
这是一个创建于 3240 天前的主题,其中的信息可能已经有所发展或是发生改变。

王璞/数人云创始人&CEO
美国 George Mason 大学计算机博士。曾先后供职于 Google、Groupon 和 StumbleUpon 等硅谷互联网公司。擅长分布式计算、大规模机器学习、海量数据处理。曾担任 Google 广告部门数据平台构架师,负责管理每秒访问量全球最高的架构平台。
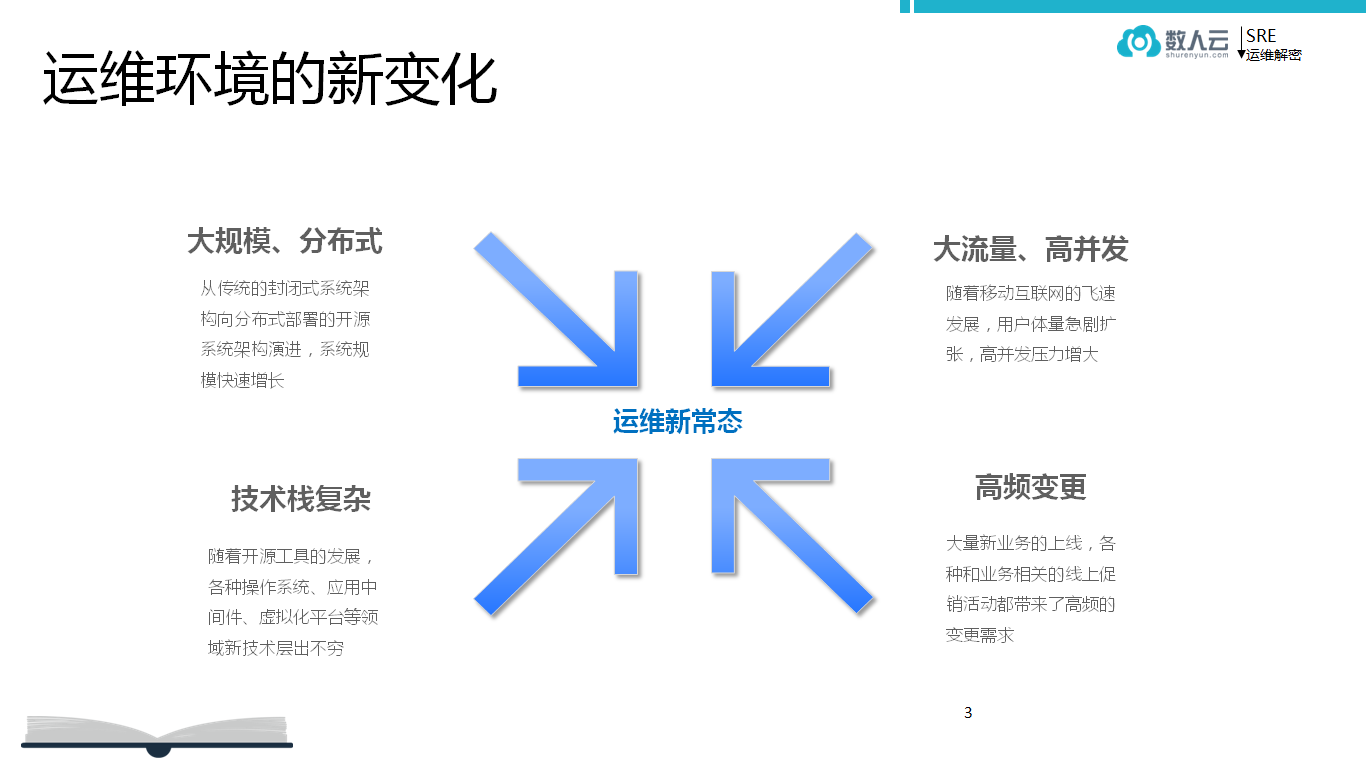
运维环境的新变化
数人云是基于容器的轻量级 PaaS 平台落地企业客户时,客户很难理解一个平台背后隐含的东西,任何平台及工具都是与方法论结合的,比如研发工具、持续交付工具等等,都有一套方法和理念,今天主要分享下 SRE 理念在传统企业中的落地实践。
随着技术的发展,运维环境发生了新变化,比如互联网的场景下,线上业务和线下业务的差异非常大。
-
大规模、分布化:
从传统的封闭式系统架构向分布式部署的开源系统架构演进,系统规模快速增长,尤其是谷歌互联网业务数据中心,大概有 200 多万台服务器,这个规模是十分庞大的。
-
技术栈复杂:
开源技术层出不穷,再加上大数据技术,技术栈变得越来越复杂。
-
大流量、高并发:
用户体量急剧扩张,互联网场景大流量,高压并发压力增大。跟唯品会的朋友聊到,几个小时的促销时间里,近百万的流量,这在传统线下是没有遇到过的。
-
高频变更:
大量新业务的推出,各种与业务相关的线上活动带来高频变更需求。
国内电商每个月都有节日促销,都有重大的变更,互联网公司至少做到一周变更一次。对于传统企业客户来讲是很大的,如银行大都是半年做一次变更。这些运维环境新的变化,主要是由于互联网场景的变化所带来的。
DevOps
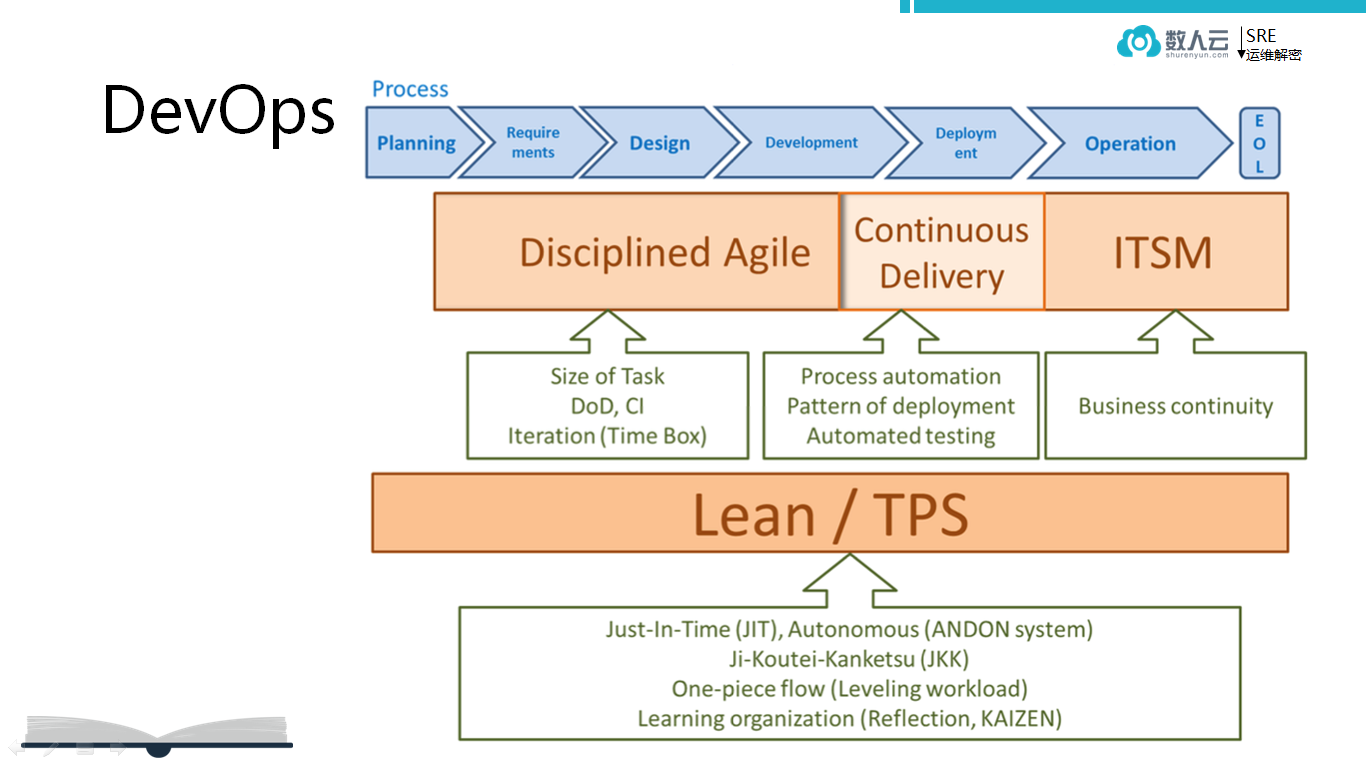
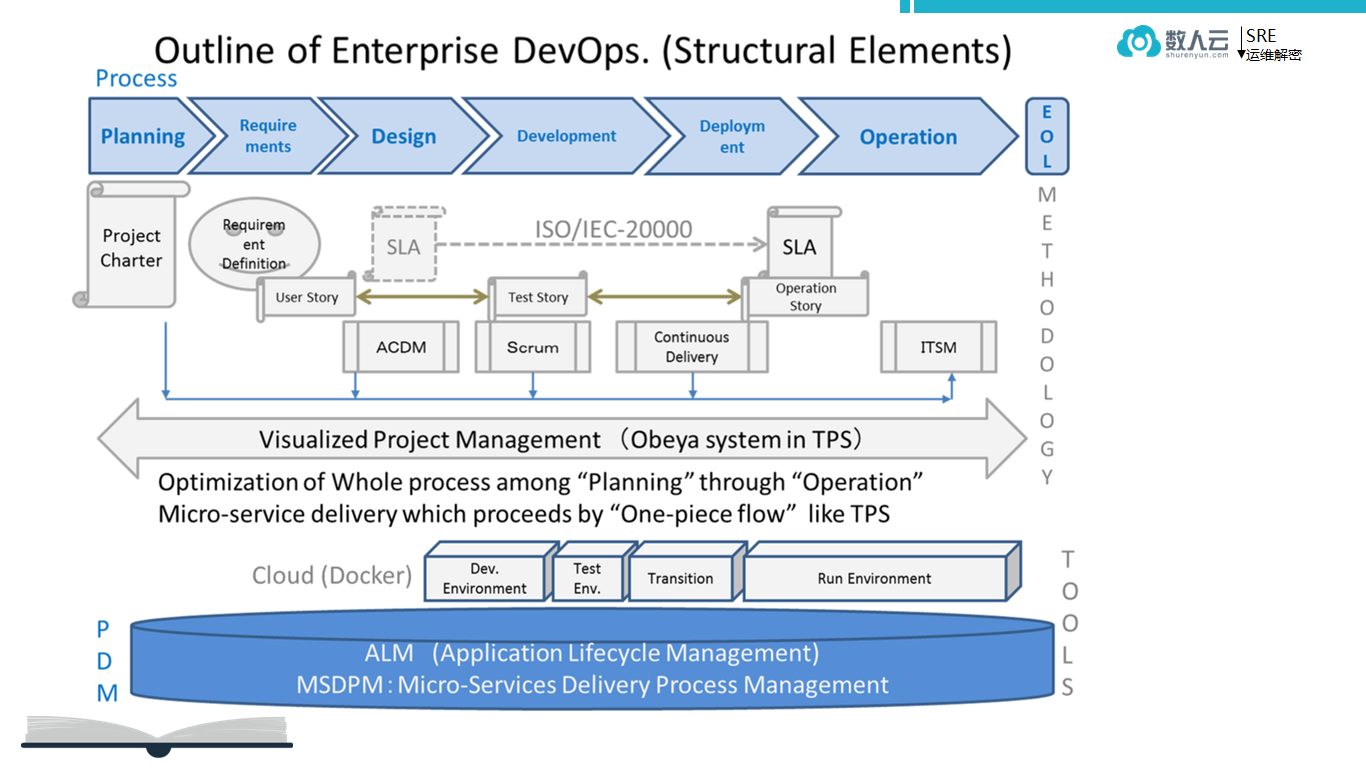
DevOps 的知识结构非常复杂,从规划设计阶段到开发阶段,对于很多企业的客户来说无法落地,就连部分互联网公司也未必能完完整整把 DevOps 从设计到开发、交付直至上线完整地落地。
运维 IT 服务管理流程
例:流程图里面太多的数据和细节,很多细节至今都未深入涉及。
开发、运维一体化
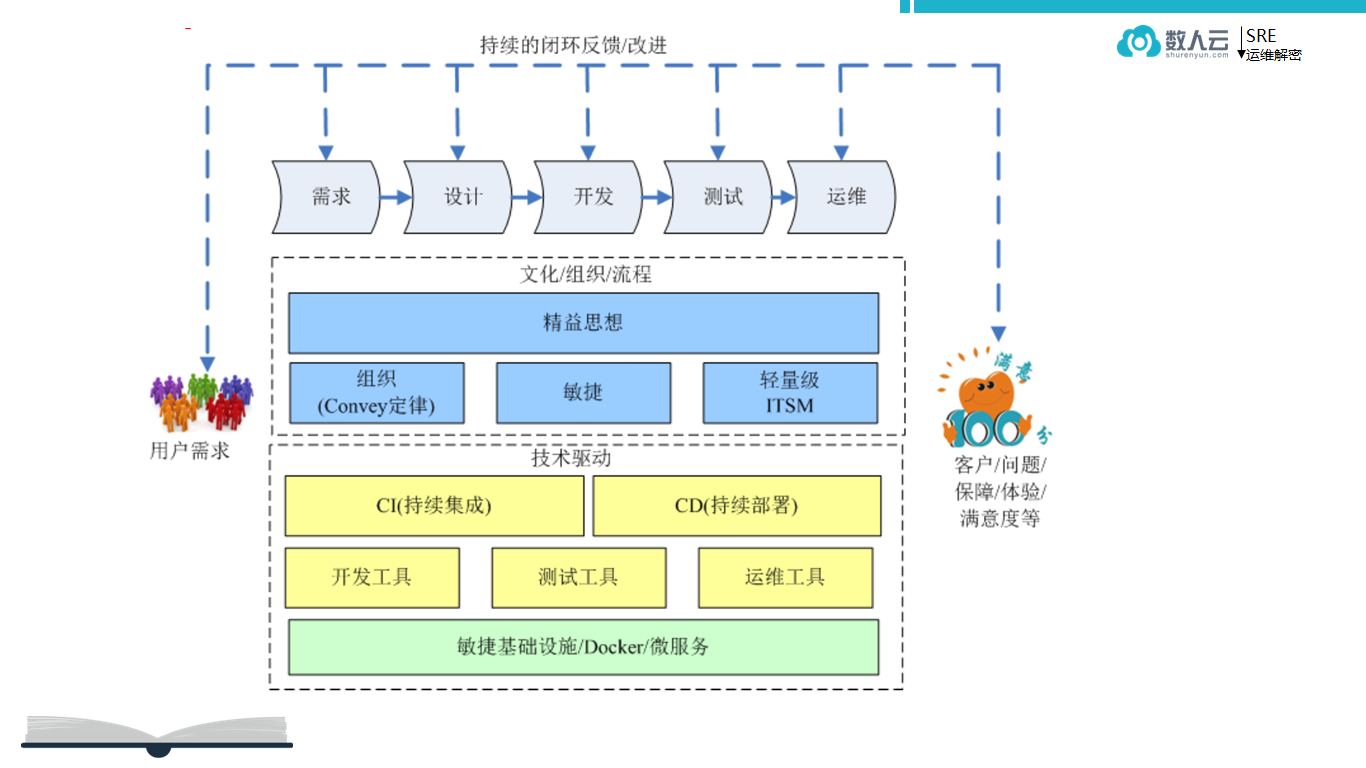
DevOps 是开发、运维一体化,从业务的需求到开发、交付上线一体的。
上面是 DevOps 偏理论的部分,中间是落地到技术的部分,底层是基于软件的基础架构。真正把 DevOps 落地好需要理解的东西太多,成本太高,所以谷歌在 DevOps 的方面,尤其在偏运维的方面总结出一套 SRE 理念,这套 SRE 的方法论是 DevOps 思想在谷歌运维方面的最佳实践。
SRE 的由来

首先明确下概念:
DevOps 有很多实践,丰田汽车这种传统制造业公司也用 DevOps。 SRE 是 DevOps 的一种实践,偏互联网公司一些,前面提到 SRE 在谷歌内部偏重运维部分,开发设计不是特别多,也不会提敏捷开发这些。
SRE 是怎样来的呢? 2003 年,谷歌数据中心规模应该在几千台甚至是上万台的服务器,当时没有运维,更多叫系统管理员,很多系统管理员不能管理大规模的 X86 服务器的系统(当时主机的 IT 硬件设备是大型机的设备,系统管理员管理的绝大部分都是小型机,谷歌从来不买大型机),于是被迫从开发中找出来 7 个人转岗做生产运维,他们做数据管理中心运维的时候发现很多的问题,首先系统管理有很多重复性的工作,运行脚本等等,这些开发工程师对重复的工作比较抵触,所以自己开发大量的运维工具自动化的实现运维,这批开发工程师就是现在的 SRE。
三角形的图显示了谷歌的 SRE 工程师日常工程的内容和职责,主要是工程的研发,剩下才是日常运维。
传统运维模式

传统的系统管理员是人盯着机器,但随着人员的成本越来越高,需要解决的问题不尽相同且效率低下,面对服务器规模越来越大的问题,统运维模式已不适用于互联网的场景。
SRE 的工作职责
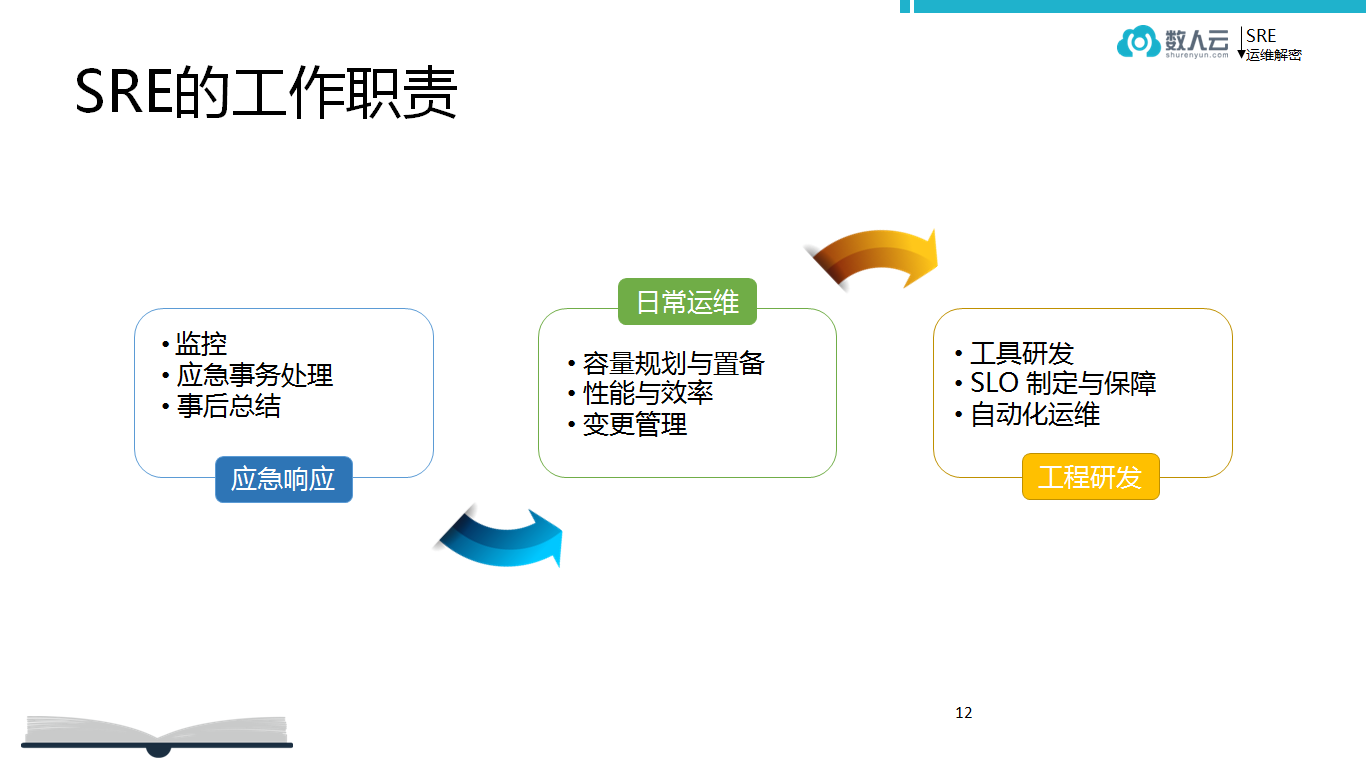
- 开发:
SRE 工程师绝大部分时间要写代码,必须要有很强的开发能力。
- 日常运维:
除了开发之外最重要的是管理资源,如所有资源的效果、性能等。
如,大规模的互联网数据中心,服务器规模庞大,资源的利用率对于数据中心的成本很重要,因此降低数据成本是很有帮助的,谷歌数据中心的利用率还是比较高的,数据中心有一个数值,就是数据中心花一度电有多少是用于冷却的,有多少是用于服务器计算的,谷歌每花 1 度电用到计算上,只有零点几度电是用到服务器冷却的。
这个怎么理解呢?对于 Gmail 服务,不管是活跃用户还是非踊跃的用户,一年使用 Gmail 的服务花谷歌的电费一美元不到,数据中心对于成本、资源的利用率有很苛刻的考量,SRE 就是帮助谷歌实现数据中心最大化的利用率。因为 200 多万台的服务器,谷歌损失 10%,就相当于有 20 万台服务器是被消耗掉的,假如谷歌全部采用虚拟机的话,额外的开销是 15%左右,甚至是 20%,若所有的服务器都变成虚拟机,基本上谷歌 20%的资源不能用,至少几十万台服务器被虚拟化了,底层的系统消耗对谷歌来讲不能接受的。怎么样做到高效—— SRE。
