
资讯的价值在于更新自己的知识图谱。问题是:怎么判断哪些该更新、哪些是噪音?

背景
年中我给自己定了个业余小目标:做一个能帮我自动整理每日技术资讯的 Agent 。
场景很具体:每天早上,Agent 自动抓取 GitHub Trending 、掘金热榜、Reddit programming 等的内容,过滤噪音,按主题分类。然后跟我本地的技术知识库做比对——这条资讯是补充了某个知识点、修正了我之前的理解、还是跟已有内容重复?最后生成一份简报,标注每条内容对知识库的价值。
为什么要折腾这个?
在《代码贬值了吗? AI 时代,开发者的护城河》 中提到蚂蚁觅食的启示: 大部分蚂蚁沿着信息素走已知路径,但总有一小撮在"漫无目的"地探索。这些探索者看起来效率低,但正是它们让蚁群能发现新的食物源、跳出局部最优。
我给自己留了 20% 的业余时间做这种探索(还要预留 50% 以上时间辅导娃~)。AI Agent 就是今年的探索方向。
Demo 很快跑通了。写几个爬虫脚本,接上 GPT-4 做摘要和分类,能跑。然后发现,离每天稳定出简报还差十万八千里。
模型选哪个? API 还是自己部署? Agent 给多大自主权? Prompt 怎么管理?每个决策都在 trade-off 。
下面是我趟过的路。
Agent 要不要全自主?
刚开始想做全自主:定时任务一跑,抓取、分类、比对知识库、自动更新,全自动。
后来发现这是作死。
有一次早上醒来,发现知识库里"React 状态管理"这个节点下的内容被删了一大半。Agent 的判断逻辑是:新抓到一篇文章说"Redux 已经过时了,现在都用 Zustand",它就把知识库里所有 Redux 相关的笔记标记为"过时内容"并清理掉了。
问题是,那篇文章只是作者的个人观点,Redux 在很多项目里还是主流方案。
还有一次更离谱。 Agent 抓到一篇"微服务已死,单体才是未来",它居然开始"修正"我的微服务知识节点,把很多内容标注为"已废弃"。
所以改成了混合模式:
- 抓取、分类、生成建议,自动执行
- 涉及知识库的修改(新增/修正/删除),必须我确认
现在 Agent 会生成这样的建议:"建议在'状态管理'节点下新增 Zustand 相关内容,与现有 Redux 内容形成对比"。我看了觉得靠谱就一键确认,不靠谱就跳过。
用 API 还是自己部署?
跑了一个月 Demo ,收到 OpenAI 账单:$140 。
就一个资讯整理的小工具,一个月 140 刀?仔细一看,主要是 README 摘要吃令牌太狠。有些项目的 README 写了几千字,全塞进去让 GPT-4 总结,一个项目就烧掉几毛钱。
开始认真考虑替代方案。
调研了一圈,选了这个组合:
- 分类任务(判断一篇文章属于 AI/前端/后端/DevOps )→ 本地 Qwen3-8B ( Ollama 部署),免费
- 知识库比对 + 摘要→ DeepSeek API ,比 GPT-4 便宜 10 倍,中文效果好
- 复杂推理兜底(比如判断"事实性修正"还是"观点讨论")→ GPT-4.1 或 GPT-5 mini
为什么选 Qwen3 ?中文场景,中文模型更靠谱。分类准确率比英文模型高 15% 左右。
为什么用 Ollama ?服务稳定,Docker 部署方便,适合长期跑定时任务。配合 Open WebUI 还能有个 GUI 界面调试。
这样改完,月成本从 $140 降到 $25 。DeepSeek 的 API 真的香。
模型怎么选?
别只看 benchmark 。
试过几个跑分很好的英文模型,做中文分类老出幺蛾子。
我的 Prompt 写得很清楚:"请将文章分类为以下类别之一:AI 、前端、后端、DevOps 、其他。只输出类别名称,不要输出其他内容。"
它的输出:"这是一篇关于 Kubernetes 的文章,我认为应该归类为 DevOps 。"
拜托,我说了只输出类别名称啊。
换成 Qwen3-8B 就没这问题了。同样的 Prompt ,它老老实实输出"DevOps",中文文章也没问题。
所以选模型要看具体任务:
指令遵循能力——做分类、格式化输出这类任务,模型必须听话。不是所有模型都能做到"只输出 X ,不要输出其他"。
上下文窗口——有些 README 巨长,8K 上下文根本塞不下。后来统一用 32K+ 的模型。
推理速度——每天早上 7 点要出简报,100+ 篇文章要处理。速度太慢会赶不上。
令牌成本——分类任务量大但简单,用便宜的;摘要任务量小但要效果,用贵的。分开算账。
Agent 的内部结构
很多人以为 Agent 是个黑箱,其实拆开看就是几个模块。拿我的资讯整理 Agent 举例:
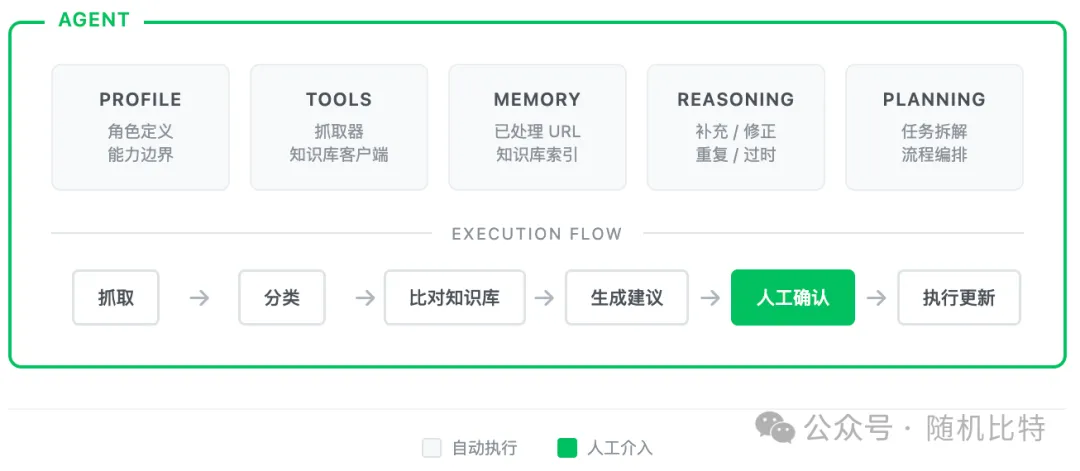
这里的思路和 《 UI 开发范式转移:AI + 数据驱动》 中通过原子数据层 -> 计算层 -> 应用层 的思路一致,增强数据流可见性。
模块化的好处是能单独改。
比如后来发现"修正"判断经常出错(把观点当事实),我只改了 Reasoning 模块的 Prompt ,加了一条:"区分事实性修正和观点性讨论,只有官方文档、RFC 、核心维护者的声明才算事实性修正"。
再比如想支持 Hacker News ,只需要加一个 hn_fetcher 工具,其他模块不用动。
善用行为树
一开始,整个流程都写在一个大 Prompt 里:"请抓取 GitHub Trending ,然后分类,然后生成摘要,然后..."
结果经常乱套。有时候它跳过了分类直接生成摘要,有时候它把抓取和分类混在一起做。
后来引入了行为树( Behavior Tree )。
行为树在游戏 AI 和机器人领域用了几十年,是控制复杂流程的最佳实践。
我的资讯整理流程长这样:
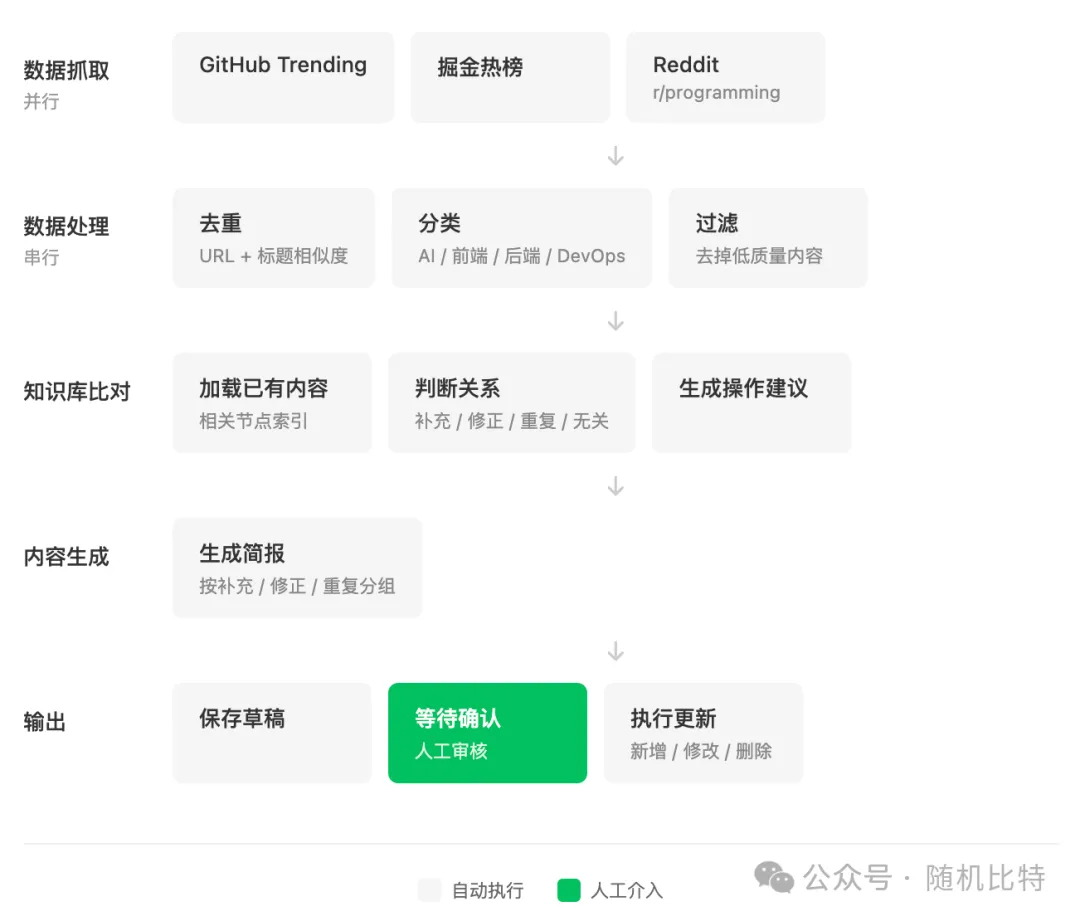
每个节点干什么是确定的。
有一次 Agent 把一篇"Next.js 15 发布"误判为"修正"(它想把我知识库里 Next.js 14 的内容标记为过时)。我定位到"判断关系"节点,发现问题是 Prompt 里没区分"版本更新"和"内容修正"。
加了一条规则:"新版本发布属于'补充'而非'修正',原有版本内容仍然有效"。改完这一个节点就好,不用动其他地方。
Prompt 要当代码管
我有四个 Prompt:分类用的、摘要用的、知识库比对用的、生成简报用的。
一开始都写在代码里。有一次改了分类 Prompt ,想让它支持"安全"这个新类别。改完忘了同步到简报 Prompt 里,结果简报模板里压根没有"安全"这个分组,分类出来的"安全"文章全丢了。
后来改成这样:

每个 Prompt 有版本号。改了 Prompt 要跑一遍测试用例,确保输出格式没变。
写 Prompt 的几个经验:
分类 Prompt 要给例子。不给例子的话,模型对"DevOps"和"后端"的边界理解跟我不一样。我加了 5 个 few-shot 例子,分类错误率从约 30%降到到 10% 以下。
知识库比对 Prompt 要区分事实和观点。这是踩坑最多的地方。我加了明确定义:"只有官方文档、RFC 、核心维护者声明才算'事实性修正';个人博客、教程文章里的观点只能算'补充视角',不能触发知识库修改"。
简报 Prompt 要用分隔符。文章内容里可能有奇怪的字符,如果不隔开,模型会把内容当成指令执行。用 ``` 包起来就安全了。
更系统化的 Prompt 方法论可以参考之前的分享: 代码贬值了吗? AI 时代,开发者的护城河
踩过的坑
token 爆炸
有一天简报生成失败了,看日志发现单次请求用了 48K token 。
原因:那天 GitHub Trending 上有个项目,README 写了 15000 字(是个文档项目)。我把整个 README 塞给 DeepSeek 做摘要,直接超了。
解法:
- README 超过 2000 字的,先用本地 Qwen3 做一次"预摘要",再喂给 DeepSeek
- 只保留 README 的前 1500 字 + 最后 500 字(开头有项目介绍,结尾通常有关键信息)
- 抓取结果不存全量 JSON ,只留 title 、url 、stars 、description 这几个字段
优化完,单次任务从平均 15K token 降到 4K 。
抓取失败的连锁反应
遇到一次网站改版,爬虫抓到的是空数据。Agent 不知道这是"抓取失败"还是"今天真的没热门",继续往下走,生成了一份只有 GitHub 内容的"残缺简报"。
更搞笑的是,它还很认真地在简报开头写:"今日 xx 无热门内容"。
解法:
- 每个数据源抓取后,检查数量是否在合理范围(热榜一般不可能是 0 条)
- 抓取失败时返回明确的错误码,Agent 看到错误码就跳过这个源,并在简报里标注"数据获取失败"
- 加了告警:连续 3 天某个源数据异常就发通知
知识库误删
解法:
- 删除操作必须人工确认,Agent 只能"建议删除"
- 知识库比对 Prompt 里加了来源权重:"官方文档 > RFC > 核心维护者博客 > 普通技术博客 > 社区讨论"
- 只有高权重来源才能触发"修正"判断,低权重来源只能是"补充视角"
- 加了知识库 git 管理,出问题能回滚
效果
跑了 4 个月,稳定了。
现在每天早上 7 点,简报按时出现在知识库 inbox 里。简报分三个部分:"建议补充的内容""值得关注的新视角""与已有知识重复,跳过"。
我只需要扫一眼"建议补充"的部分,点确认就自动入库。每天 5 分钟,知识库持续在长。
4 个月下来,知识库从 200 多个节点涨到 400 多个。其中有 3 个节点是 Agent 发现的新方向(我之前完全没关注),还有 2 个节点的内容被官方文档更新"修正"过。
探索的 20% 时间没白花。
几条经验
1. 涉及删除/修改的操作,必须人工确认 我的 Agent 可以自动抓取、分类、生成建议,但涉及知识库的增删改,必须我确认。
2. 选模型看任务,亲自实验,不看跑分 分类任务要的是"听话",知识库比对要的是"理解力"。不同任务用不同模型,别想着一个模型打天下。
3. 区分事实和观点 Agent 最容易犯的错是把观点当事实。Prompt 里要明确定义什么来源才能触发"修正"——官方文档可以,个人博客不行。
4. 复杂流程用行为树拆开 "抓取→分类→比对知识库→生成建议→执行更新"这个流程,写成一个大 Prompt 会乱,拆成行为树的节点就清晰了。出问题能直接定位到哪一步。
第 1 条附言 · 15 小时 15 分钟前
没有开源 和个人笔记结合很紧密,可以关注我的公众号,后续把代码部分发出来
文章流程描述比较详细,也可以试试用 AI 复现下,但是有个前提,个人笔记之前要是纯文本管理的,对于富文本格式比较复杂
文章流程描述比较详细,也可以试试用 AI 复现下,但是有个前提,个人笔记之前要是纯文本管理的,对于富文本格式比较复杂
第 2 条附言 · 9 小时 44 分钟前

 |
1
wshjdx 20 小时 25 分钟前 via iPhone
牛
|
 |
2
PowerDi 20 小时 22 分钟前
给个体验 demo 地址
|
 |
3
cheneven 20 小时 18 分钟前
给个体验 demo 地址
|
 |
4
skuuhui 20 小时 12 分钟前
没有任何恶意,你这最终的还是 demo 级产品,但不得不是说一个非常完美的 demo 级别产品。另外一提,你应该是前段时间学了很多智能体/rag 开发相关的知识,然后开始做的产品功能。其实目前这个时期 ai 产品开发技术太快了,你的很多技术的选型,思维都远落后目前进度了。
|
 |
5
lifeintools 20 小时 12 分钟前
牛
|

 |
7
zhangfannn 19 小时 17 分钟前
动手能力强啊
|
 |
8
JShen 19 小时 8 分钟前
给个 Demo 体验地址,或者能开源嘛
|
 |
9
Syriana 19 小时 3 分钟前
请问大佬本地知识库是用什么软件存储的文档。我本地个人知识库用印象笔记,这种怎么继承
|
 |
11
JasonRobert 17 小时 42 分钟前
给个体验 demo 地址,支持大佬~
|
 |
12
xiaoshu OP 没有开源 和个人笔记结合很紧密,可以关注我的公众号,后续把代码部分发出来
文章流程描述比较详细,也可以试试用 AI 复现下,但是有个前提,个人笔记之前要是纯文本管理的,对于富文本格式比较复杂 |
 |
13
kylesean 15 小时 5 分钟前
你这个最开始的需求用 n8n 满足不了吗?
|
 |
15
xing7673 10 小时 3 分钟前 via iPhone
很有帮助,最近也想做一个类似 folo 可以自定义订阅抓取需要的新闻并且做简报分析,准备在年底实现一个初步的版本。
|