SKlearn 简介
scikit-learn,又写作 sklearn,是一个开源的基于 python 语言的机器学习工具包。它通过 NumPy, SciPy 和 Matplotlib 等 python 数值计算的库实现高效的算法应用,并且涵盖了几乎所有主流机器学习算法。
SKlearn 官网链接: http://scikit-learn.org/stable/index.html
在工程应用中,用 python 手写代码来从头实现一个算法的可能性非常低,这样不仅耗时耗力,还不一定能够写出构架清晰,稳定性强的模型。更多情况下,是分析采集到的数据,根据数据特征选择适合的算法,在工具包中调用算法,调整算法的参数,获取需要的信息,从而实现算法效率和效果之间的平衡。而 sklearn,正是这样一个可以帮助我们高效实现算法应用的工具包。
sklearn 有一个完整而丰富的官网,里面讲解了基于 sklearn 对所有算法的实现和简单应用。
常用模块
sklearn 中常用的模块有分类、回归、聚类、降维、模型选择、预处理。

分类:识别某个对象属于哪个类别,常用的算法有:SVM (支持向量机)、nearest neighbors (最近邻)、random forest (随机森林),常见的应用有:垃圾邮件识别、图像识别。
回归:预测与对象相关联的连续值属性,常见的算法有:SVR (支持向量机)、ridge regression (岭回归)、Lasso,常见的应用有:药物反应,预测股价。
聚类:将相似对象自动分组,常用的算法有:k-Means、spectral clustering、mean-shift,常见的应用有:客户细分,分组实验结果。
降维:减少要考虑的随机变量的数量,常见的算法有:PCA (主成分分析)、feature selection (特征选择)、non-negative matrix factorization (非负矩阵分解),常见的应用有:可视化,提高效率。
模型选择:比较,验证,选择参数和模型,常用的模块有:grid search (网格搜索)、cross validation (交叉验证)、metrics (度量)。它的目标是通过参数调整提高精度。
预处理:特征提取和归一化,常用的模块有:preprocessing,feature extraction,常见的应用有:把输入数据(如文本)转换为机器学习算法可用的数据。
安装 SKlearn
安装最新版本
Scikit-learn 需要:
- Python (> = 2.7 或> = 3.4 ),
- NumPy (> = 1.8.2 ),
- SciPy (> = 0.13.3 )。
[注意] Scikit-learn 0.20 是支持 Python 2.7 和 Python 3.4 的最后一个版本。Scikit-learn 0.21 将需要 Python 3.5 或更高版本。
如果你已经安装了 numpy 和 scipy,那么安装 scikit-learn 的最简单方法就是使用 pip或者canda
pip install -U scikit-learn
conda install scikit-learn
如果你尚未安装 NumPy 或 SciPy,你也可以使用 conda 或 pip 安装它们。使用 pip 时,请确保使用binary wheels,并且不会从源头重新编译 NumPy 和 SciPy,这可能在使用特定配置的操作系统和硬件(例如 Raspberry Pi 上的 Linux )时发生。从源代码构建 numpy 和 scipy 可能很复杂(特别是在 Windows 上),需要仔细配置以确保它们与线性代数例程的优化实现相关联。为了方便,我们可以使用如下所述的第三方发行版本。
发行版本
如果你还没有 numpy 和 scipy 的 python 安装,我们建议你通过包管理器或通过 python bundle 安装。它们带有 numpy,scipy,scikit-learn,matplotlib 以及许多其他有用的科学和数据处理库。
可用选项包括:Canopy 和 Anaconda适用于所有支持的平台
除了用于 Windows,Mac OSX 和 Linux 的大量科学 python 库之外,Canopy和Anaconda都提供了最新版本的 scikit-learn。
Anaconda 提供 scikit-learn 作为其免费发行的一部分。
[注意] PIP 和 conda 命令不要混用!!!
