Cluade3 深夜发布,模型特点简介&如何使用
原文链接:claude3 深夜发布, 模型特点分析
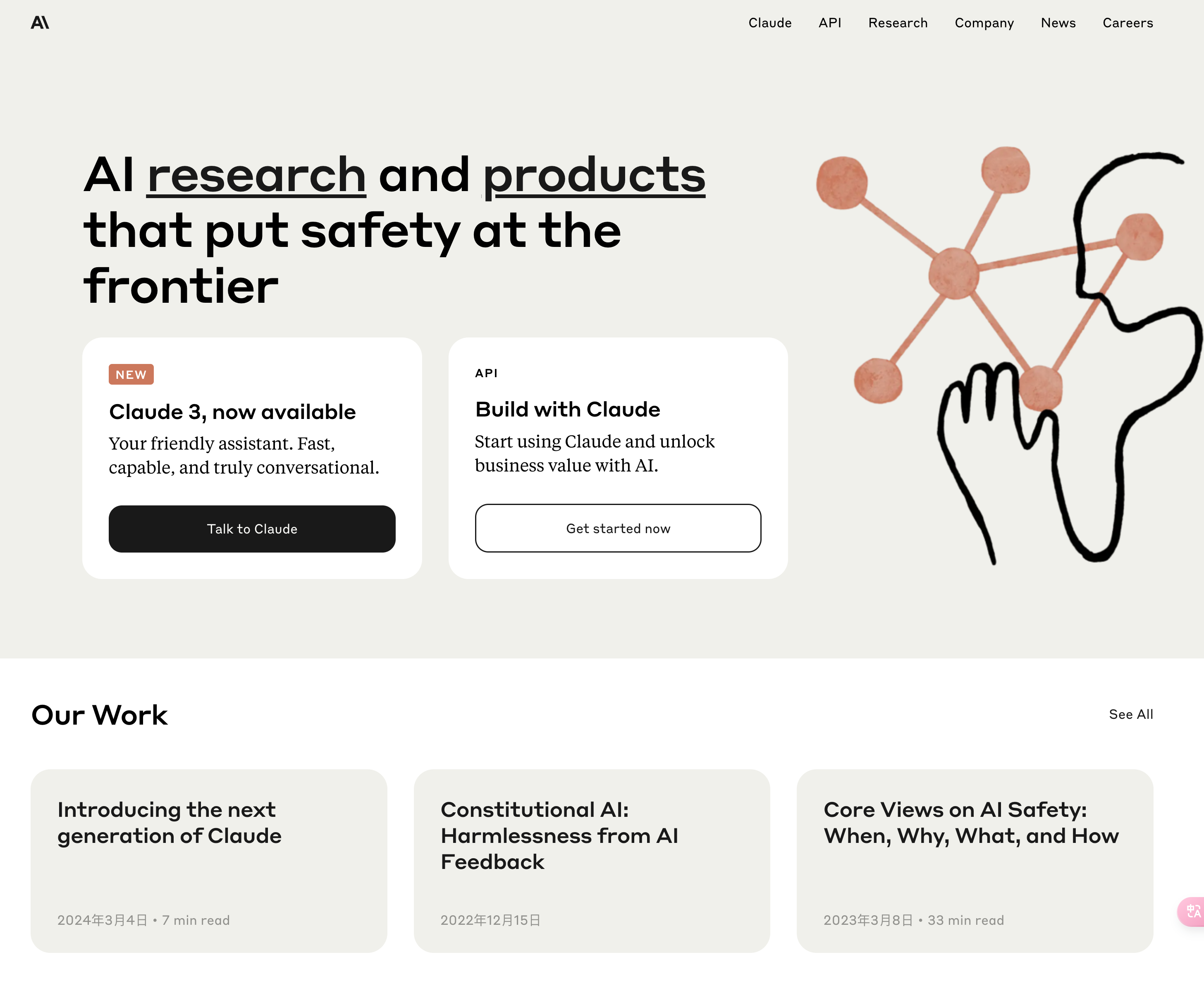
就在刚刚,Claude 发布了最新的大模型 Claude3 ,并且一次性发布了三个模型,分别是
- Claude 3 Haiku:(日本俳句 )
- Claude 3 Sonnet (英文十四行诗)
- Claude 3 Opus (古典乐作品集)
其中他们的能力也是依次递进的,分别满足了不同人群的需求,官方对这三个模型的能力 评价用了一张图简单明了的表示出来了,简单理解 [ haiku < sonnet < opus ] ,opus 直接用来对标 GPT4
模型特点
这次一口气发布了三个模型,但是这三个模型都有下面几个能力,我们结合官方的一些例子进行说明
- 图像识别能力
- 响应速度非常快
- 200K 的上下文窗口
图像识别
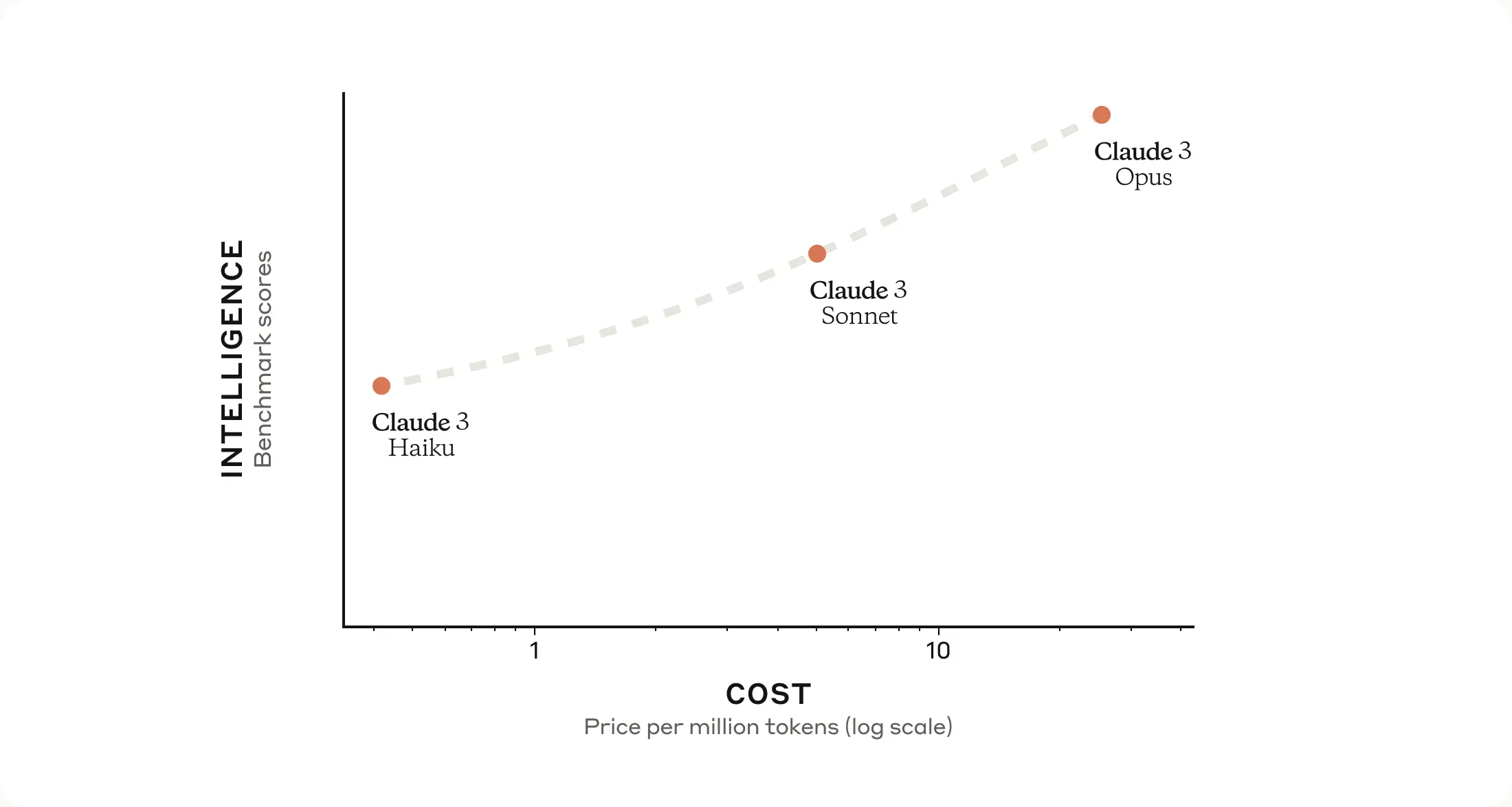
虽然 GPT4 也可以识别图像能力,但是可以从一个评测识别能力的榜单、以及官方演示视频可以看到,Cluade3 的表现很好,并且能够非常好的捕捉细节。
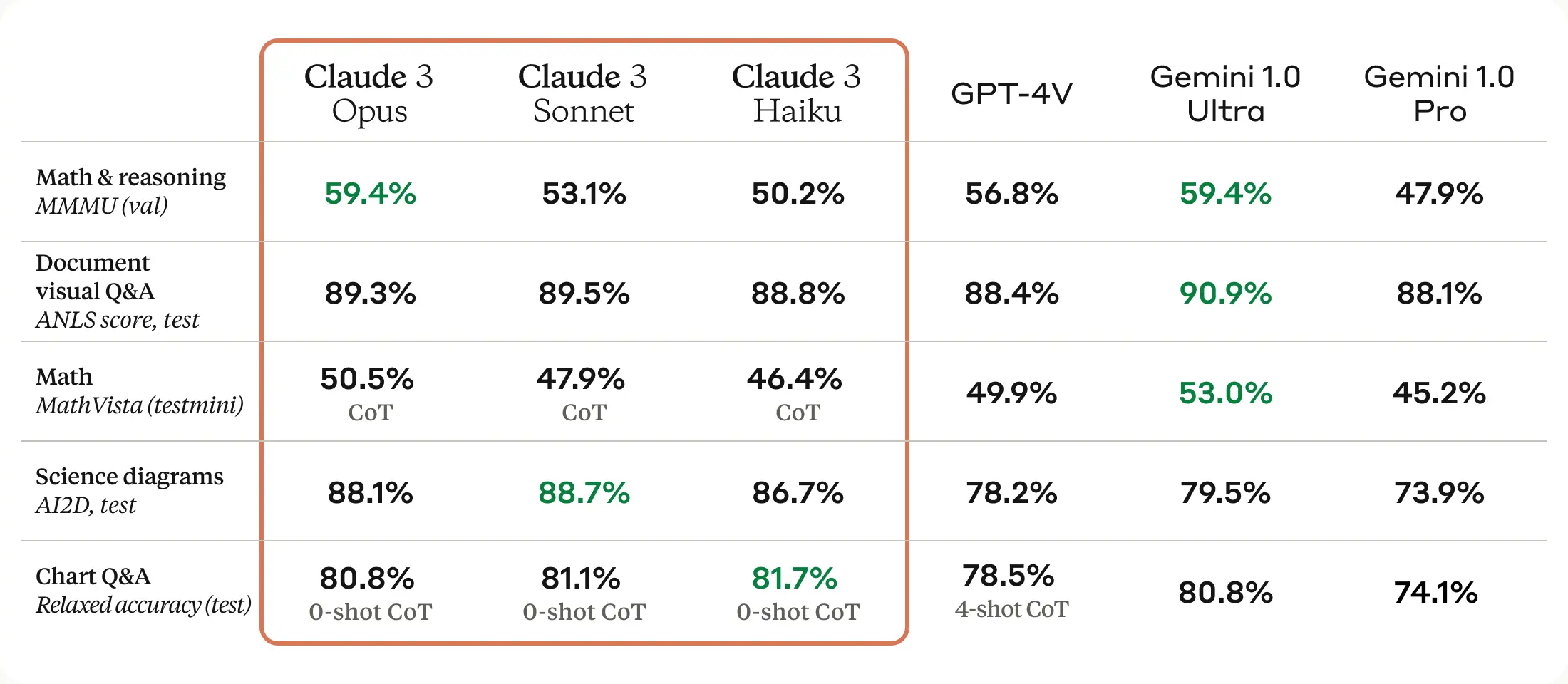
