推荐学习书目
› Learn Python the Hard Way
Python Sites
› PyPI - Python Package Index
› http://diveintopython.org/toc/index.html
› Pocoo
值得关注的项目
› PyPy
› Celery
› Jinja2
› Read the Docs
› gevent
› pyenv
› virtualenv
› Stackless Python
› Beautiful Soup
› 结巴中文分词
› Green Unicorn
› Sentry
› Shovel
› Pyflakes
› pytest
Python 编程
› pep8 Checker
Styles
› PEP 8
› Google Python Style Guide
› Code Style from The Hitchhiker's Guide

这是一个创建于 2353 天前的主题,其中的信息可能已经有所发展或是发生改变。
Attention Is All You Need
还在用 RNN 做 NLP ? NLP 迎来新纪元了!快来学习下现在最火的 BERT 用的 Transformer 模型吧。
谷歌团队在 18 年提出的用于生成词向量的 BERT 算法在 NLP 的 11 项任务中取得了效果的大幅提升,堪称 2018 年深度学习领域最振奋人心的消息。而 BERT 算法的最重要的部分谷歌团队在 17 年发表的论文《 Attention Is All You Need 》中提出的 Transformer 的概念。
首先我们来复习下基于 RNN 的 Seq2Seq 模型中的 attention 机制,来通过下面的动画来大概了解下 attention 机制是用来干嘛的。
在机器翻译中常用的 Seq2Seq 模型中,加入 attention 机制是将每一个 encoder 的 RNN 的隐层都传递给 decoder,decoder 再做如下的 attention 分析,

下图是 attention 分析的细节:

Attention 机制就是将 decoder 的 hidden
state 和与每一个 encoder 的 hidden
state 的做一个匹配程度的分析,然后给出一个评分,这里评分的机制有很多,可以用一个小的网络也可以用线性计算,然后将这些 score
用 Softemax 归一化,再和相对应的 hi 相乘,再把所有的 hi 累加起来形成新的 hidden state。也就是说,评分高的 hidden
state 所占的比重多,评分低的就占比少。
先初始化一个 hidden state 和一个 end
标记的向量作为输入,得到一个 hidden state: h4, 再把 h4
和之前在 encoder 里面得到的所有隐藏状态 h1,h2,h3 做 attention 分析,得到最后的 C4,然后将 C4 和 h4 拼起来一起输入到一个前馈网络得到第一个词的输出。接下来就是将第一层的输出和得到的 h4,作为下一层的输入,做同样的操作,一直这样继续下去直到输出 end 标记。

<br />在对 attention 有一个大概的概念之后,我们来正式讲下这篇论文,论文作者提出了一个 Transformer 的模型,这个模型的特点主要在它是完全基于 attention 机制来做 NLP,直接放弃了 RNN 和 CNN,也就是为什么这篇论文叫 Attention Is All You Need 的原因。放弃了 RNN 之后有一个很大的好处就是整个模型在训练的时候有更好的并行性,训练时间可以大大减少,因为用 RNN 模型的时候在 encoder 里面单词都要一个一个顺序输入,而在如果用 Transformer 可以直接输入一句句子。模型结构如下图所示:<br /> 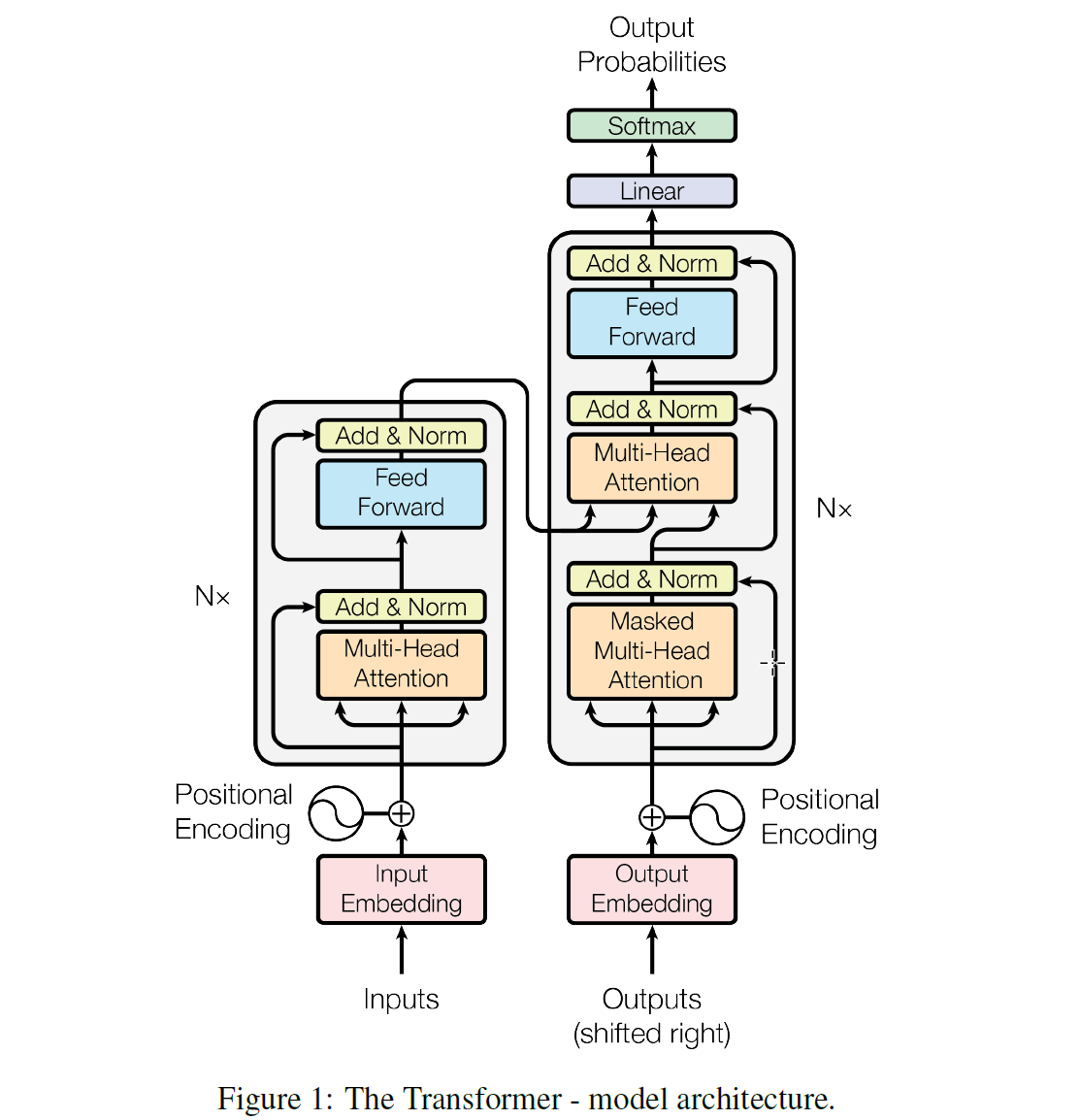<br />这个模型看上去很复杂,其实相对于 RNN,要更简单一点,下面我们一点一点讲。<br />在 Transformer 中同样的有 encoders 和 decoders,encoder 对输入进行编码,decoder 对编码得到的结果进行解码,下图以黑盒的形式表现了模型的主要结构,输入被传输进 encoder,encoder 会传出一部分内容到 decoder,也会传一部分内容到下一层的 encoder,encoder 和 decoder 都有一个 Self-Attention 模块和 一个前馈网络模块,decoder 比 encoder 多一个 Encoder-Decoder Attention 模块,<br /> 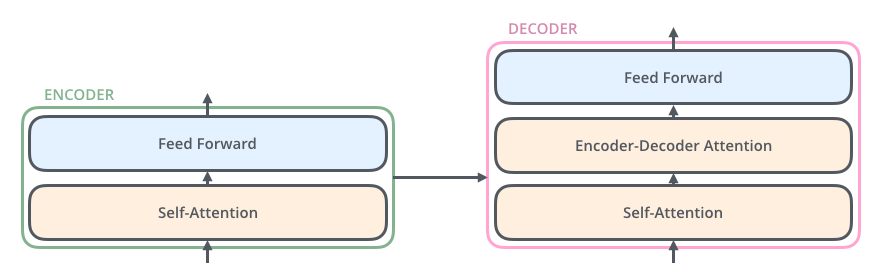<br />这里的 Self-Attention 模块是整个结构的核心,我们先用一个例子来帮助大家理解下什么是 Self-Attention:<br />这里有句句子:The animal didn't cross the street because it was too tired <br />要让计算机理解这句句子,需要让计算机搞清楚里面的
it 是指代那个单词,是 street 还是 animal ?也就是给输入的句子中每个单词之间一个相关性程度的判定。前文 RNN 的例子中的 attention 是输入与输出之间的 attention,而 self-attention 是句子内部之间的 attention。通过 attention 机制我们可以得到如下图的词汇之间的关联程度,It 与 The animal 关联程度最高。

在大概理解了什么是 Self-Attention 之后我们来看论文中作者是如何设计模型来做这种机制的。作者将设计的模型称为 Scaled Dot-Product Attention,如下图所示作者从输入中提取出了三个矩阵:Q,K,V。通过如下公式来做 Self-Attention 分析。


我们以机器翻译的例子来看这三个矩阵是如何提取的:

在这个例子中,首先利用 word embedding 技术将句子的词汇转换成向量,得到这里 x1,x2 向量作为模型的输入,论文里面的标准模型的词向量是 512 维,然后利用每个 xi 向量构建出三种向量:q (Query) , k (Key) ,v(Value),构建方法是用 xi 对这里的
Wq , Wk 和
Wv 三个矩阵做内积,这里矩阵里面的数值也是作为参数学出来的。得到的三种向量他们的维度是可以和输入的 xi 不一样的,论文里面用的是 64。然后下图是评分的机制:

将每个 q 向量分别与其他所有 k 向量做内积,得到所有有向量在这个 qi 位置上所占的比重。也就是我们要的 Score,得到的 score 就代表了每个向量在当前位置所占的权值,然后为了让学习过程中的 gradient 更加稳定,作者将这些 score 做了一个缩放(除以根号 dk ),接下来就是把这些得到的新的 scores 去乘对应单词的 value 向量,最后再总的加起来得到这里的
z1 也就是我们要处理的 Attention 过后的结果。小编认为作者在这里给向量取的名字的意思是:q ( Query )是每个单词像其他所有单词做一个询问,而 k(Key)是蕴含了词汇之间关系的信息,给每个单词的 Query 提供关系数值。而 v(Value) 蕴含的是词汇信息。但这也只是小编的猜测,论文中作者并没有明确说明。数学模型上就只是简单的向量之间的内积。经过这样的例子相信上面的公式应该很好理解了:


在实际的模型中,作者对刚刚的模型做了进一步的改进,作者称这个模型为 Multi-head attention,整个模型主要就是将多个 Scale Dot-Product Attention 模型堆叠起来,组成成新的模型(每个小模型对应一个 head,所以叫 Multi-Head )如下图所示:

我们还是用上面那句话的例子来说明这样做的好处,如下图所示:

这张图是两个
head 得到的 attention 效果,可以看到 it 在一个 head 中主要把 attention 集中在 animal,而另一个集中在了 tired 上,很明显这样的对语义的理解是有帮助的。下面我们来看下具体结构:

和前面的模型一样,我们将输入做线性运算生成 Q,K,V 矩阵,不同的是我们这里定义 8 组不同的 Wq,Wk,Wv,生成八组不同的 Q,K,V 矩阵,也就是论文里说的
8 个 head,然后将 8 组不同的 QKV 用
这个公式生成 8 组
attention z0 到 z7,然后将 z0-z7 拼接起来和这里的 W0 做内积,得到最终的编码结果 Z ,用来输入到后面的前向网络。
聪明的你看到这里肯定会发现这个模型直接放弃 RNN 会有一个缺点就是丢失了一定的词汇的顺序信息,就是哪个单词在前哪个单词在后都是对句子的意思是有影响的。所以作者提出了用 Postional encoding 的方法来弥补这个不足。如下图所示:


当输入的词汇经过 embedding 之后得到的向量并不是直接输入模型,而是要加上一个位置信息的向量,位置向量的计算公式如上图所示,作者在论文中并没有具体讲为什么用这样的公式,只说了因为这里用的三角函数可以让不同位置的 PE 值相互线性表示。作者也尝试了通过学习的方法来做这个位置信息,并取得了同样好的效果,但是用这里的公式计算速度更快。
模型的核心 Self-Attention 到此就讲完了,我们下面来看看 encoders 和 decoders 是如何一起工作的:
Input
经过刚刚讲的一系列的 encode 过程后,我们将每一层 encoder 生成的 K 和
V 矩阵传给 decoder,然后 decoder 输出和之前的 RNN 模型一样也是一个词一个词的输出。

decoder 先对自己当前得到的内容做一个 self-attention,生成的编码过后的 z 输入到前馈网络,网络的输出再输入到下一层的 Encoder-Decoder Attention 模块(从图片中可以看出作者用在网络的设计上用了残差网络的结构,把输入加到输出再传给下一层),Encoder-Decoder Attention 模块的机构是和 Self-Attention 模块是一样的,只是在获取 Q , K , V 矩阵的时候,模块只对前一层的输入生成 Q 矩阵,而 K 和 V 矩阵从对应层的 encoder 中获取,也就是解码 encoder 中的内容。
当得到 decoder 的最后一层输出后,我们将输出进行一个线性运算和 softmax 归一化得到每个单词的概率,取概率最大的单词输出。如下图所示:
实验:
作者用这个模型做了英德的翻译,下图是不同超参数的模型之间效果的对比:

可以看出这里最后一行最大的模型在 BLEU 评分上得到了最好的效果。
同时作者也做了英法的翻译与其他模型进行了对比:

可以看出最大的 Transformer 模型不光是在 BLEU 评分上比 RNN\CNN 高,而且计算量也更加少。
点此观看论文相关直播课程
关于我们
Mo(网址:momodel.cn)是一个支持 Python 的人工智能在线建模平台,能帮助你快速开发、训练并部署模型。
Mo 人工智能俱乐部 是由网站的研发与产品设计团队发起、致力于降低人工智能开发与使用门槛的俱乐部。团队具备大数据处理分析、可视化与数据建模经验,已承担多领域智能项目,具备从底层到前端的全线设计开发能力。主要研究方向为大数据管理分析与人工智能技术,并以此来促进数据驱动的科学研究。
目前俱乐部每两周在杭州举办线下论文分享与学术交流。希望能汇聚来自各行各业对人工智能感兴趣的朋友,不断交流共同成长,推动人工智能民主化、应用普及化。
 |
1
hxndg 2019 年 9 月 2 日
1 你应该发在推广
2 你图片都裂了 3 你这什么鬼排版 |
 |
2
idotwannathis 2019 年 9 月 2 日
这都什么年代的东西了 还拿出来发
|
 |
3
jdhao 2019 年 9 月 2 日
什么玩意,推广也做的有点诚意,图片都没了。
|
 |
4
prolic 2019 年 9 月 2 日 via Android
梦回两年前
|