2023-07-25 19:41:44 +08:00

ACG2vec全称为Anime Comics Games to vector 。本 repo 会持续维护一些基于二次元相关的深度学习领域实践与探索。
在线预览(目前包含文本搜索、以图搜图、文本搜图、图片分数预测):https://cheerfun.dev/acg2vec/
开源仓库:https://github.com/OysterQAQ/ACG2vec
演示页前端开源仓库:https://github.com/wewewe131/acg2vec-frontend
以上两个仓库求个 star QAQ🌟🌟🌟
目前模块包括:
model:深度神经网络模型模块,目前包括
acgvoc2vec:基于从维基百科动漫列表、萌娘百科、Bangumi 、pixiv 、AnimeList 等来源获取清洗处理抽取的 510w 语句对微调的 sentence-transformers 模型,生成二次元相关文本的特征向量,用于各种下游任务(标签推荐,标签搜索,推荐系统等)
可以使用 Huggingface 在线体验:https://huggingface.co/OysterQAQ/ACGVoc2vec
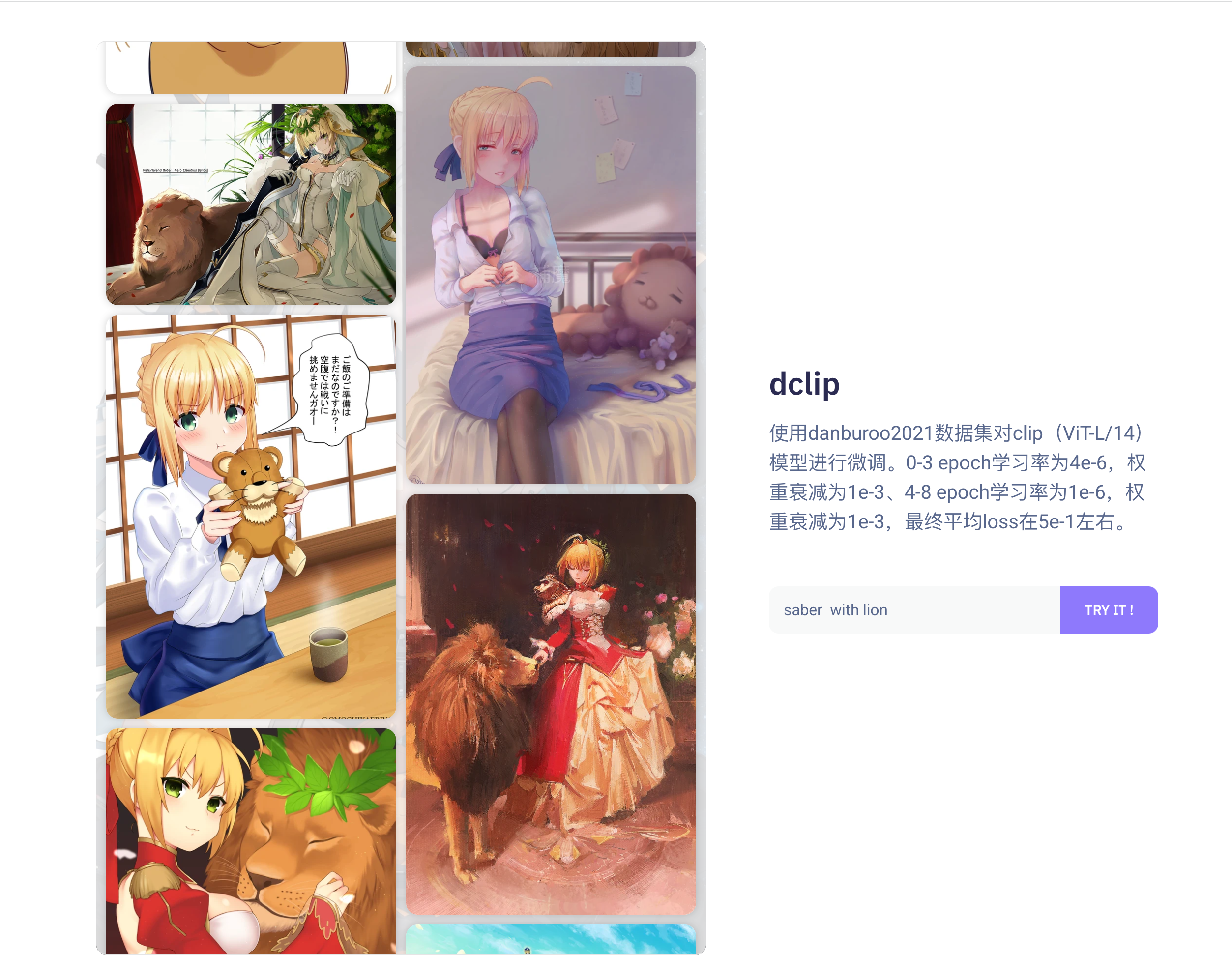
dclip:使用 danburoo2021 数据集对 clip ( ViT-L/14 )模型进行微调。
可以使用 Huggingface 在线体验:https://huggingface.co/OysterQAQ/DanbooruCLIP
pix2score:基于 resnet101 的多任务模型,用于预测动漫插图的收藏数、浏览数与琴瑟级别
illust2vec:从DeepDanbooru模型去除预测头并对末尾层做均值池化的图片语义特征抽取模型
webapp:对外提供 web 服务模块。目前包括开箱即用的二次元插画标签预测服务、以图搜图服务、插画特征抽取服务、文本特征抽取服务
docker:基于容器化的部署模块,包括了部署所需要的配置文件与资源文件

这是一个专为移动设备优化的页面(即为了让你能够在 Google 搜索结果里秒开这个页面),如果你希望参与 V2EX 社区的讨论,你可以继续到 V2EX 上打开本讨论主题的完整版本。
V2EX 是创意工作者们的社区,是一个分享自己正在做的有趣事物、交流想法,可以遇见新朋友甚至新机会的地方。
V2EX is a community of developers, designers and creative people.