我们可以从下面的榜单看到,Claude3 Opus 的识别性能是和 GPT4V 这个我们认为最厉害的视频/图片理解模型是相当的,并且在 「 Science Diagrams 」上大幅领先 GPT4V 。
个人感觉以后读论文,真的可以直接扔给 Cluade3 试试了,之前的识别无论是 GPT4 还是其他模型,对图表的能力都比较差,现在来看 Claude3 大概率做了不少功夫来优化
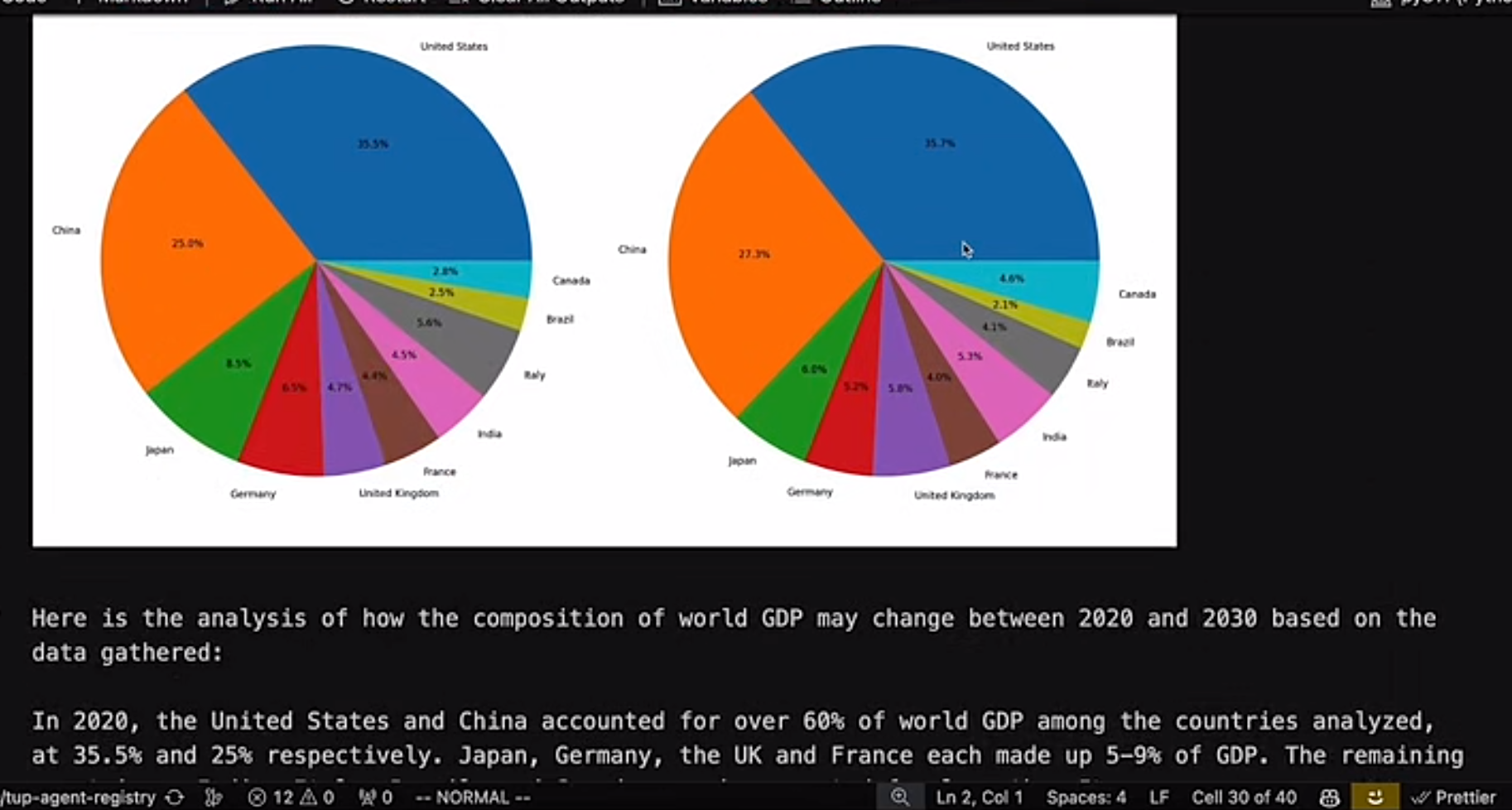
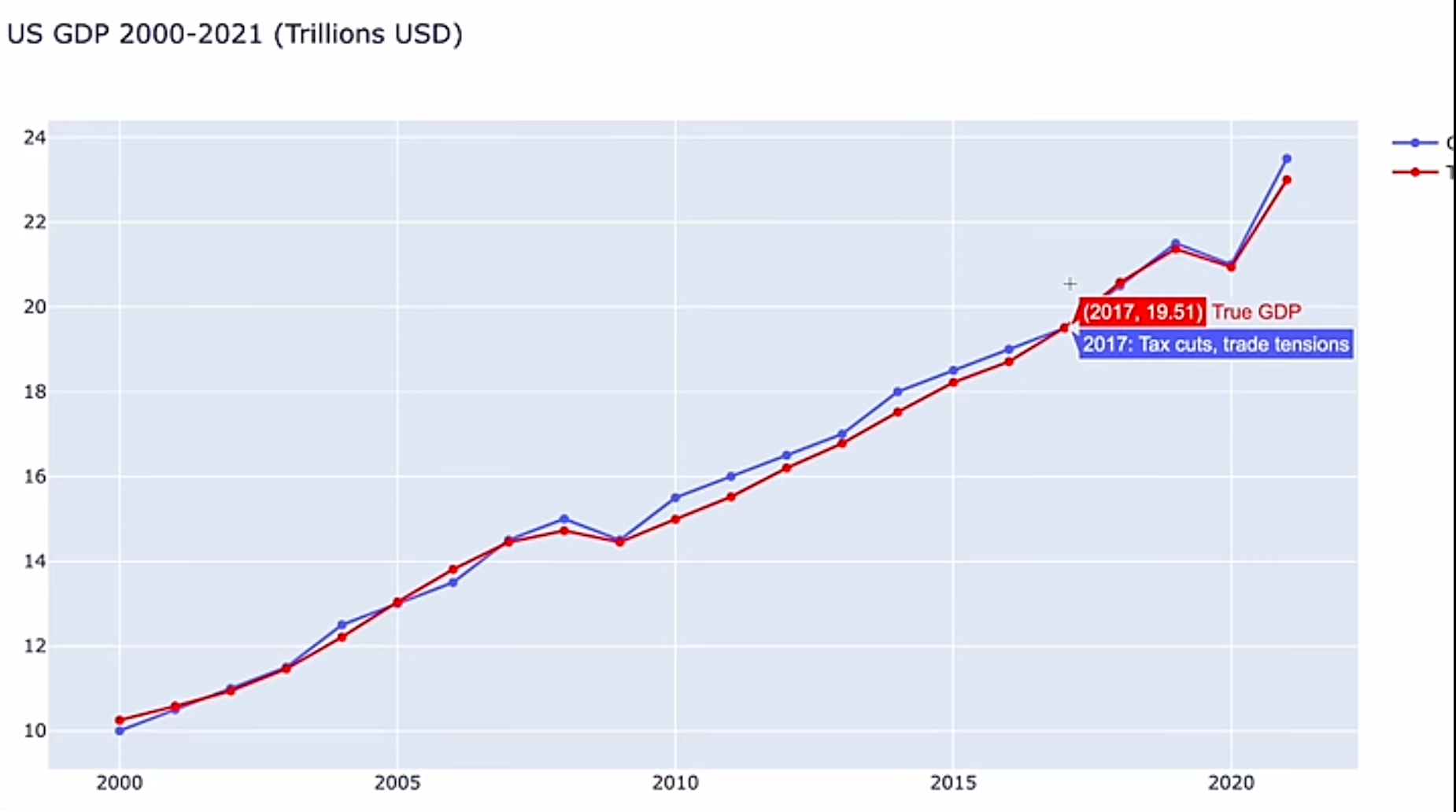
官网的例子中,他通过上网工具学会了看 us gdp 曲线,竟然能够理解,并且对接下来的 GDP 趋势做出预测和可视化描述,非常强大,而且最终的预测精度还是比较高的
Claude3 预测的例子:下面的图表完全通过 Claude3 的代码生成
响应速度非常快
-