要升级或卸载 scikit-learn 安装了 python 或者conda你不应该使用 PIP 命令。
升级scikit-learn:conda update scikit-learn
卸载scikit-learn:conda remove scikit-learn
使用pip install -U scikit-learn安装或者使用pip uninstall scikit-learn卸载可能都没有办法更改有 conda 命令安装的 sklearn。
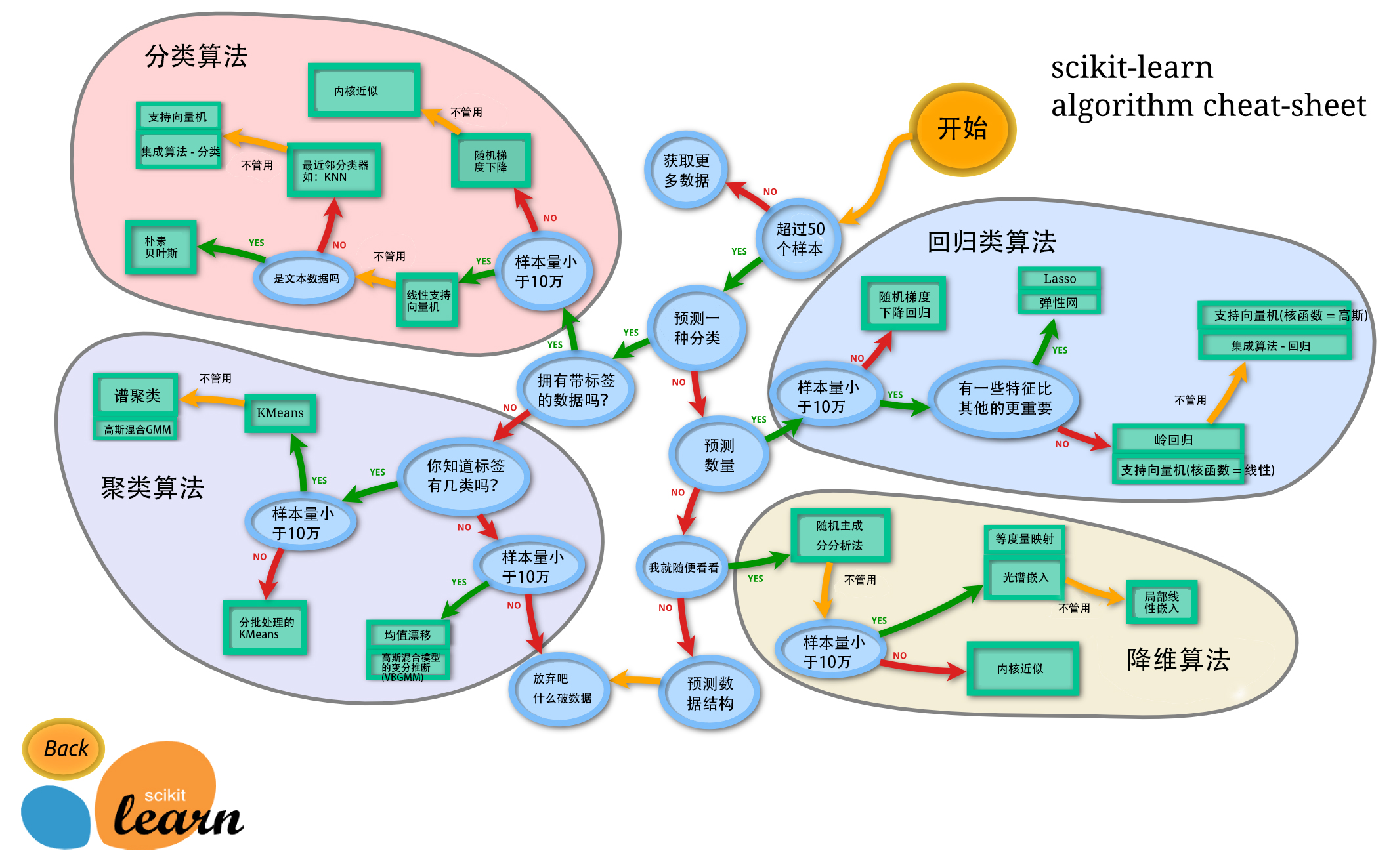
算法选择
sklearn 实现了很多算法,面对这么多的算法,如何去选择呢?其实选择的主要考虑的就是需要解决的问题以及数据量的大小。sklearn 官方提供了一个选择算法的引导图。
https://scikit-learn.org/stable/tutorial/machine_learning_map/index.html
这里提供翻译好的中文版本,供大家参考: