
这是一个创建于 2364 天前的主题,其中的信息可能已经有所发展或是发生改变。
随着数字化经济的快速融合与发展,云计算、大数据、物联网等创新技术不断重构着企业 IT,数据中心存储基础架构也在发生深刻的变革,传统的异构存储设备难以解决统一管理和数据共享的难题,而且也不能适配虚拟化、大数据、物联网、混合云、AI 等场景,导致 IT 建设成本居高不下、业务创新也受到阻碍。
在数字化转型带来的挑战中,分布式存储成为数据中心存储基础架构的下一步演化方向。分布式存储系统里,软件处于核心的地位,底层的存储资源则构成统一的存储资源池。通过这种方式,可以实现存储容量、性能的弹性扩展。同时,由软件定义的分布式存储系统可以将硬件与软件进行解耦,将存储资源按需求分配给具体应用,实现存储资源在不同程度、不同广度的灵活调用。
沿着这种思路,优云数智通过系列实践,开发并推出了软件定义的分布式统一存储的解决方案 UMStor,并通过将计算存储环境分离,采用 Hadapter 直接调用 librados 函数库来请求 OSD 的方式,避开了数据存取对网关的请求,在保证大数据环境下的存储访问性能同时,打破环境分离带来的数据调度壁垒。

注:本文整理自优云数智解决方案高级总监方勇在 ArchSummit 2018 深圳的演讲内容,演讲主题为《 UMStor: 数字时代的分布式多协议统一存储实践》,感兴趣的读者可以点击 [阅读原文] 下载讲师演讲 PDF。
统一存储技术的演进历史
大家好,我是来自优云数智的方勇,我是从 2000 年开始从事存储行业工作的。在我的记忆里,似乎每隔几年,大家就要谈一次数据整合,而每次数据整合都会引发一次存储产品的技术创新。那么现在这个阶段,存储技术能带来什么样的创新,在这里我想结合最近我们的一些项目经历来谈谈我个人的一些观点。
根据以往的观察,我把存储技术的主要演化发展分为三个发展阶段:
第一个阶段我称之为信息化时代,这个阶段是直连存储转向网络存储的阶段,今天我们看到的 SAN、NAS 存储技术都是在那个阶段出现的,这个阶段没有统一存储的概念,但是 SAN 存储的出现实现了结构化数据的存储整合,所以从这个角度看,我们可以理解 SAN 存储就是当时的统一存储;
第二个阶段我称之为互联网时代,这个阶段电子商务出现了。从数据的角度来看,这个阶段最大的变化就是非结构数据的快速膨胀。统一存储的概念就是在这个时候出现的,很多企业为了应对数据的快速膨胀,采用了统一存储。统一存储帮助客户用性价比比较高的方式将结构化和非结构化数据集中存储起来,像微信之类的应用;
第三个数据大爆炸的时代出现了,就是社交时代。这个阶段,非结构化数据的膨胀更加恐怖了,在这个阶段,分布式存储技术出现并且开始普及。

那么,我们现在又处在一个什么阶段呢?我觉得是数据爆炸的第四个阶段。
这几年,我看到一个变化,相信大家也看到了,就是云计算、大数据、人工智能、物联网之类的技术被越来越多的行业客户所关注,这些都是一些新型的数字技术,这些数字技术有个很大的特点,就是围绕数据做文章。
由于使用了这些数字技术,客户的数据中心里面围绕这个技术产生的数据量上了一个台阶。我两年前接触过一家国内的信用卡中心客户,当时他们的大数据系统指的就是 Oracle 的数仓,只有几十 TB。前一阵,我再拜访他们的时候,因为云计算技术的使用,他们的存储已经在考虑 PB 级别的存储规划了。今天,这样的案例还有很多。
数字时代需要什么样的存储技术?
那么,这些新的数字技术的使用对存储技术有什么影响呢?符合时代发展的技术才具备生命力,存储也不例外。在 3 年前,我自己就在思考,存储技术的未来会是什么样?存储技术作为独立的 IT 子系统存在有 20 年左右的时间了,经过这么些年的演化,存储技术始终是围绕性能、功能、价格之类的因素在演变,我们今天看到的商业存储,服务于我们传统的 B 端业务需要,应该说非常成熟了。
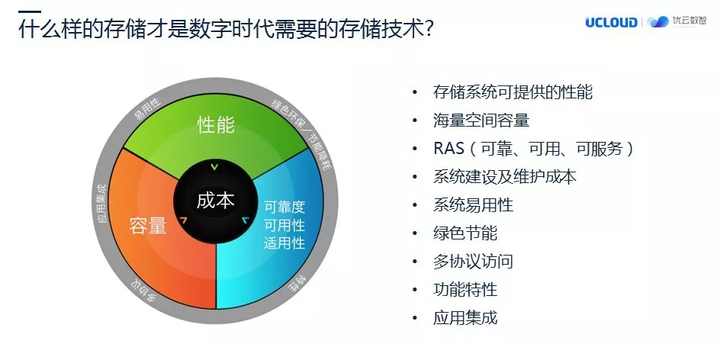
但是这些数字技术产生的数据量极其庞大,我们以前存储产品里面的很多技术特性应该说都没法使用了。例如:PB 级别的数据怎么保护?现在的虚拟带库技术就不能很好解决这个问题。PB 级别的数据到底需要使用几个存储控制器才能提供业务系统需要的性能?所以说,以前不是问题的问题,今天都成问题了。
一个偶然的机会让我看到了数字时代的存储技术可能应该怎么走下去,去年我们拿下一个非常重要的项目,为一位重量级的客户建设数十 PB 级别的分布式存储系统。这个存储系统为他们的私有云提供存储服务,存储私有云里面的虚拟机镜像数据、关系型数据库的数据,还有非结构化类的数据。
就一般项目的发展来说,分布式存储与私有云一旦结合基本上就告一段落了。但是,当在进行技术讨论的时候,讨论到“云是否可以作为大数据环境的基础资源供应”这个问题时,我们看到了变化。
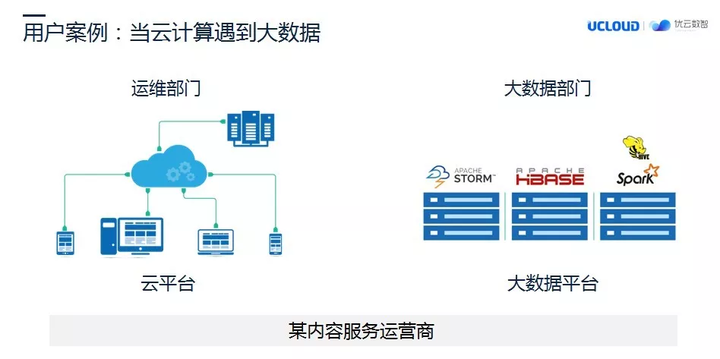
现在很多大型企业,都有私有云和大数据系统,但是私有云往往归基础运维的部门负责,而大数据业务因为偏向业务端,所以大数据系统的资源往往也是由大数据部门独立管理。
**但是,也有一种情况,需要将私有云和大数据系统进行统一管理。**在这种需求的驱动下,就诞生了 “大数据上云”的思路,在提供必要性能的前提下,充分发挥云计算的弹性特点。基于这种需求,我们开始调研这种技术实现的可能性。
面向计算存储分离的 Hadapter 解决方案 计算存储融合 – HDFS
我们首先看看传统的大数据的存储部署形态,大家知道 Hadoop 技术底层采用了 HDFS 文件系统,这种文件系统是模仿 Google 的 GFS 出现的一种分布式文件系统。今年,超融合系统这个概念比较火,应该说 HDFS 这种存储文件系统是最早向我们展现什么是超融合的技术。

HDFS 的出现导致了一个结果,就是商用存储在大数据环境下基本上无用武之地。各个主流商用存储厂商,如:EMC、NetApp 等主流存储厂商都有大数据解决方案,但是在我的印象里面,没有遇到过哪个客户在 Hadoop 上面使用商用存储。大家都使用 HDFS,为啥?性能好,便宜。随着大数据技术的普及,一个企业有多套 Hadoop 集群环境的情况越来越普遍,为大数据环境的资源争抢、集群扩容、数据集复制等等这些都变成了问题。
计算存储分离实践– EMR
那么有没有人做过“大数据上云”的事呢?有的。因为公有云规模大的特点,“大数据上云”这个问题其实在公有云计算公司就遇到了。我们看下面这张图,AWS 就是最早做这种尝试的。

AWS 有个 EMR 大数据处理服务。它就采用了计算存储分离的存储模型,将大数据处理的数据存储在 AWS 的 S3 对象存储里面,这种模型的好处就是计算和存储的扩展都是独立的,弹性很好;同时存储的利用率会得到很大提升,资源的“放”和“收”很好解决。
但是这种存储模型有个问题,数据的存取路径必须通过对象服务的网关,再由网关服务把 IO 请求递交给底层的对象存储设备。所以,一方面,这个网关增加了 IO 访问路径的开销;另一方面,这个网关比较容易成为系统的性能瓶颈。
基于 Hadapter 的计算存储分离方案
所以,我们就在想有没有一种方法,既能有计算存储分离模型的好处,又能保证大数据环境的存储访问性能。我们的灵感是来源于 NFS-Ganesha 这款软件,NFS-Ganesha 能支持多种后台存储系统,其中就包括 Ceph 的对象存储服务。
如下图所,示 NFS-Ganesha 使用了 librgw 实现对 Ceph 对象存储的访问,librgw 是一个 Ceph 提供的函数库,通过这个函数库可以让用户端通过函数调用来直接访问 Ceph 的对象存储服务。也就是说 librgw 可以将客户端请求直接转化成 Ceph 的 librados 请求,然后通过 socket 与 OSD 通信,如此我们可以不需要发送 HTTP 请求给对象存储网关,直接让对象存储网关与 OSD 之间通信完成一次访问。无疑,通过 librgw 的 IO 访问路径效率是优于对象存储网关的。
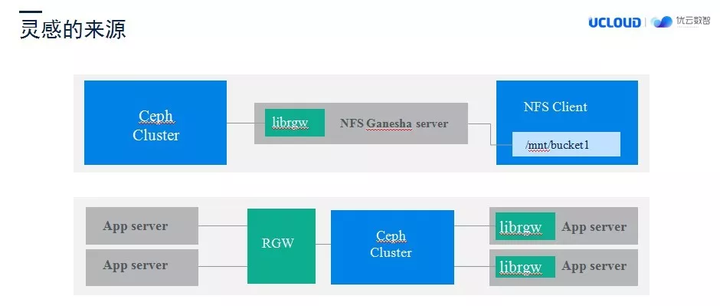
基于这种思考我们围绕 librgw 内核,打造了一款基于优云数智存储系统的 Hadoop 插件 – Hadapter。Hadapter 插件部署在 Hadoop 的客户端上,当 Hadoop 的客户端发送以 uds://为前缀的请求时,Hadoop 集群就会将请求下发给 Hadapter,然后通过我们的函数库直接调用 librados 函数库来请求 OSD,从而完成一个请求的处理操作。
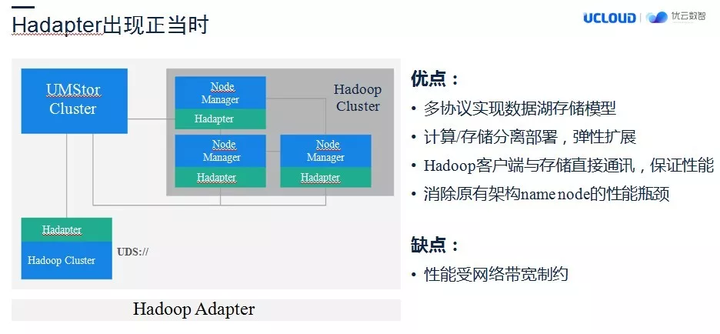
这样做有什么好处呢?首先,这是一种计算存储分离的模型,所以,在图上列的独立扩展这些好处都会具备;其次,在性能这块,这种存储模型优于直接使用对象存储的模型,后面有一些具体的性能数据。当然,这样一个存储模型,它的最大性能还是会受限于客户网络的现状。
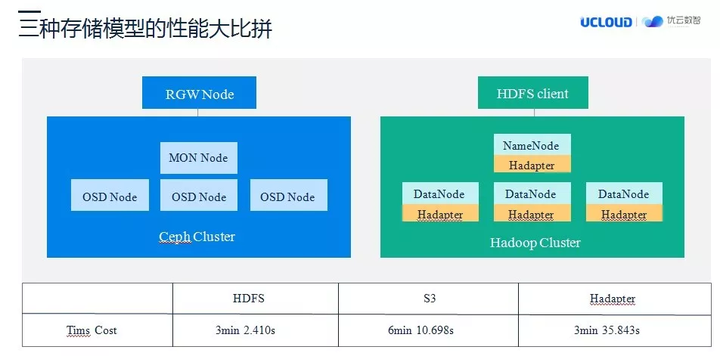
那么让我们看一下在大数据场景下三种存储模型的性能之间有什么差异?我们做了一些预研性质的性能对比,在相同的处理条件下。HDFS 性能还是最好的,而使用对象存储的情况下,时间是最长的,基本上是一倍的开销,这是符合我们的认识的。二使用 Hadapter 的时间开销略逊于 HDFS 的开销,但是远超过直接使用对象存储的模式。
项目到这里,我们和客户也基本达成了一致的技术构想,就是在优云数智自研的 UMStor 存储上配合 Hadapter 技术去实现“大数据上云”。最后,我们在云计算环境中,抽出 100 台以上的节点规模,作为 Hadoop 的客户端。
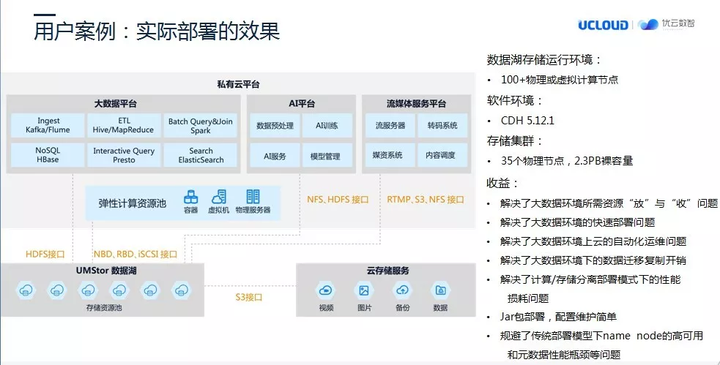
开始部署时,我们采用的是物理节点,因为性能达到预期,后面变成了物理+虚拟的混合节点部署模式,最近在考虑全虚拟化节点。这样一个生产化部署,实现效果基本和我们的预期基本是一致的。采用计算和存储分离的模型,解决了大数据环境所需资源“放”与“收”问题,并且在数据管理这块会变得非常容易。因为 Hadapter 是一个 jar 包,所以在安装部署和后期维护上会非常简单。
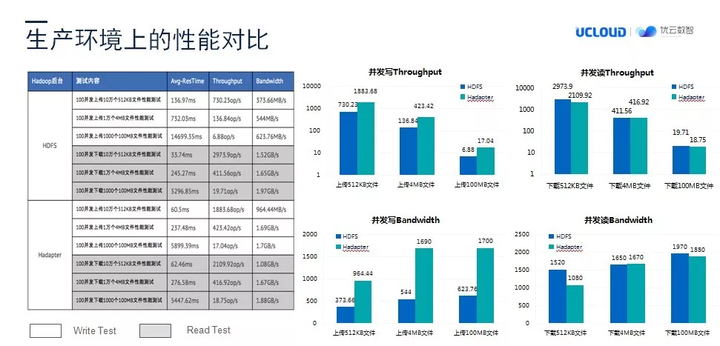
在预研时候,我们做了一个性能的对比,在实际生产环境下,我们又做了一次性能的效果对比。图上的数据是和客户之前使用的 HDFS 环境做的对比。在使用 Hadapter 后,在大部分场景下,大数据环境性能的表现还是很出色的。当然,还是之前的判定,如果希望跑出更好的大数据环境性能,可能要考虑一下对 IP 网络的改造。
大数据处理流程重塑
在我们的 UMStor 多协议分布式存储系统具体使用的过程中,我们还演化出一种新的大数据存储架构,也就是我们称为数据湖存储架构。数据湖是大数据厂商提的一种新的概念,面向多数据源的信息存储。
传统大数据环境下,数据的存储和处理需要大约 9 个步骤实现数据的汇聚和处理及使用。其中数据会分散在不同的存储设备上,这期间带来了对数据的大量管理工作,例如:数据的转存可能就会产生不小的开销。
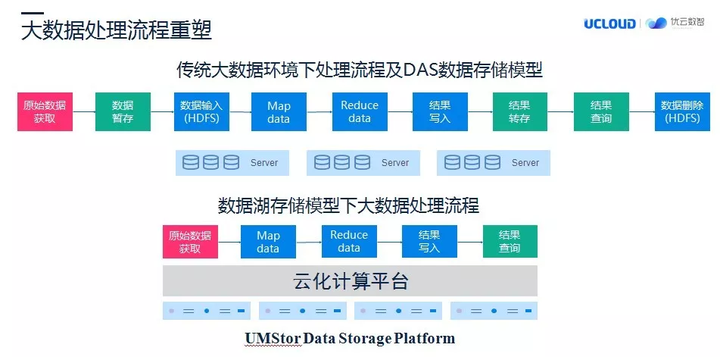
我们自己研发的 UMStor 分布式存储,是一种多协议的分布式存储,它底层是对象存储,除了 Hadapter,我们还提供了 NFS 网关,iSCSI 等接口形态,所以在大数据场景下,UMStor 可以作为数据交换平台存在,实现一次写入、多次访问的使用效果,这种使用方式帮助我们构建了一种数据湖的存储模型的出现。正如图上的显示,我们实现了大数据环境下的处理效率的提升。
关于存储技术的未来展望
讲到这里,我们回到前面谈的话题,数字时代需要什么样的存储技术?下图是一个企业数据冰山的模型,一家企业里面,随着时间的推移,会沉淀大量的数据,其中经常频繁使用的数据我们可以称为“明数据”,但是还有更为大量的数据正散落在不同品牌的商业存储、虚拟磁带库、直连存储之类的存储设备上,这类数据我们称之为“暗数据”。
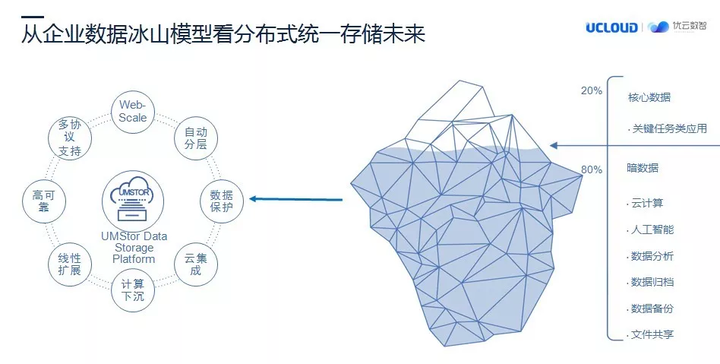
随着云计算、大数据和人工智能等技术的兴起,这些数据伴随新产生的数据,很可能就是云计算、大数据、人工智能所需要的数据。因为散落的原因,暗数据的使用变得异常困难。今天,我们可以通过多协议的分布式统一存储技术将这些数据整合起来,结合数字技术可以重新挖掘这些数据的潜在价值,正如我们将 UMStor 与 Hadoop 的结合就是这种思维的体现。
结合这阶段我们在项目中的体会和思考,以及分布式存储的特性,我们认为下一个阶段存储技术的创新必然是围绕分布式统一存储与新型数字技术的结合来展开。
如需演讲 PPT,请微信关注“ UCloud 技术公告牌”下载。
目前尚无回复