
这是一个创建于 2622 天前的主题,其中的信息可能已经有所发展或是发生改变。
有不少朋友在开发爬虫的过程中喜欢使用 Selenium + Chromedriver,以为这样就能做到不被网站的反爬虫机制发现。
先不说淘宝这种基于用户行为的反爬虫策略,仅仅是一个普通的小网站,使用一行 Javascript 代码,就能轻轻松松识别你是否使用了 Selenium + Chromedriver 模拟浏览器。
我们来看一个例子。
使用下面这一段代码启动 Chrome 窗口:
from selenium.webdriver import Chrome
driver = Chrome()
现在,在这个窗口中打开开发者工具,并定位到 Console 选项卡,如下图所示。
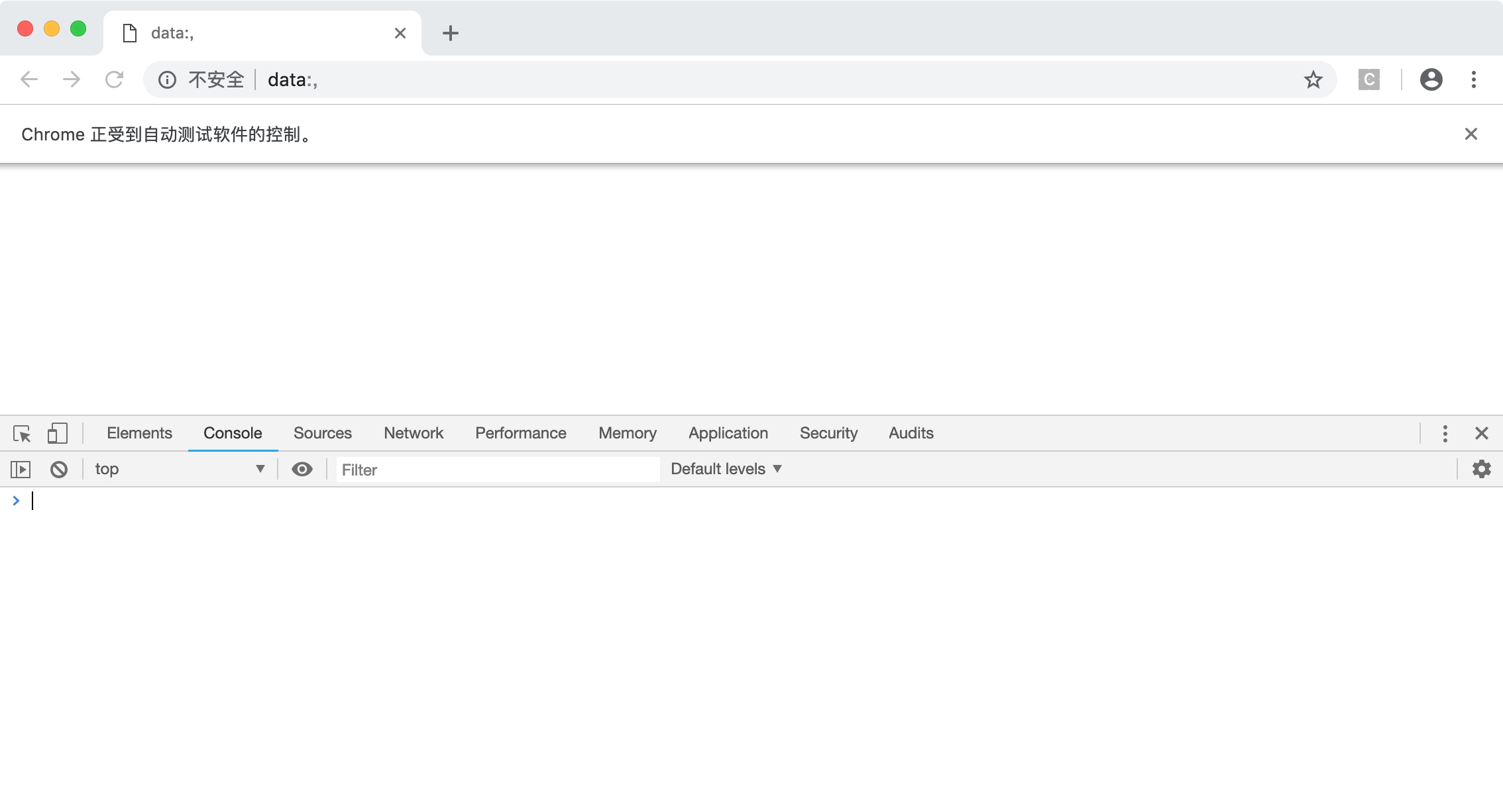
现在,在这个窗口输入如下的 js 代码并按下回车键:
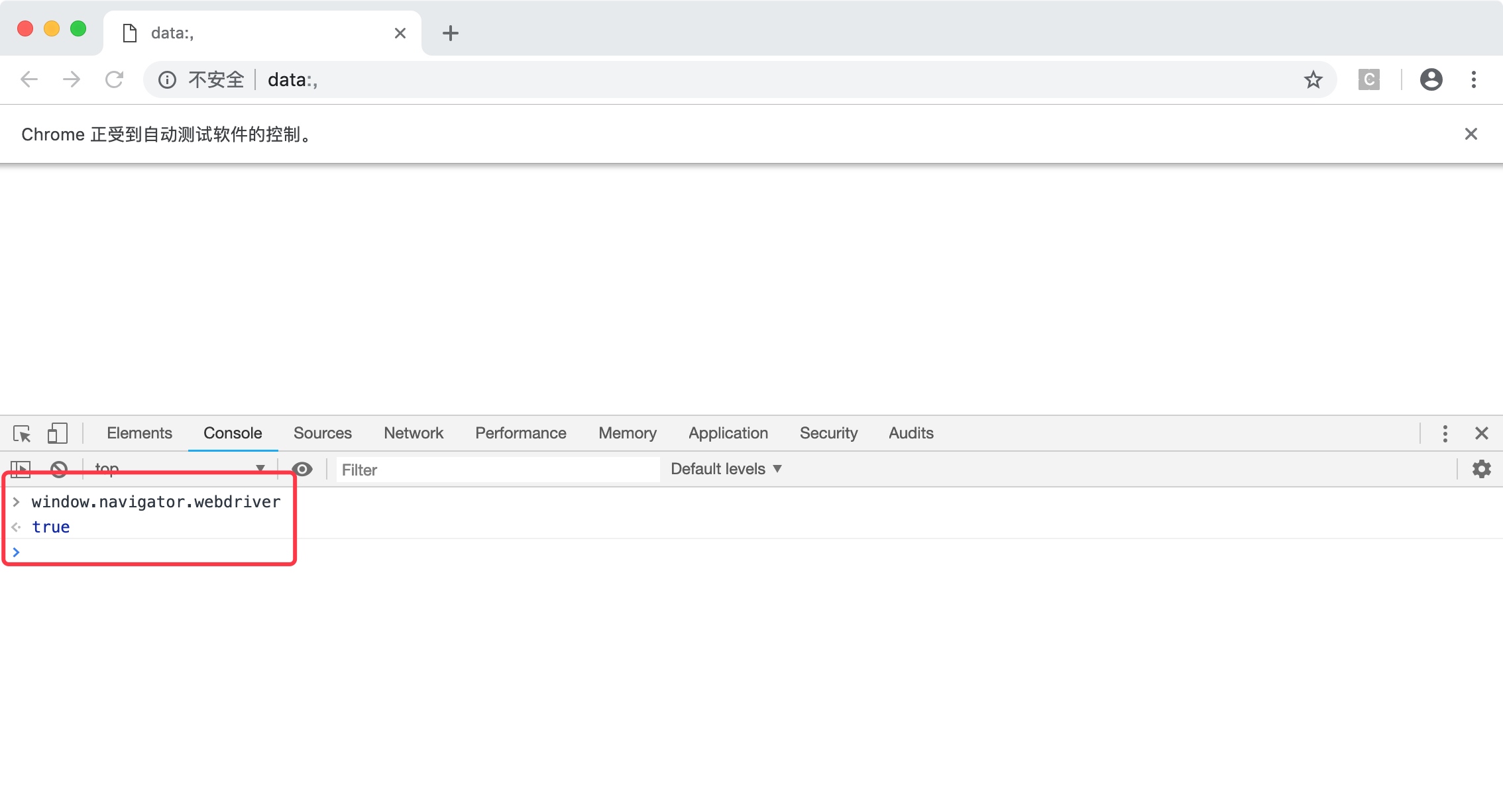
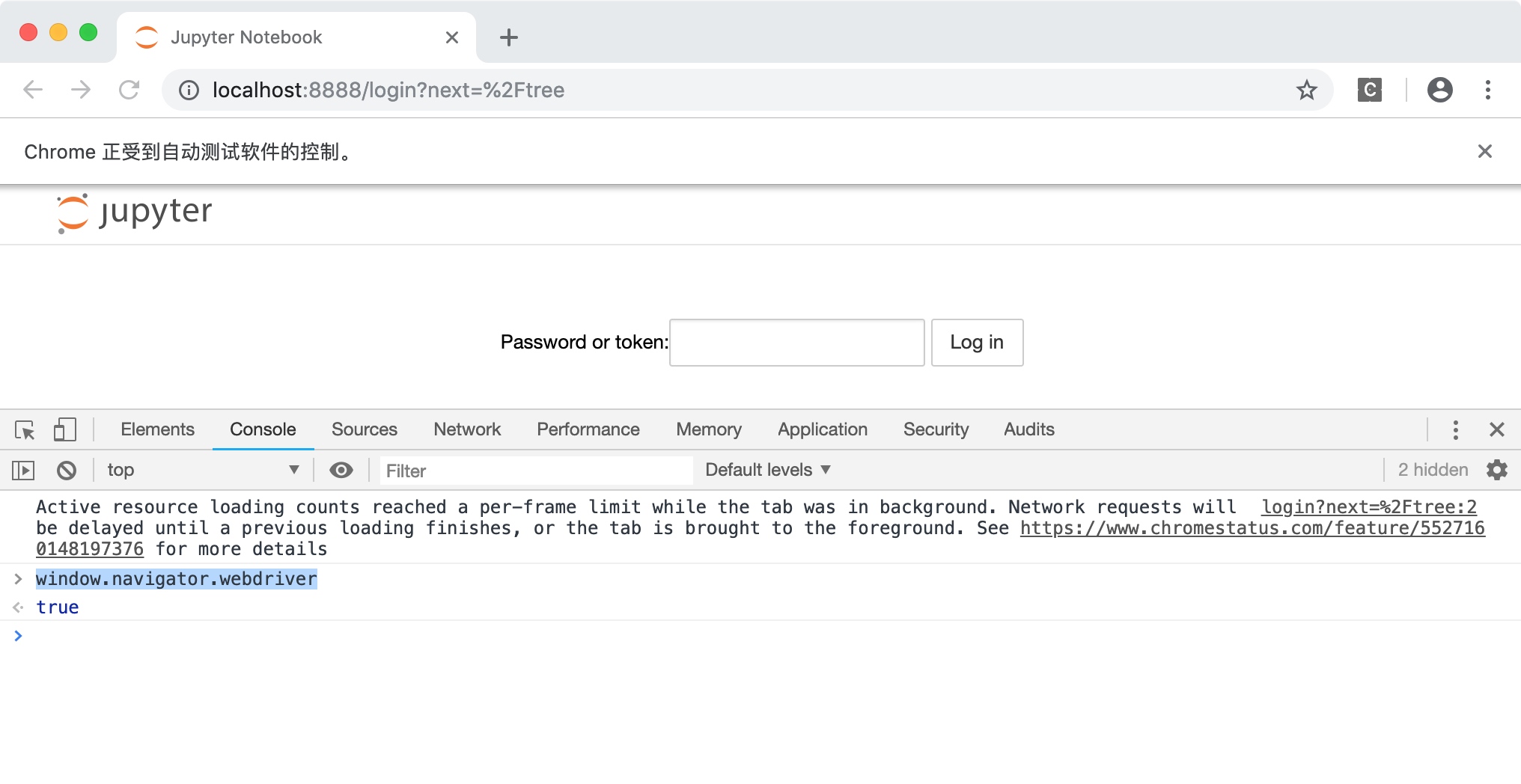
