
这是一个创建于 2137 天前的主题,其中的信息可能已经有所发展或是发生改变。
大家好, 我是 Lucy, FinTech 社区创始人。FinTech 社区是一个拥有 50,000+会员的金融科技社群,旨在为金融科技行业赋能,致力于金融科技行业资源共享社群, 有量化研究群, 机器学习群, 北美群, c++ 群, 校招群, Lucy 曾在美国顶尖对冲基金工作, 独自组建一支 45 人交易团队,添加微信: lucylj66,加入社区, 攒人脉, 提认知,求职招聘!
自然语言处理是计算机科学领域与人工智能领域中的一个重要方向,它研究能实现人与计算机之间用自然语言进行有效通信的各种理论和方法。而在 NLP 应用的各种行业中,金融行业因其与数据的高度相关性,成为 NLP 技术最先应用的行业之一。今天这篇文章将为大家介绍如何利用 NLP 分析财报数据。
NLP 技术在金融投资领域的应用非常广泛,概括而言,主要包括以下三个方面:
1. 信用评分 Credit Scoring
-
LenddoEFL https://www.lenddo.com/ 会帮助银行等金融机构评价个人信用分数,特别是没有信用历史的用户。
-
主要的方法是个人将网上信息披露给这家公司,该公司会将社交网络信息、浏览记录、地理位置等信息转化成信用分数,从而对个人信用评级。
2. 文本情感分析 Sentiment Analysis
-
位于多伦多的对冲基金 Periscope Capital,会收集大量的推特、博客数据,并实时利用神经网络的模型处理,得到及时的情感分数。这些数据之后会被综合汇总,来帮助实时投资决策的制定。这个项目被收录在一个名叫 BUZZ US Sentiment Leaders 的 ETF 指数基金中。
-
Sigmoidal 是一家利用 NLP 技术在金融领域提供咨询服务的公司,通过结合处理各种推特博客数据向投资者提供建议。
3. 智能文档搜索 Document Search
-
AlphaSense: 通过对金融市场信息建立搜索引擎,提供有效及时的金融信息搜索服务。
-
Kensho:被 S&P Global 收购的自然语言处理公司,也一直在提供金融信息检索服务,他们将各种主题的新闻、金融文档汇总处理,提供给诸如高盛、JP 摩根等公司辅助尽职调查。
下面结合具体例子,详细说明如何利用 NLP 技术分析上市公司财报会议( earning call )数据并从中提取决策信息。
一般而言,对于自然语言处理的应用,主要有三个步骤:
-
文本预处理 Text preprocessing
-
文本特征转化 Text to features
-
测试和迭代 Test and refinement
一、文本预处理
文本预处理主要包括:
消除噪声( Noise Removal )、词汇规范化( Lexicon Normalization )以及对象标准化( Object Standardization)。
1. 噪声消除
主要将标点符号、缩写字母、停止词语(比如英文里的 the,中文里的“的”)等和分析主题无关的词语移除。常见的做法是采用一个已有的词汇和实体表,通过筛选的方式将多余内容移除。
在英文中常用的金融词汇表之一为 Loughran and McDonald (2011) financial dictionary 金融词典,里面包括了金融行业中常见的词汇以及情感词汇,包括 80000+个关键词,350+个正面词汇以及 2300+个负面词汇:
https://sraf.nd.edu/textual-analysis/resources/
2. 词汇规范化
主要是讲每个单词的不同格式规范为同一种格式,例如在英文中每个动词都有不同的时态( e.g. play, plays, played)。两种最常见的方式为:
-
Stemming 词干提取: 将单词的各种形式的提取为同一词干 (例如 playing, play, played 都转化为 play).
-
Lemmatization 词形还原: 将单词原有的形式,与词干提取不同的是,前者产生的词干可能并不是单词,但是词形还原会提取出原有的单词。

在 Python 中有 nltk (Natural Language Tool Kit) package 可以实现上述英文的词汇规范化,例如可以通过导入 PortStemmer 实现词干提取:
from nltk.stem import PorterStemmer
porter = PorterStemmer()
print(porter.stem("cats”)) # cat
print(porter.stem("troubling”)) # trouble
或利用 WordNetLemmatizer 实现词形还原:
from nltk.stem import WordNetLemmatizer
wnl = WordNetLemmatizer()
print(wnl.lemmatize('cars', 'n’)) # 名词 -> car
print(wnl.lemmatize('ate', 'v')) # 动词 -> eat
3. 对象标准化
指将一些有错误的词语标准化,比如 luv 转化为 love 。常见的方法是采用一个更广泛的词汇表(包含很多常见的容易混淆、出错的词语),省下的词语则被考虑为噪声。

二、文本特征转换
文本特征转化主要包括句法解析 (syntactical parsing) ,统计特征( statistics features )以及词嵌入( word embedding )。
句法解析( syntactical parsing ) 主要分为两种,语法依存(dependency grammar) 以及部分语音标记( part of speech tagging, PoS)。他们两者都是用来判断句子的结构。
-
语法依存: 主要是利用主谓宾的结构来判断单词之间的主要关系,通常通过树的形式来展现单词之间的关系。
-
语音标记 PoS: 主要依赖已有的标记好的语言结构,来帮助更好地理解单词在句子中的意思。(例如,book:book a fligh 以及 read a book 中的 book 有不同的意思)
统计特征( statistics feature ) 主要指的是讲文本转化为可以量化的单词之后的统计结果。常见的统计特征包括词汇数量、句子数量以及音节统计。通过这些数量,可以定量一句话的情感色彩。
在这个实例中,我们通过计算通过负面词语数量占总句子单词数量的比例来体现这句话的情感色彩。
词嵌入( word embedding ) 是一种更加高级的统计特征,主要讲文本中的单词通过向量来表示。例如下表中我们可以找出每词汇之间在文本中出现的关系,用一个在 0-1 之间的数字表示二者的关系,1 代表两者关系非常密切,0 代表没有关联。
如下表中国王( king )和王权( Royalty )的关系是 0.99 , 而女王( queen )和男性主义( Masculinity )的关系不大,只有 0.05 。

通过扩展维度,我们能够将单词用多个维度的向量表示,最终通过矢量运算找出不同单词之间的含义,例如在上述例子中:国王( King )-男性主义( masculinity )+女性主义( femininity )=女王( Queen )。
三、测试和迭代
通过分离训练数据和测试数据,我们可以通过训练数据带入到 NLP 算法得出对应的模型,并通过测试数据对其进行校正( calibration )和测试( test ),最终得到理想的模型和结果。
这里通过两个例子来展示 NLP 技术在分析财报数据中的应用。
1. 对单只股票的分析
分析苹果每个季度的财报会议文字的同比情感变化百分比和下一个季度股价回报之间的关系。
在这个例子中,情感变化百分比为这个季度的情感值与去年相同季度情感值变化的百分比( Quarter-over-quarter, QoQ ),情感值定义为在财报会议文本中负面词汇占整个文本的比例。
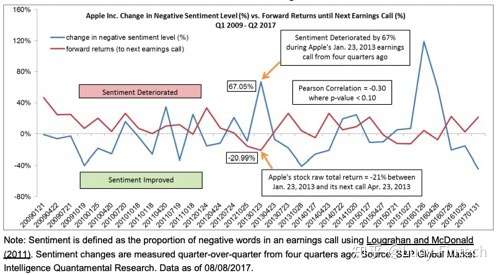
从上图中我们可以看到,在 2013 年 1 月的财报会议中苹果的负面情感值同比增加 67%,而对应下个季度即 2013 年 4 月苹果的回报率为-21%。
整体而言,两者的皮尔逊相关指数为-0.3,可以看出历史上苹果财报会议负面情绪变化和下个季度的汇报成负相关。
2. 对整个行业的分析
第二个例子可以用过热度图的方式来展现不同的行业在情感值的变化。
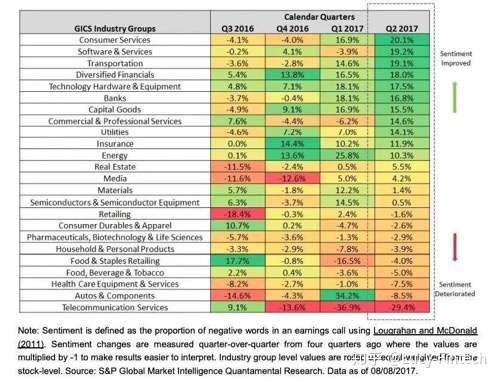
通过对比行业情感值变化,我们可以看出哪些行业情感值变化为正向,哪些情感值变化为负向。情感值提升的行业代表了公司高管对于该行业这个季度有信心,情感值为减少的行业则相反。
对比分析单独行业,我们也可以看出哪些行业在哪些时间出现了拐点。
例如银行业 Banks 从 2016 年第四季度之后,相比之前季度均为正向情感变化,表明高管对该行业未来普遍更有信心。
下面是利用 nltk package 建立模型的关键代码:
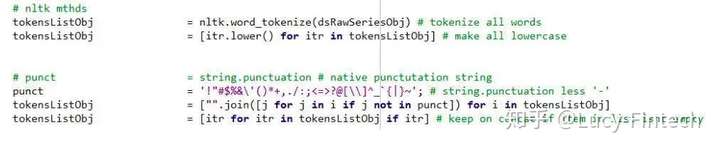
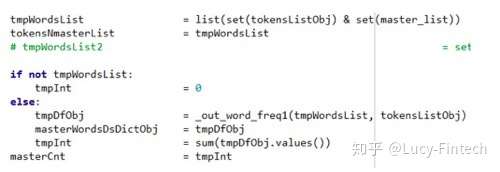
来源: S&P Global Quantamental Research
#今日互动#
关于 NLP 的应用
你有没有实战经验或想要分享的?欢迎留言讨论~
近期热招:(点击标题,即可了解详情)
目前尚无回复