对于变更管理,谷歌和传统的运维不一样,传统的运维做变更时需要开发提供上线,谷歌的 SRE 不是开发提供给 SRE 上线,是 SRE 把各种各样的变更发布的平台准备好,每个系统上线变更都是利用开发的人员自行的发布、自行上线。
- 应急响应:
紧急响应与传统运维一样需要值班,以确保系统出现任何问题都有人去解决。
传统运维模式 VS SRE
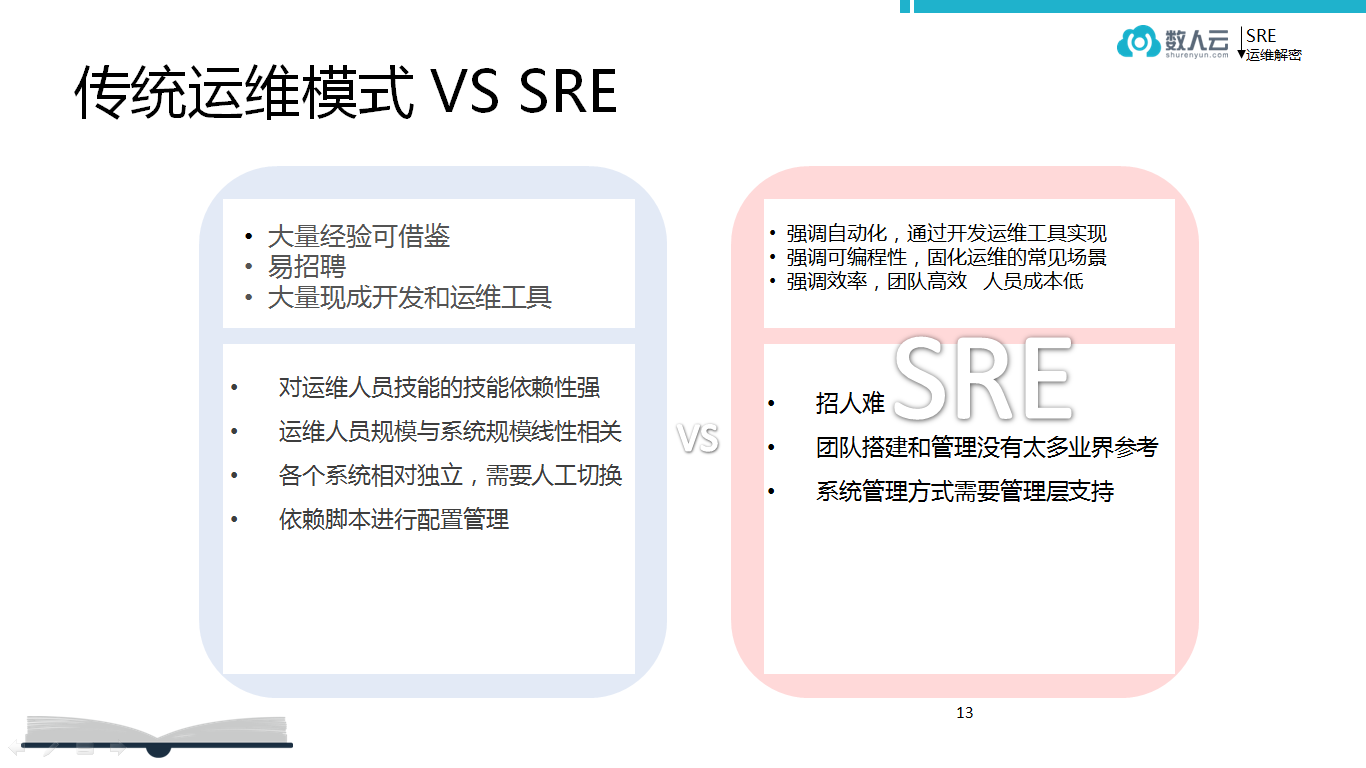
- SRE:
优:自动化、可编程性、效率高。 SRE 强调自动化,运维的工作绝大部分是工具自动化的完成。
缺:人才少、团队搭建管理无参考、系统管理方式需管理层支持 SRE 缺点也很明显,就是招人难,需要有编程的能力和开发能力,对系统也要有很深的理解,比如对网络、内核等,同时 SRE 业界的参考比较少,主要是谷歌等大公司在用。
- 传统运维:
优:大量经验可借鉴、易招聘、工具多。 传统运维经验很丰富尤其绝大多数的企业都是传统的模式。
缺:人员自身技能依赖性强,人员规模与系统规模线性相关,各系统独立需人工切换,依赖脚本管理。 传统运维缺点是很多事情都是人力来做,这样随着服务器越来越多,业务规模越来越大,人也越来越多,效率提不上去。
SRE 文化三个关键点


长期关注研发工作
谷歌的 SRE 文化是做的很好的,保证 SRE 有比较充足的时间做研发,限制每个人的运维工作在 50%以下,保证充足时间去写程序。
SRE 每 8 到 12 小时值班时间窗里最多只处理两个事件。

- 坚持演习