window.navigator.webdriver
可以看到,开发者工具返回了true。如下图所示。
但是,如果你打开一个普通的 Chrome 窗口,执行相同的命令,可以发现这行代码的返回值为undefined,如下图所示。
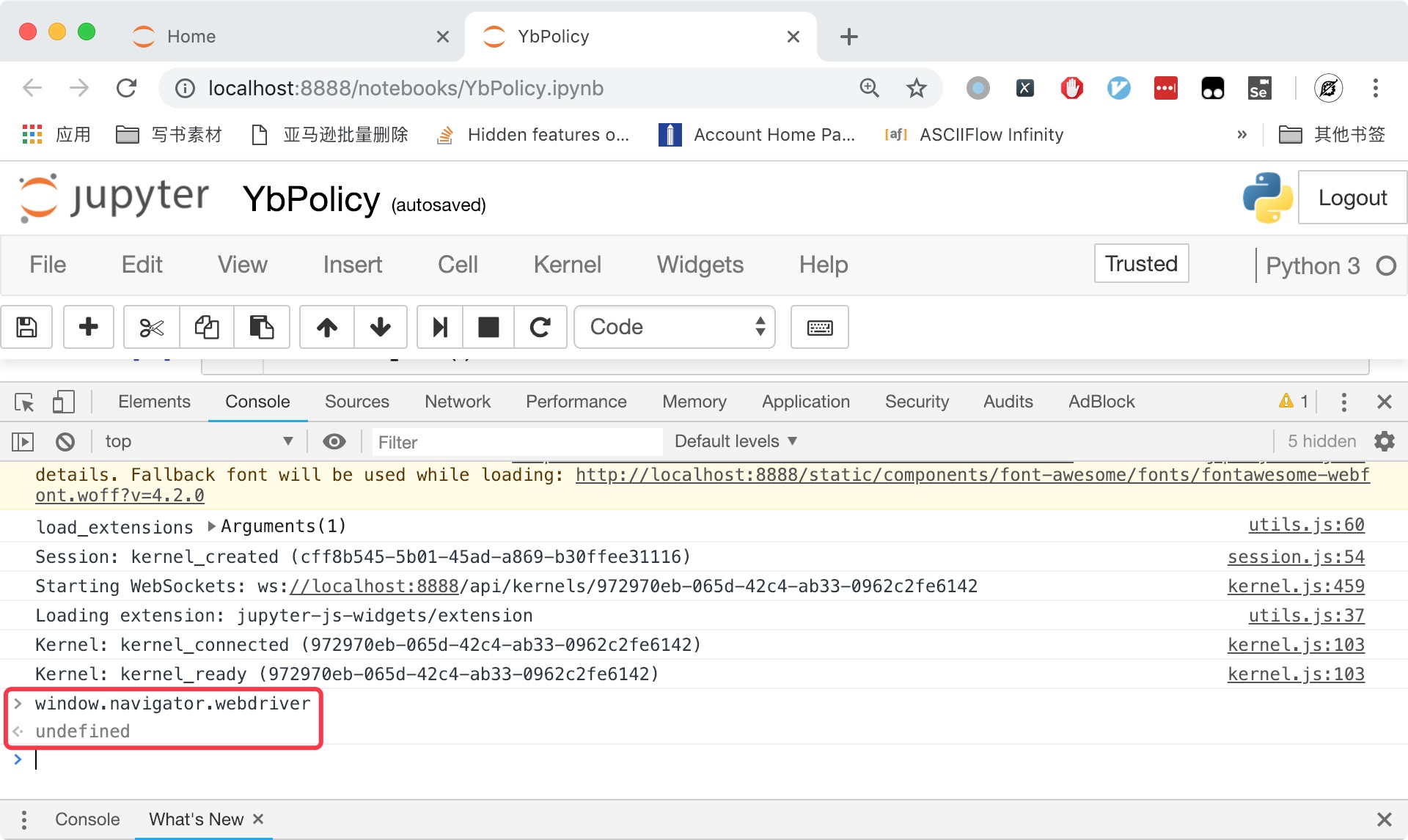
所以,如果网站通过 js 代码获取这个参数,返回值为undefined说明是正常的浏览器,返回true说明用的是 Selenium 模拟浏览器。一抓一个准。这里给出一个检测 Selenium 的 js 代码例子:
webdriver = window.navigator.webdriver;
if(webdriver){
console.log('你这个傻逼你以为使用 Selenium 模拟浏览器就可以了?')
} else {
console.log('正常浏览器')
}
网站只要在页面加载的时候运行这个 js 代码,就可以识别访问者是不是用的 Selenium 模拟浏览器。如果是,就禁止访问或者触发其他反爬虫的机制。
那么对于这种情况,在爬虫开发的过程中如何防止这个参数告诉网站你在模拟浏览器呢?
