
这是一个创建于 1750 天前的主题,其中的信息可能已经有所发展或是发生改变。
Dig101: dig more, simplified more and know more
今天我们聊聊万物皆可为的接口( interface )的底层设计。
interface 被定义为一组方法的签名。
有了它,我们可以订立方法契约,去抽象和约束实现。
而 Go 的基础类型,可以认为是没有实现任何方法的空 interface,也就是万物皆为的 interface。
( Go 语言没有泛型,接口可以作为一种替代实现)
接口也被寄予厚望,主力开发 Russ Cox 曾说过:
从语言设计的角度来看,Go 的接口是静态的,在编译时检查过的,在需要时是动态的。如果我可以将 Go 的一个特性导出到其他语言中,那就是接口。 Go Data Structures: Interfaces
那到底 interface 是怎么设计的底层结构呢?
又怎么支持的duck typing?
在类型断言时又发生了什么?
带着这些问题,我们往下看
0x01 底层结构一样么
我们知道定义接口有这两种方式,那他们底层结构是一样的么?
// 方式 1
var a interface{}
// 方式 2
type Stringer interface {
String() string
}
var b Stringer
答案是 [不一样]
我们用 gdb 打印下对应类型( gdb 相关见Tips-如何优雅的使用 GDB 调试 Go)
// 空接口类型
>>> ptype a
type = struct runtime.eface {
runtime._type *_type;
void *data;
}
// 有函数定义的接口类型
>>> ptype b
type = struct runtime.iface {
runtime.itab *tab;
void *data;
}
// itable 相关类型
>>> ptype b.tab
type = struct runtime.itab {
// 接口相关信息
runtime.interfacetype *inter;
// 构造类型
runtime._type *_type;
uint32 hash;
[4]uint8 _;
// 构造类型的函数列表
[1]uintptr fun;
} *
>>> ptype b.tab.inter
type = struct runtime.interfacetype {
// 接口的类型
runtime._type typ;
runtime.name pkgpath;
// 接口定义的函数列表
[]runtime.imethod mhdr;
} *
以此可见 Go 内部定义了两种 interface (但都是两个机器字)
eface
空接口,指没有定义方法的接口
内部存储了构造类型(concrete type)type和data
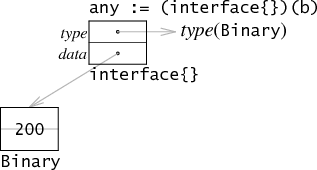
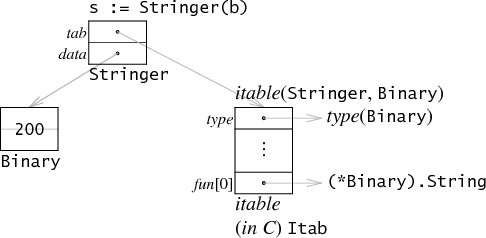
iface
有方法的接口
有了相比eface的type更丰富的itab字段,其中记录了构造类型及所实现的 interface 类型的类型和方法
0x02 类型如何相互转换
如下代码,当我们做接口赋值时,Go 又会怎样填充底层结构呢?
type Binary uint64
func (i Binary) String() string {
return strconv.Itoa(int(i))
}
func conversion() {
var b Stringer
var i Binary = 1
b = i // <= 这里发生了什么
println(b.String())
}
gdb 进到 b = i 这一步,会发现他调用了runtime/iface.go:convT64方法实现 iface 的赋值
查阅源码,会发现很多convXXX函数, 他们是干什么的?
convXXX 的命名
convFrom2To 指代 To=From 的转换
From 和 To 的类型有三种:
(参见cmd/compile/internal/types/type.go:Tie)
- E (eface)
- I (iface)
- T (Type)
这一堆函数看的人眼晕,但参照提交specialize convT2x, don't alloc for zero vals深入分析,就会清晰许多
起初的 convT2{I,E} 和 convI2I
最初只有 convT2{I,E} 和 convI2I
主要实现分配内存(newobject),然后拷贝赋值(typedmemmove)
convI2I 还会有getitab, 具体是什么我们后边类型断言时说
然后也在调用他们前(walkexpr)做了优化
- 减少值拷贝
ToType 为类指针(pointer-shaped)或者一个机器字内(int)的话,可以直接存入 interface 的 data 字段(主要优化在这里)
pointer-shaped 类型: ptr, chan, map, func, unsafe.Pointer
再辅以 type 的存储,就只是两个字(two-word)的拷贝
- 减少内存分配
零值,bool/byte 可以不用分配内存,而用已存在值(zerobase,staticbytes)
只读的全局变量(readonly global)直接可以用
1kb 以内,不escape到堆上,非interface的变量可以使用栈上分配的临时变量(stack temporary initialized)
这类 value 最后以取地址形式转化为 interface: {type/itab, &value}.
- interface 转空接口( eface )
可以丢弃除type以外的itab
tmp = i.itab
if tmp != nil {
tmp = tmp.type
}
e = iface{tmp, i.data}
针对类型优化后的 convXXX
但这里会有一些可以优化的点,如:
- 分配内存是否可以需要清零?
类指针的类型需要清零,不然内存可能有脏数据
但无指针类型(pointer-free)如拷贝时直接可以覆盖对应内存则不需要
如int其拷贝在一个机器字内完成,不需要分配时清零
( 32 位系统上不调用convT64,就可以保证访问内存是安全的原子操作)
- 是否可以简化值拷贝?
int,string,slice这些 Type 分配的x拷贝val时,可以简化为 *(*Type)(x) = val
- 拷贝内存是否可以不增加 gc 调用(写屏障)?