谷歌定期做 SRE 的演习,如最高等级的演习是定期把数据中心强制关闭,进入维护状态。基于这种情况,开发在写程序的时候必须考虑到容错、数据中心不可用,硬件不能进行,所关联的其他软件系统不可用等情况。
经过长期演练,谷歌内部系统的容错能力增强。一个系统容错能力强,对于运维是良性循环,出了问题不容易宕机,SRE 运维压力自然下降。

- 决策与建言权
SRE 关注的非功能性的要求,比如说稳定性等等。这些非功能性的要求在开发写程序的时候早早把 SRE 引进,如果一个系统尽可能满足 SRE 非功能性的需求,这个系统是比较容易上线的,但如果一个系统没有满足 SRE 的要求,每个月的报警数量过多,SRE 可以让这样的系统上线,但 SRE 不接手运维。谷歌内部有一个说法,一个事情 SRE 说 NO,这个事情是做不下去的。
SRE 服务质量目标
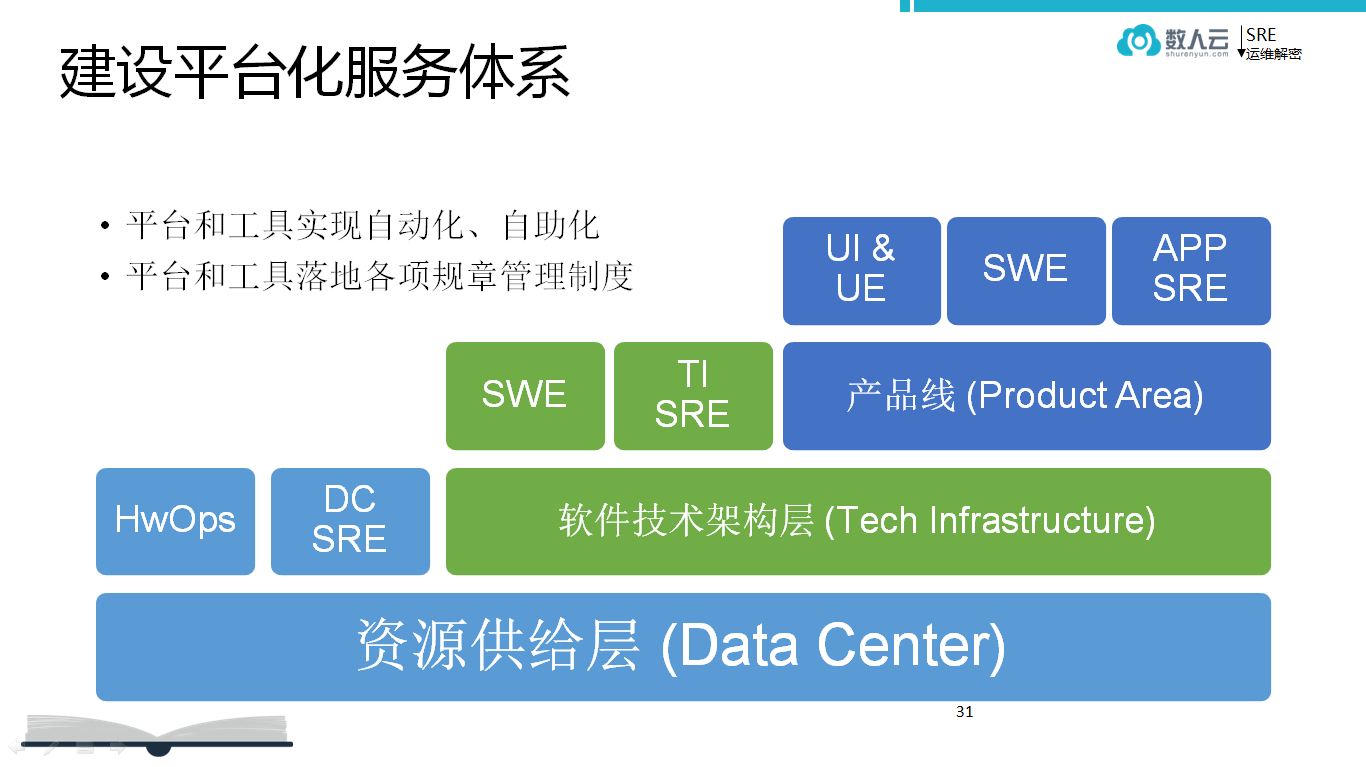
建设平台化服务体系
- 平台和工具实现自动化、自助化
比如开发写出的代码要提交到代码库,对于代码的测试和覆盖、风格都有很多的检查,这些检查不是靠人而是靠工具平台自动化的完成。 制定各项规章制度
- SRE 内部分工明确
如谷歌搜索有 SRE,谷歌广告有 SRE,还有设计平台等等都有,这些是偏业务的。虽然每个 SRE 部门不多,但是加起来,有一半的 SRE 散落在各个业务部门负责相关任务。

容量规划和容量管理
-
SRE 根据业务容量地规划每个业务系统,包括搜索系统、软件内部架构的系统,必须有准确的自然和非自然增长需求规划
-
容量管理,要定期做压力测试,把对于资源的要求测出来