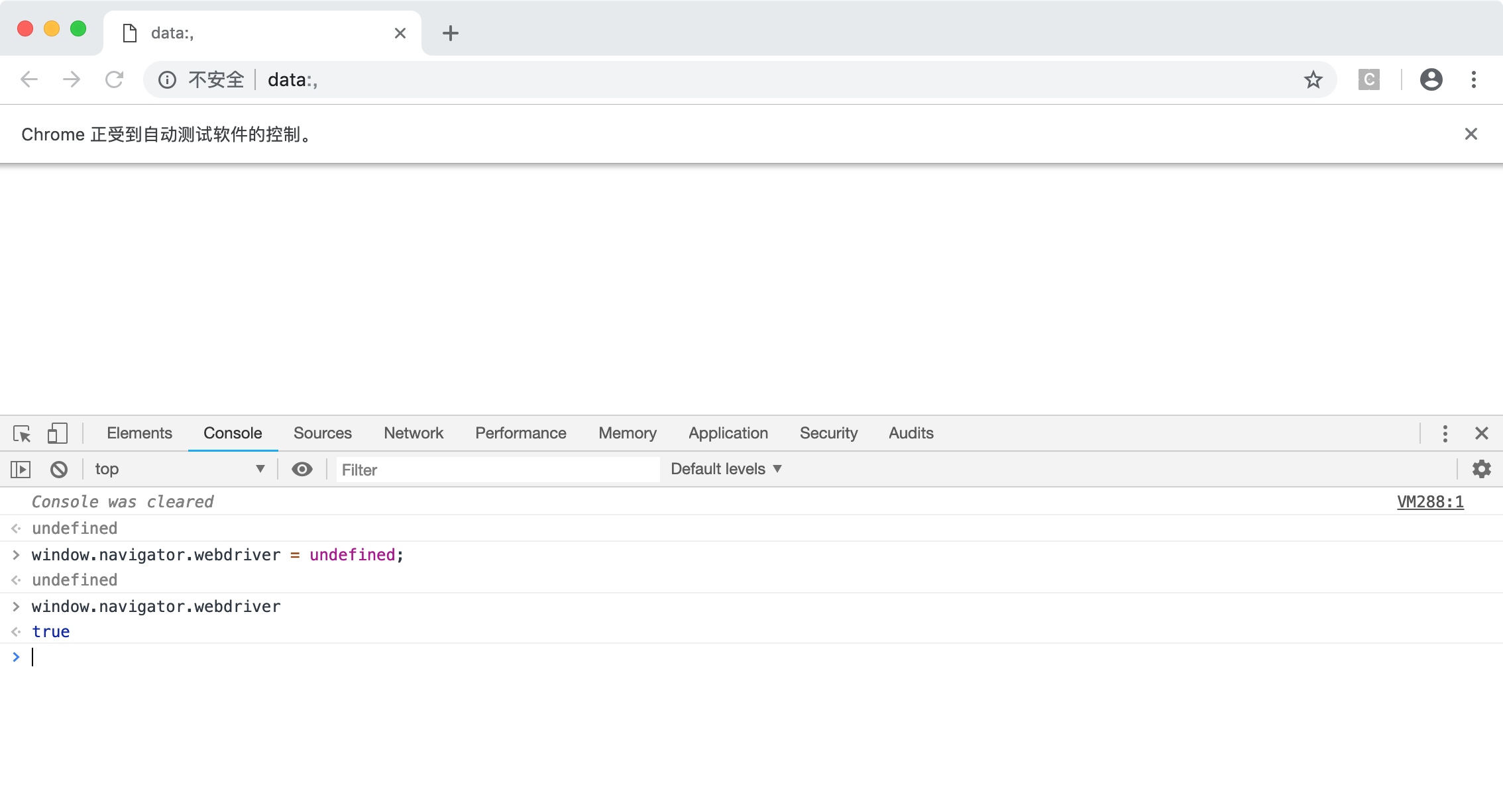
可能有一些会 js 的朋友觉得可以通过覆盖这个参数从而隐藏自己,但实际上这个值是不能被覆盖的:
对 js 更精通的朋友,可能会使用下面这一段代码来实现:
Object.defineProperties(navigator, {webdriver:{get:()=>undefined}});
运行效果如下图所示:
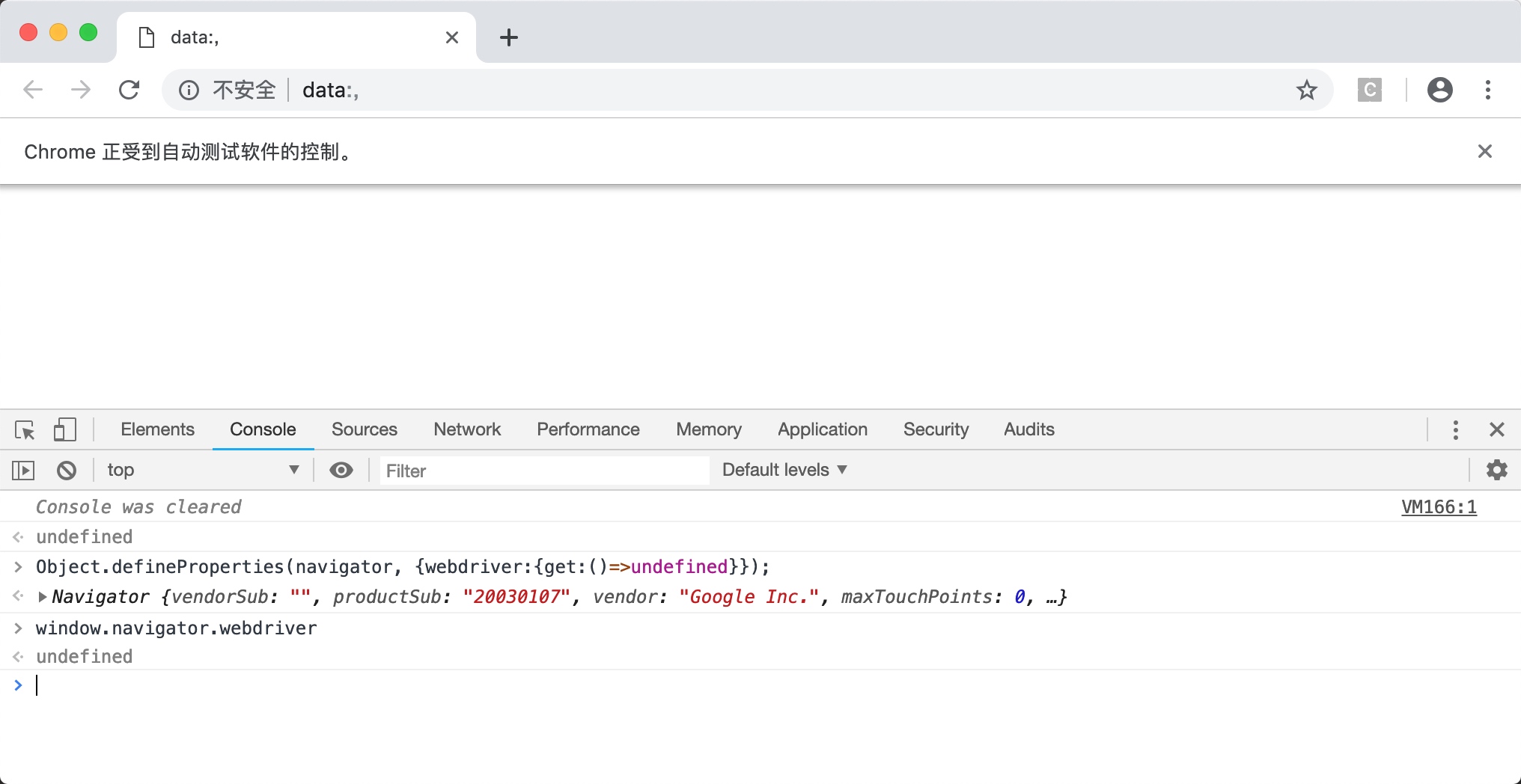
确实修改成功了。这种写法就万无一失了吗?并不是这样的,如果此时你在模拟浏览器中通过点击链接、输入网址进入另一个页面,或者开启新的窗口,你会发现,window.navigator.webdriver又变成了true。如下图所示。
那么是不是可以在每一个页面都打开以后,再次通过 webdriver 执行上面的 js 代码,从而实现在每个页面都把window.navigator.webdriver设置为undefined呢?也不行。
因为当你执行:driver.get(网址)的时候,浏览器会打开网站,加载页面并运行网站自带的 js 代码。所以在你重设window.navigator.webdriver之前,实际上网站早就已经知道你是模拟浏览器了。
接下来,又有朋友提出,可以通过编写 Chrome 插件来解决这个问题,让插件里面的 js 代码在网站自带的所有 js 代码之前执行。