按 ToType 类型是否含指针区分
类指针类型(pointer-shaped): convT2{E,I} 需要拷贝时 gc 调用(typedmemmove)
无指针类型(pointer-free): convT2{E,I}noptr 不需要拷贝时 gc 调用(memmove)
这样一看就明白这些函数的用意了,还是为了针对性的提高转化效率
最后结合其调用处convXXX列表如下:
// cmd/compile/internal/gc/walk.go:walkexpr
case OCONVIFACE:
...
fnname, needsaddr := convFuncName(fromType, toType)
| 函数(fnname) | From 类型 | 值取地址存(needsaddr)| | ---- | ---- | ---- | | convI2I | iface | 否| | convT{16,32,64} | 底层为整型数据(不含指针,对齐不大于机器字) | 否| | convTstring |string| 否| | convTslice|slice| 否| | convT2E |Type| 是| | convT2Enoptr | 无指针 Type| 是| | convT2I |Type| 是| | convT2Inoptr |无指针 Type | 是|
不会存在 convE2E 和 convE2I needsaddr: 类型不含指针,大小大于 64 位字或未知大小时,使用值的地址来存
0x03 类型断言如何实现
interface 支持类型断言,来动态判断其构造类型,
判定成功可返回对应构造类型,便于调用其方法
可构造类型实现 interface 不需要显示声明,
那如下代码是怎么确定 interface b(构造类型是Binary)实现Stringer呢?
type Binary uint64
func (i Binary) String() string {
return fmt.Sprint(i)
}
func typeAssert() {
var b interface{} = Binary(1)
v, ok := b.(Stringer)
println(v, ok)
}
调试后会发现,其调用了assertE2I2
这里函数命名有两类,如下
assertE2I: v := eface1.(iface1)
assertE2I2: v,ok := eface1.(iface1)
这里有一点,类型断言非
v,ok方式的,断言失败会 panic )
原来其内部进行了itab表(itabTable)查询 interface 和构造类型的映射表,如果匹配则说明实现
下边代码分析如下
首先初始 512 个 entry 的表
const itabInitSize = 512
type itabTableType struct {
// 上限
size uintptr
// 当前用量
count uintptr
entries [itabInitSize]*itab
}
查表是否匹配
在类型断言中调用 getitab(inter, typ, canfail) 查表
- 先不加锁 atomic 读取 itabTable,找到返回
- 未找到加锁再查一遍,找到返回
- 还没有就创建一个 itab 添加到表中,添加完后解锁
- 期间如果判定不匹配则按是否可以 panic ( canfail )返回
其中查表用到 itabTable.find(inter, typ),
插入用到 itabAdd(m)
尝试插入更新
- 插入前需先用
m.inter/m._type pair初始化m.fun数组,不匹配则m.fun[0]==0
(m.fun 类型 [1]uintptr,实际指向是大小为接口定义方法数的方法数组。详见 func (m *itab) init())
-
用量 count 超过上限的 75%触发扩容,大小为 2 倍以上(要向上内存对齐),扩容后更新 itabTable 是原子操作
-
以 itab m 的 interface 类型和构造类型的 hash 计算对应 itabTable 的起始偏移,然后插入到其后第一个不为空的 entry。如果已存在则直接返回
这里用到了开放地址探测法,公式是:
h(i) = h0 + i*(i+1)/2 mod 2^k
具体插入用到 itabTable.add(m)
这里和其实 map 插入的逻辑很相似
动态判定效率优化
不过,这里有一个问题?
假定,interface 定义了ni个方法,构造类型实现nt个方法,
常规匹配构造类型是否实现全部ni个方法需要两层遍历,复杂度为O(ni*nt)
这样在初始化itab.fun或类型断言匹配是效率会比较低。
Go 设计时也考虑了这个问题,把复杂度降低为O(ni+nt)
这也是使用 hashtable 的原因之一:
-
首先 interface 的函数定义列表
itab.inter.mhdr和构造类型的函数列表itab.fun都是按函数名排好序的 -
这样第一次 itab 初始化时,判定构造类型是否实现函数列表可以
O(ni+nt)内遍历完成 -
然后用开放地址探测法更新到 itabtable 中,查询时也可以用同样的方式定位到此 itab 是否存在。
两个(有序)列表的遍历匹配代码精简如下:
// runtime/iface.go:init()
j:=0
imethods:
// 遍历 interface 定义函数列表
for k := 0; k < ni; k++ {
// 遍历构造类型函数列表
for ; j < nt; j++ {
// 如果两者类型( type ),包路径( pkgpath ),函数名( name )匹配
if xxx {
// 将方法记录到 fun0 (最终全匹配则赋值给 m.fun)
continue imethods
}
}
// 未全匹配
m.fun[0] = 0
}
m.fun[0] = uintptr(fun0)
总结一下 interface 的底层设计:
- interface 分为空接口( eface )和接口( iface )两类,但都是两机器字( two-word )存储结构
- interface 转换中针对不同类型做了优化,主要集中于提升内存分配和值拷贝效率
- interface 类型断言时动态判定,利用有序列表遍历+全局哈希表表缓存优化判定效率
See More: 官方解释 InterfaceSlice 为什么不能直接转化
最后留个问题:
下边这段转换代码内部没有调convT64,为什么?
var b Stringer = Binary(1)
_ = b.String()
这个问题下一篇文章再来给出解答。
本文代码见 NewbMiao/Dig101-Go
欢迎关注公众号:newbmiao,获取及时更新文章。
推荐阅读:Dig101-Go 系列,挖一挖技术背后的故事。
目前尚无回复