如一核的 CPU 能够处理广告以及搜索系统多少并发等等,这些对于性能的消耗、性能的关联都是 SRE 做的,业务部门提一个数据,比如搜索部门的开发肯定提不出来业务系统要多少的 CPU,提供出来的负载指标都是每一秒中搜索多少的并发和处理多少的请求。SRE 通过压力测试把负载转化成对于资源的要求,不同的搜索部门一秒钟处理一万个请求,一万个请求需要多少的 CPU 等等,这都是压力测试把负载资源等关联起来。
- 任何有关利用率的讨论和改进

保障 SLO 并最大化迭代速度
-
如某个业务系统新版本 20%不可靠,新版本不如老版本稳定,老版本 99%可靠,新版本有 20%可靠,则新版本全部上线无法达到 99%的稳定,于是只能上线一部分,服务 5%的用户,这样最多有 1%的用户没有办法用服务,仍满足 SRE 提出来的系统要求 99%的可靠性。
-
SRE 和开发之间用 SLO 实现最大上线的速度,也平衡了两者之间的矛盾。
 变更管理
变更管理
变更管理:70%的生产都是由变更引起的。谷歌的变更一定是间接发布,其系统有自动回滚,这样降低了新版上线带来的影响。

有效监控
谷歌内部对监控尤其是对报警及其是严格的,每一个报警出来都必须有明确的动作,要执行哪个操作都写在变更手册里。
谷歌的三种有效输出:告警、工单、日志。

正确姿势
值班时任何一个报警必须有明确的动作。谷歌要求报警发生以后,值班人查阅手册就可以应对问题。
若告警是新的,值班 SRE 不做处理,升级告警,让开发过来帮忙处理。值班时 SRE 主要解决线上问题,一旦出现问题,尤其是告警很严重的问题,通过工具半自动回滚,回滚之后保证业务稳定、可用,让业务快速恢复起来。
谷歌内部要求出现过的问题超过三次以上,必须要有自动化修复方法,问题要么根本性的解决,要么自动化的修复。
利用容器将 SRE 理念落地
12 法则
12 法则是非常好的设计模式,通用于很多互联网应用,适合开发和运维人员。