这样做当然可以,不过有更简单的办法,只需要设置 Chromedriver 的启动参数即可解决问题。
在启动 Chromedriver 之前,为 Chrome 开启实验性功能参数excludeSwitches,它的值为['enable-automation'],完整代码如下:
from selenium.webdriver import Chrome
from selenium.webdriver import ChromeOptions
option = ChromeOptions()
option.add_experimental_option('excludeSwitches', ['enable-automation'])
driver = Chrome(options=option)
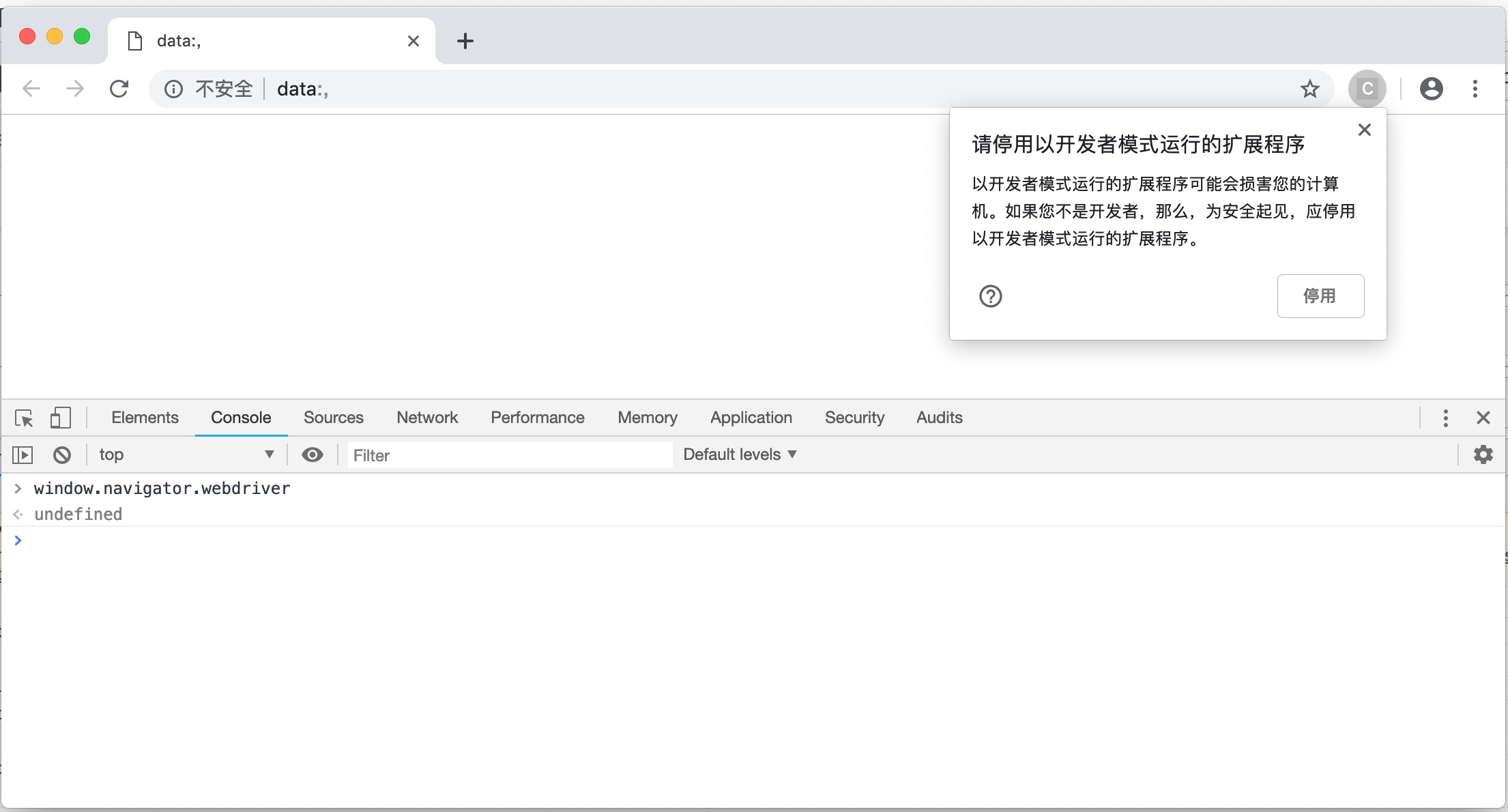
此时启动的 Chrome 窗口,在右上角会弹出一个提示,不用管它,不要点击停用按钮。
再次在开发者工具的 Console 选项卡中查询window.navigator.webdriver,可以发现这个值已经自动变成undefined了。并且无论你打开新的网页,开启新的窗口还是点击链接进入其他页面,都不会让它变成true。运行效果如下图所示。
截至 2019 年 2 月 12 日 20:46 分,本文所讲的方法可以用来登录知乎。如果使用 Selenium 直接登录知乎,会弹出验证码;先使用本文的方法再登录知乎,能够成功伪装成真实的浏览器,不会弹出验证码。
Selenium + Chromedriver 能被检测的特征还有很多个,对于如何隐藏其他特征,请关注后续的文章,或者关注我的微信公众号提前阅读~
 |
1
itskingname OP 为什么尽是收藏没有评论?
|
 |
2
lhx2008 2019 年 2 月 12 日 via Android
总算有人讲到点子上了,之前在网上找没有收获
|
 |
3
panyanyany 2019 年 2 月 12 日
我都是 puppeteer 直接调用 chrome/chromium 浏览器的,这种问题应该不存在了。
|
 |
4
terranboy 2019 年 2 月 12 日
现在都用 puppeteer 了 能讲讲怎么反 puppeteer 和反反 puppeteer 吗
|
|
5
itskingname OP @terranboy 可以。
|
 |
6
jugelizi 2019 年 2 月 12 日
重新编译下驱动即可啊
|
|
7
itskingname OP @jugelizi 那样会很麻烦。chromedriver 里面可以被识别的特征有十几个。全部修改再编译,难度太大。
|
|
8
itskingname OP @panyanyany puppeteer 默认调用的是 chromium,你如何让它调用 chrome ?
