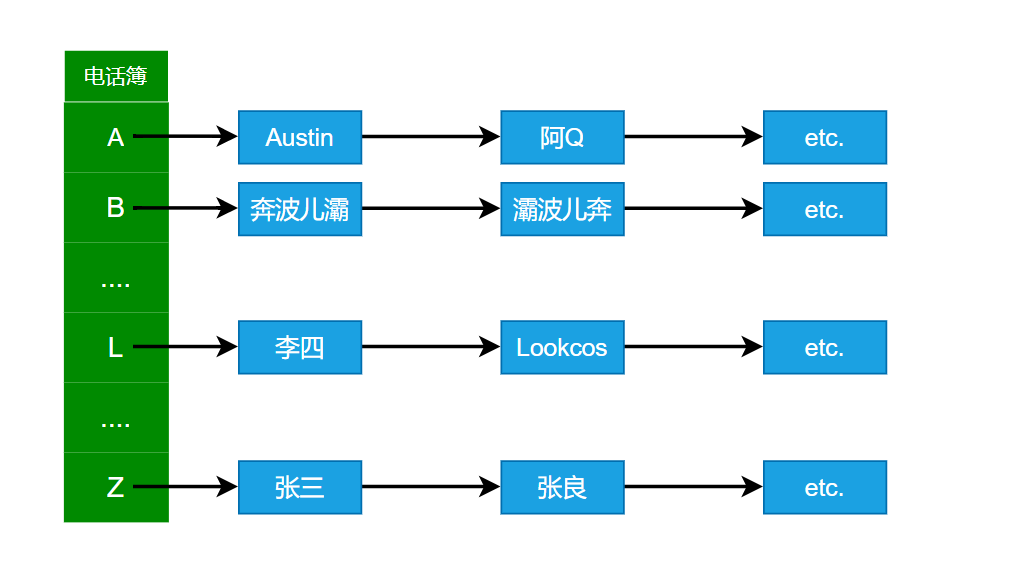
与上面例子所对应的哈希表相关名词:
对于不同关键词,经过哈希函数的计算,可能得到同一哈希地址。比如,尽管奔波儿灞(key1)和灞波儿奔(key2)是不同的名字(key1≠key2)但经过哈希函数计算得到的是同一结果(F(key1)=F(key2)=B),他们名字的首字母都是B。这种情况就叫做冲突。
解决冲突的方法有很多种,比如开放地址法和链地址法,可以根据具体使用场景来选择。一般来说,在实际项目和开发中采用链地址法比较多。
链地址法的基本思路是,把相同哈希地址的关键字放在同一个链表中。
采用链地址法解决冲突的哈希表,可以理解为数组和链表的组合。在上图中,存放首字母的是一个长度为 26 的数组,而数组的每一个元素可以看作是一个单链表,链表的数据域存放着姓名,指针域指向下一个存放相同首字母的姓名的节点。
上面我们对哈希表有了一个大概的了解,接下来设计并实现一个字典(dict),在这个字典中,可以存放键值对,也可以根据键(key)获取对应的值(val)。
hash_code),也即hash_code1 = F(key1)。然后,通过hash_code1 % SIZE得到地址(由于是在数组中的位置,这里用 Array[index]表示),取模操作是为了确保该地址在数组地址的范围内。接着,新建一个单链表节点(节点 1),指针域next为NULL,数据域存放 key1 和 val1 。最后,在 Array[index]中存放指向节点 1 的指针。 next为 NULL 。让节点 1 的next指针指向节点 2 即可解决冲突,这就是链地址法,也叫拉链法,后面的冲突,继续使用此方法解决即可。 next指针往下找,也因此,哈希算法的时间复杂度并没有 O(1)。找到数据后,返回即可。如果没数据,Array[index]=0 ,返回 NULL 。/* 字典类型 */
#define DICT_TYPE_INT 0
#define DICT_TYPE_STR 1
typedef struct dict_entry {
/* 后继节点 */
struct dict_entry *next;
/* 键 */
void *key;
/* 值 */
void *val;
}dict_entry;
typedef struct dict {
/* 哈希函数 */
unsigned int (*hash)(void *key);
/* table 数组用于存放 dict_entry 指针 */
dict_entry **table;
/* table 数组的长度 */
int size;
/* 掩码( size-1 ) */
int sizemask;
}dict;
首先看dict_entry结构体,它有三个成员,分别用来表示后继节点next指针和键与值,用以表示单链表的节点。
接着是dict结构体,用来表示字典本身。
dict_entry类型的指针。可以用 dict_entry* table[size]来辅助理解。下面是用于操作队列的函数名及其作用与复杂度
| 函数 | 作用 | 算法复杂度 |
|---|---|---|
| hash_integer | 计算整型 key 的 hash 值 | O(1) |
| hash_33 | 计算字符型 key 的 hash 值 | O(N) |
| dict_create | 创建新字典 | O(1) |
| dict_create_entry | 创建一个 dict_entry | O(1) |
| dict_put_entry | 字典插入一个 entry | O(1) |
| dict_get_value | 获取 key 对应的 val | 最佳 O(1),最坏 O(N) |
| dict_empty | 清除字典所有 entry | O(N2) |
| dict_release | 释放整个字典 | O(N2) |
/* 哈希函数(适用整数) */
static unsigned int hash_integer(void *key)
{
return (*(int *)key * 2654435769) >> 28;
}
/* 哈希函数 TIME33 算法 (适用字符串)*/
static unsigned int hash_33(void *key)
{
unsigned int hash = 0;
while (*(char *)key != 0)
{
/* 左移 5 位相当于*32 ,再+hash 则相当于*33; */
hash = (hash << 5) + hash + *(char *)key++;
}
return hash;
}
哈希函数是一种映射关系,构造哈希函数是一个数学问题,方法也很多,总的来说,要尽量减少冲突,地址尽量分布的均匀。
这里我们选择一个简单的用于计算整数哈希值的函数,以及用于计算字符串哈希的 TIME33 算法。
拓展,有一种叫MurmurHash的算法因为被 Redis 应用而广为人知, 由 Austin Appleby 在 2008 年发明, 发明者被邀到 google 工作。
/* 创建一个 dict */
dict *dict_create(int type)
{
dict *dict = (struct dict *)malloc(sizeof(struct dict));
if(dict == NULL) return NULL;
if(type == DICT_TYPE_INT)
dict->hash = &hash_integer;
else
dict->hash = &hash_33;
dict->size = 1024;
dict->sizemask = dict->size - 1;
/* 为数组申请内存 */
dict->table = (dict_entry **)malloc(sizeof(dict_entry *) *(dict->size));
if (dict->table == NULL) return NULL;
/* 数组元素全部置零 */
memset(dict->table, 0, sizeof(dict_entry *) * (dict->size));
return dict;
}
函数接受一个参数type,用以下面判断字典的类型,从而确定对应的 hash 函数。
然后是设置字典的大小,并为table数组申请内存,然后 table 所有元素置 0 ,代表数组该位置为空。
最后返回该新建的字典。
/* 创建一个 dict_entry */
dict_entry * dict_create_entry(void *key, void *val)
{
dict_entry * entry = (dict_entry *)malloc(sizeof(dict_entry));
if(entry == NULL) return NULL;
entry->key = key;
entry->val = val;
entry->next = NULL;
return entry;
}
创建一个dict_entry,也即是单链表的节点。这里接受俩 void 类型指针为参数,使得字典可以保存各类数据。
第一种方法:
/* 字典插入一个键值对 */
dict *dict_put_entry(dict *dict, void *key, void *val)
{
unsigned int hash = dict->hash(key);
int pos = hash & dict->sizemask;
dict_entry *entry;
entry = dict_create_entry(key, val);
entry->next = dict->table[pos];
dict->table[pos] = entry;
return dict;
}
这种方法简单有效,无论是新增、冲突或者更新操作,都以要插入的键值对生成的新结点作为对应数组位置的第一个节点。
新增和冲突,本质都是链表插入,使用此方法时,更新并非实质更新。
由于新结点作为对应数组位置的第一个节点,这就导致旧数据(相同 key 的节点)排列在新结点之后,而查询时,是从数组对应位置链表的第一个节点开始查找,所以总是先查找到新的键值对。
优缺点:
值得一提的是,Redis的 dcit 在插入键值对时,就使用了该方法。
第二种方法:
/* 字典插入一个键值对 */
dict *dict_put_entry(dict *dict, void *key, void *val)
{
unsigned int hash = dict->hash(key);
int pos = hash & dict->sizemask;
dict_entry *entry, *current;
/* 新增 */
if(dict->table[pos]==0){
printf("新增\n");
entry = dict_create_entry(key, val);
dict->table[pos] = entry;
} else {
current = dict->table[pos];
/* 首先判断第一个节点是否符合更新的情况 */
if(dict->hash(current->key) == dict->hash(key)) {
printf("更新\n");
current->val = val;
return dict;
}
/* 如果不符合,往下找,直到找到 hash 值相等的 key 的节点,则更新,
* 或者直到 next==NULL ,此时新增在链表尾部。 */
while(current->next != NULL) {
printf("往下找\n");
if(dict->hash(current->next->key) == dict->hash(key)) {
printf("更新\n");
current->next->val = val;
return dict;
};
current = current->next;
}
printf("尾部插入\n");
entry = dict_create_entry(key, val);
current->next = entry;
}
return dict;
}
这个方法可以参考上文提到的字典的设计,优点是利用内存更加少一点,缺点就是不够优雅,增加了算法复杂度。
在调试和测试时,可以将 dict->size 设置为 1 ,进而观察新增、更新、冲突等情况。
/* dict 获取值 */
void * dict_get_value(dict *dict, void *key)
{
unsigned int hash = dict->hash(key);
int pos = hash & dict->sizemask;
if(dict->table[pos]==0) return NULL;
dict_entry *current = dict->table[pos];
while (current)
{
if(dict->hash(current->key) == dict->hash(key))
return current->val;
else
current = current->next;
}
return NULL;
}
查字典就是给定一个 key ,查对应的 val 。
参考上文提到的字典的设计。
/* 清除 dict 所有 entry ,而不清除 dict 本身 */
void dict_empty(dict *dict)
{
int i;
for(i=0;i<dict->size;i++){
if(dict->table[i] != 0){
dict_entry * current, *next;
current = dict->table[i];
while (current)
{
next = current->next;
free(current);
current = next;
}
dict->table[i] = 0;
}
}
}
/* 释放 dict */
void dict_release(dict *dict)
{
dict_empty(dict);
free(dict->table);
free(dict);
}
在清除 dict 所有 entry ,而不清除 dict 本身时,只需要遍历 table 数组,发现不为 0 的元素时再遍历清除对应的链表即可。
释放 dict 的操作,只需要释放所有 entry 后,再释放 dict 本身即可。
int main()
{
/* 创建一个 key 为字符串类型的字典 */
dict * dict = dict_create(1);
char str[] = "name";
char str2[] = "Austin";
char str3[] = "Lookcos";
char str4[] = "age";
int age = 18;
/* 键值对:("Austin", "Austin") */
dict_put_entry(dict, &str2, &str2);
puts(dict_get_value(dict, &str2));
/* 键值对:("name", "Austin") */
dict_put_entry(dict, &str, &str2);
puts(dict_get_value(dict, &str));
/* 键值对:("name", "Lookcos") */
dict_put_entry(dict, &str, &str3);
puts(dict_get_value(dict, &str));
/* 键值对:("age", 18) */
dict_put_entry(dict, &str4, &age);
printf("age: %d\n", *(int *)dict_get_value(dict, &str4));
/* 字典的释放 */
dict_empty(dict);
dict_release(dict);
return 0;
}
测试时,插入键值对我使用的是第二种方法,此外我还将 dict 中的 size 设置为 1 ,这样 table 中就一个位置,方便观察插入、更新、冲突时,链表的变化。
编译输出
# gcc -fsanitize=address -fno-omit-frame-pointer -g dict.c && ./a.out
新增
Austin
尾部插入
Austin
往下找
更新
Lookcos
往下找
尾部插入
age: 18
本篇摘录于我的原创系列文章(学习笔记)
https://github.com/LookCos/learn-data-structures
本人才疏学浅,文章难免有纰漏之处,还望大佬们指点。
这是一个专为移动设备优化的页面(即为了让你能够在 Google 搜索结果里秒开这个页面),如果你希望参与 V2EX 社区的讨论,你可以继续到 V2EX 上打开本讨论主题的完整版本。
V2EX 是创意工作者们的社区,是一个分享自己正在做的有趣事物、交流想法,可以遇见新朋友甚至新机会的地方。
V2EX is a community of developers, designers and creative people.