目前 Haiku 模型可以在三秒内读取一篇 arxiv 的论文( 10k token ),并且是附带图片的论文(进一步说明了其图文理解的能力)
-
相比于 2.1, Claude3 的模型比之前快了 2 倍以上
超大杯上下文
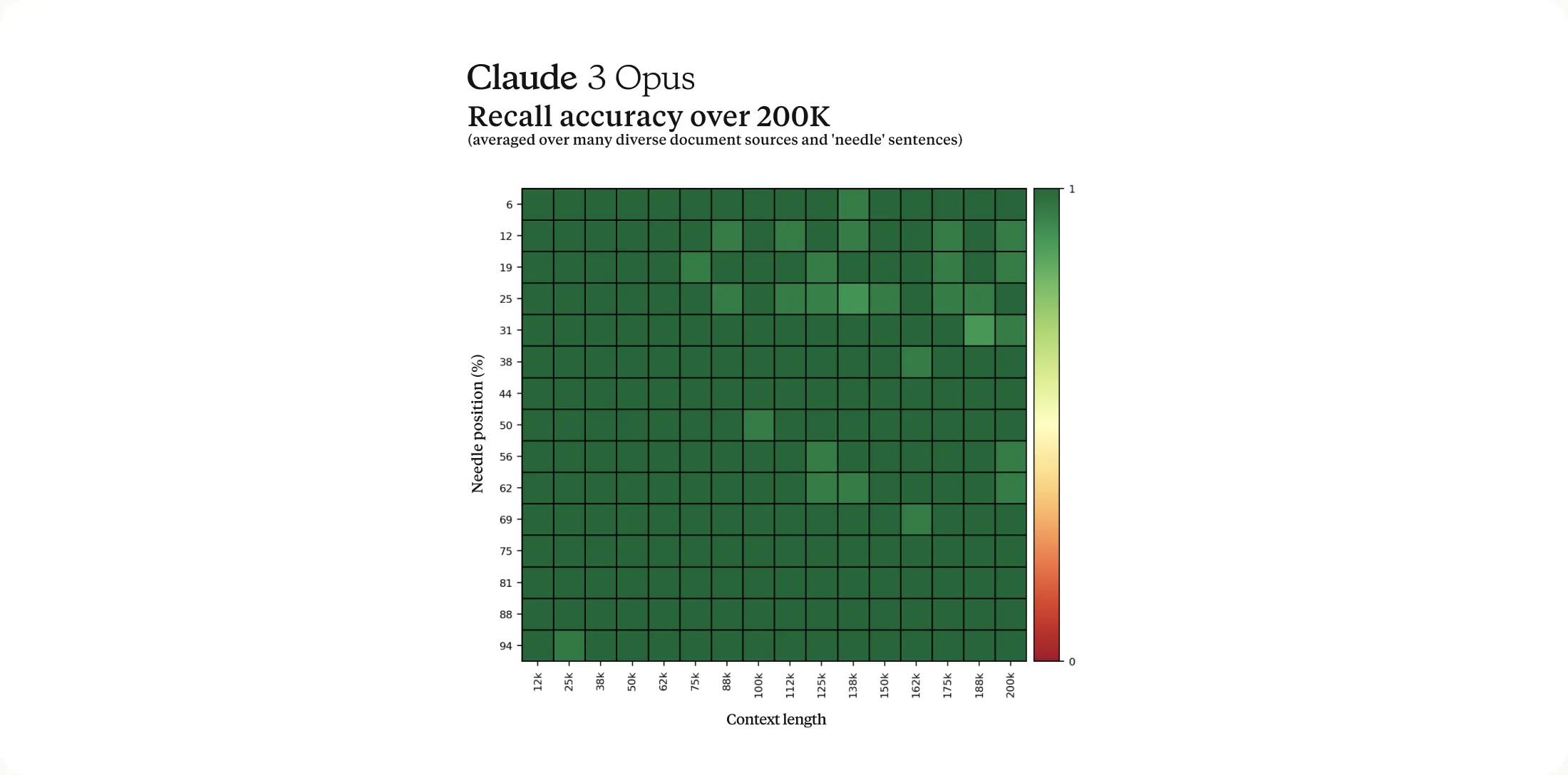
Claude3 会提供超过 20w 个上下文的窗口,并且 [三个模型都可以接收 100w 的输入] !!!!