日志
12 法则要求把日志当事件流,容器很容易做到,因为容器的标准输出都是事件流的方式。
持续集成和持续交付
流程我们跟很多的企业碰撞过,尤其是传统企业,流程需要监管,没有办法做到完全的自动化,需要大量人去做。如变更的申请需要人,构建和一部分的测试可以做到自动化,让工具去完成,但是还有大量的测试在企业中是人工的,尤其是一些 IT 部门过来做的测试。有很多工具可以把变更的情况自动化的处理,变更中遇到很多的问题自动化的记录下来,方便变更后的审查。
配置管理
将配置的文件外挂到容器内部,程序可以访问,另外配置文件封装起来,跟程序封装在一起,这些方法没有对错,只是哪些客户能接受哪些客户不能接受的问题。
日志从定向到标准输出
很多日志文件在传统企业按照文件的方式收集过来,日志里面针对问题有特定审查和审批的流程等等。
容器对于应用程序做标准化的封装,日志文件写到容器内部,程序不做任何的更改,通过外部手段对容器进行内部搜索,带来了大量的问题,如果程序在容器内写了大量的日志怎么办?日志文件达好几 G 的文件怎么办?严重的破坏容器的性能,这个也有优点和缺点。如日志文件外挂在容器外,客户已有处理方法,对于容器要有额外的配置、额外的参数,容器要迁移到别的服务上,怎么样保证碎片化的日志被完整收集起来,仍然有很多的问题,不同的容器有不同的方法。
监控
目前碰到的客户绝大部分有成型的监控体系,且客户不希望用了容器平台以后又有新的监控系统,因此要跟客户已有的系统对接打通。
弹性扩缩
如业务的负载太大,系统程序需要扩展实例,以前可能只有 3 个容器负载,现在 3 个不够,要扩展到 10 个,怎么触发?人为的触发还是自动化的触发?触发后这个实例是否优雅终止,怎么理解?