|
 |
9
murmur 2019 年 2 月 12 日
@itskingname 难度不大去爬淘宝这种直接就趴窝
|
 |
10
danbao 2019 年 2 月 12 日
@itskingname
const browser = await puppeteer.launch({executablePath: '/path/to/Chrome'}); |
|
11
itskingname OP @danbao 我去测试一下~
|
 |
12
Nimrod 2019 年 2 月 12 日 via Android
谢谢楼主,讲得很清楚。
|
 |
13
testsec 2019 年 2 月 12 日 via iPhone
公众号在哪
|
 |
14
mywaiting 2019 年 2 月 12 日
搞得这么麻烦,多数的网站对于直接 chrome extension 处理的 webRequest 修剪的流量是没有防御能力的,尤其是你这样的基于 JS 的防御,直接无视
|
|
15
itskingname OP |
 |
16
v2chou 2019 年 2 月 13 日
就喜欢这种爬虫与反爬虫
|
|
17
itskingname OP @v2chou 还有更多~
|
 |
18
forever139 2019 年 2 月 13 日
支持一个
|
 |
19
imdoge 2019 年 2 月 13 日 await page.evaluateOnNewDocument(() => {
Object.defineProperty(navigator, "webdriver", { get: () => false }); }); puppeteer 这样写可破 |
|
20
imdoge 2019 年 2 月 13 日
不需要插件和设置浏览器
|
 |
21
zxcvsh 2019 年 2 月 13 日 via iPhone
问一下楼主,
selenium chrome 怎么实现页面缩放功能,找了很多资料几乎无效(ctrl +- 的百分比缩放) |
|
22
itskingname OP @imdoge 当你进入一个新的页面的时候,又得再执行一次。
|
|
23
itskingname OP @zxcvsh 非常简单。
```python driver = Chrome() driver.get('https://www.kingname.info') driver.execute_script("document.body.style.zoom='0.5'") # 缩小 driver.execute_script("document.body.style.zoom='1.7'") # 放大 ``` |
|
24
zxcvsh 2019 年 2 月 13 日 via iPhone
|
 |
25
garbch 2019 年 2 月 13 日
|
|
26
itskingname OP @garbch selenium 可以
|
|
27
garbch 2019 年 2 月 13 日
@itskingname 能给个例子吗? 多谢?
是不是要用了 devtool 了? |
 |
28
egen 2019 年 2 月 13 日
这波攻防可以
|
|
29
itskingname OP @garbch 你这里的截获是指跳转的最终 URL 还是中间的 URL ?例如 3 次跳转,你要第二次的 URL ?或者实际上你不像让它跳转?
|
|
30
garbch 2019 年 2 月 13 日
|
|
31
itskingname OP @garbch 如果只跳转 2 次,那么可以这样实现:
```python url = driver.execute_script('return window.document.referrer') print(url) ``` |
|
32
garbch 2019 年 2 月 14 日
|
|
33
itskingname OP @garbch 那你就要配合 mitmproxy 了。
|
 |
34
jiejiss 2019 年 2 月 14 日
It is *NOT* Possible to Detect and Block Chrome Headless
https://intoli.com/blog/not-possible-to-block-chrome-headless/ |
 |
35
aldorado 2019 年 2 月 16 日
所以微信公众号是多少
|
|
36
itskingname OP @aldorado 微信公众号搜索:itskingname 名字叫做未闻 Code
|
 |
37
no1xsyzy 2019 年 2 月 18 日
defineProperties 的方法可以用爆函数调用栈来检测,之前 v2 上有过检测 Proxy 的题,同理
|
|
38
itskingname OP @no1xsyzy 所以我最后给的办法才是万能的。
|
 |
39
LinJunzhu 2019 年 4 月 15 日
@itskingname 请问 firefox 的 driver 有这种解决方法么?
|
|
40
LinJunzhu 2019 年 4 月 15 日
|
|
41
LinJunzhu 2019 年 4 月 15 日
当时我尝试过写插件,在每次访问页面时都去改掉这个属性, 但是没效果,修改了之后,访问的页面打开控制台,还是可以访问到这个属性。
属于重新编译驱动,也尝试过,删除了几个特征码,但是关于这个特征码一直没找到源处。 |