官网提出了一个名字叫「 Needle In A Haystack 」 的评测方法,用来衡量从一大堆语聊数据中准确提取相关文本的能力( ps:简单理解就是,只看和问题相关的信息,忽略不重要的信息)。
Claude3 通过使用每个提示中的 30 个随机 Needle/QUestion 中的一个,并在一个多样化文档语料上进行测试,增强了这个基准的稳健性。
准确率最终可以达到 99%
评测指标全方面领先 GPT4
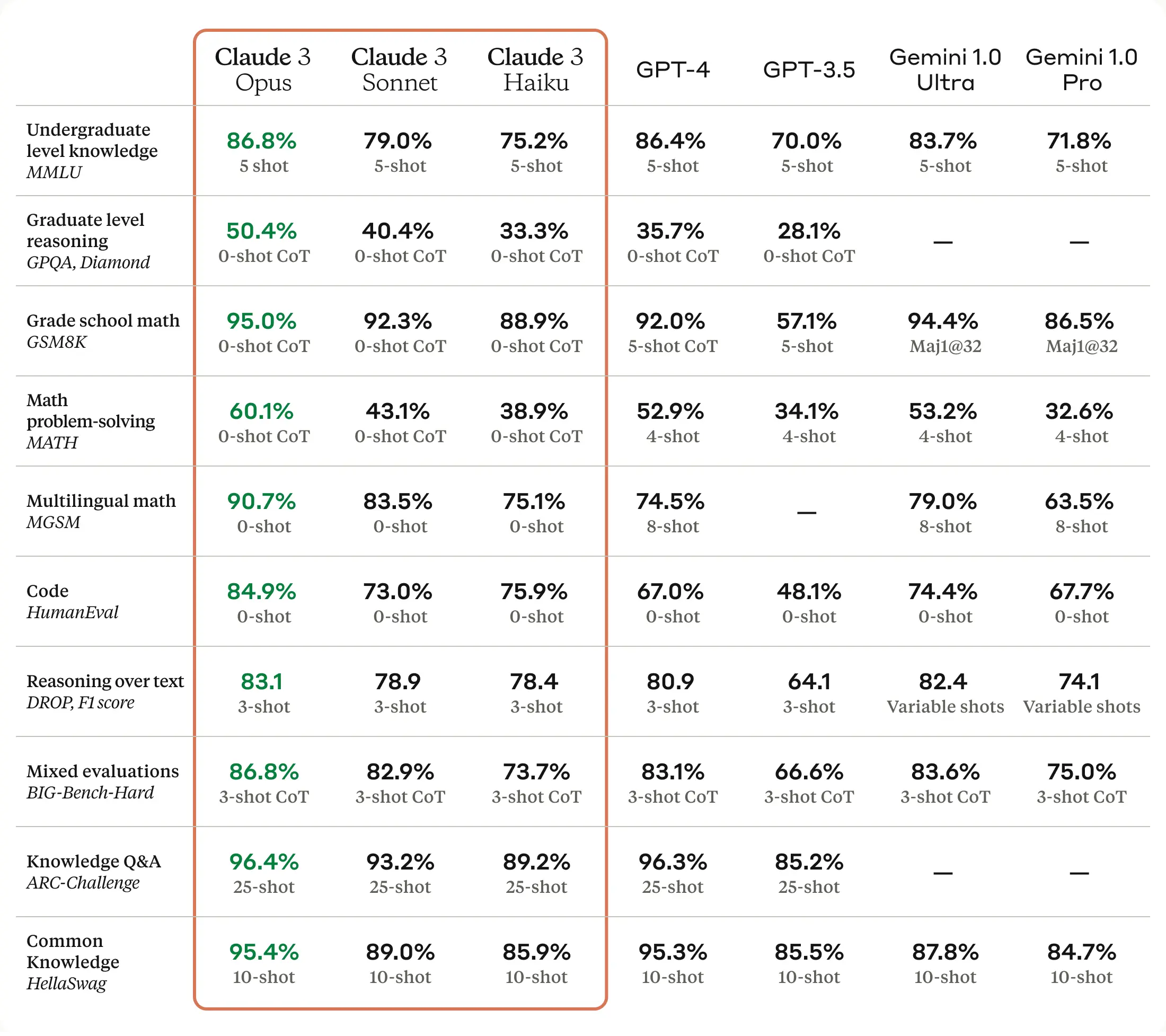
官方列出了一张图表,分别从 编码,推理,数学,多语言,和文本理解上,基于现有的模型评测体系,全方面的和 GPT4 进行了对比。
和我们之前国内某些厂商不同,之前的模型对比 GPT4 都是某个纬度的能力略胜或者接近 GPT4 ,但是从下表可以看出,Cluade3 的模型能力是「全面超越了 GPT4」,并且在数学问题上以及推理能力上做的非常好
如何使用
目前 Opus 和 Sonnet 都可以在官网使用了!Home \ Anthropic
但是 Opus ,和 GPT plus 一样,收费是 20 美元/月