实例收缩也很复杂,很多传统的企业都是交易型的,不能随便动,触发准则绝大部分没有见过自动的收缩,是人工触发的动作。大部分企业处理应用,必须保证程序上处理的业务完了才能关闭。怎么判断程序处理掉了?这时候又要对现有程序进行改造,客户又不想改那个程序怎么办?比如通过跟负载均衡器感知一个程序以及后台实例流量完全结束了再关掉,这是很多现实落地的考虑。
检验标准
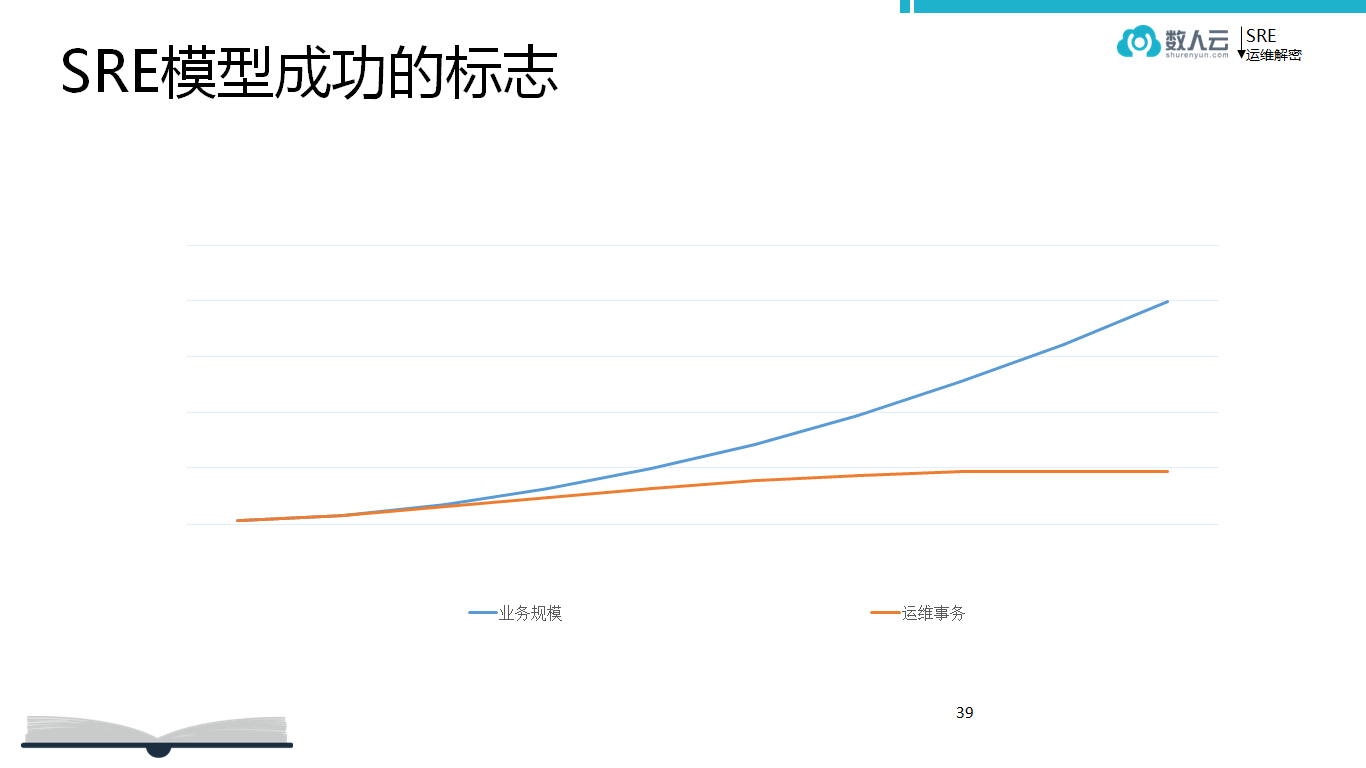
怎么样判断模型是成功的?这里有一个曲线,SRE 讲究自动化以及提升平台效率。
蓝色代表业务规模,对等过来是开发人员的数量,也可以理解成数据中心服务器的数量,这个跟业务规模是成正比的,业务规模大业务人员多,开发人员肯定多,负载高服务器的数量多,蓝色的曲线一定是快速的通道,任何一个企业都希望业务快速增长。
红色运维数据跟人相关,任何一个企业不希望人与业务一起增长,业务增长 10 倍,开发人员跟着涨到 7 - 8 倍,业务的人员涨 7 - 8 倍,显然成本太高了。
SRE 模型成功的标准是业务快速的增长,人不需要同比增加,通过平台自动化满足业务增长需求。如谷歌从 2003 年开始几千至一万台的服务器增加到现在 200 多万台,而人按照这个比例来增长,这就是整个 SRE 不断带来的效率提升。
以上是数人云对于 SRE 落地传统行业的思考,如有更多想法请加小数微信:xiaoshu062 进数人云微信群交流。
技术干货、外文翻译、活动预告、这里全都有!扫码关注数人云微信号。

 |
2
mooncakejs 2017 年 5 月 12 日
@AMD,来教他写 ppt。
|
