
- 前言
网上关于验证码识别的开源项目众多,但大多是学术型文章或者仅仅是一个测试 demo,那么企业级的验证码识别究竟是怎样的呢?前方高能预警,这是一个生产水准的验证码识别项目,笔者可以向你们保证,它一定会是各位所见过的文章中最实用的,你甚至可以不需要懂代码写代码就能轻松使用它训练一个 99 识别率的模型。这才是企业级应该有的样子:算法开发负责框架,训练只需要一个实习生。不仅操作上简单,在可用性和稳定性上也是经得起考研。性能上,笔者使用腾讯云 1 核 1G 的机器测试:单次识别平均在 12ms 左右,再也不需要 GPU 部署了,CPU 一样可以日调百万。
不少初学者和笔者反应,安装环境太难了,没关系,都给你们安排好了,一行 pip 就能搞定环境的 MuggleOCR 。 仓库地址:https://pypi.org/project/muggle-ocr
MuggleOCR 的体积有 6MB,其中附带了两个通用模型:简单通用验证码,普通 OCR 。简而言之就是,再也不用愁验证码的样本不好标注了,它将是各位标注样本的利器,简单的验证码识别率能有 95%以上,复杂的也有 50%-70%左右,只需要结合官网校验,轻松下载几万标注样本。
除此之外,它可以支持调用使用本文框架( captcha_trainer )训练的模型。调用只需要三行核心代码:
# 打开一张验证码图片
with open(r"1.png", "rb") as f:
img_bytes = f.read()
# 步骤 1
import muggle_ocr
# 步骤 2
sdk = muggle_ocr.SDK(model_type=muggle_ocr.ModelType.OCR)
# 步骤 3
text = sdk.predict(image_bytes=img_bytes)
print(text)
是不是很简单,用它应付一般的验证码识别足矣
本项目旨在降低图像识别的门槛,让深度学习技术能够进入更多人的视线。任何人经过简单的介绍,都可以轻易使用这项技术训练一个商业化的成品。
笔者选用的时下最为流行的 CNN Backbone+RNN+CTC ( CRNN )进行端到端的不定长验证码识别,代码中预留了 CNNX/MobileNet/DenseNet121/ResNet50 等。其中可能你们搜不到 CNN5 和 CNNX,因为是小编自己拼凑的网络选项,专门为验证码优化定制的,在配置界面中可以随意切换网络组合。
前面介绍这么多还没进入正题,各位是不是好奇它到底是什么模样呢?
运行方法:
- 可通过编译版的可执行文件运行
- 在项目中运行 app.py 来启动 GUI 的界面
训练项目源码: https://github.com/kerlomz/captcha_trainer
编译版下载地址: https://github.com/kerlomz/captcha_trainer/releases
部署项目源码: https://github.com/kerlomz/captcha_platform
编译版下载地址: https://github.com/kerlomz/captcha_platform/releases
注意:在 Windows 服务器版中使用编译版如果出现闪退,可以用 CMD 执行可执行文件来查看报错,如果报错为cv2 ImportError: Dll load failed 请按照步骤:我的电脑——属性——管理——添加角色和功能——勾选桌面体验,点击安装,安装之后重启即可。
2.环境依赖:
环境依赖花了超长篇幅,主要是写给零开发基础的使用者,有基础的可以随便跳过,也欢迎使用编译版,可在上一章末尾找到下载地址。
关于 CUDA 和 cuDNN 版本的问题,就让不少人望而却步,其实很简单,如果使用 pypi 仓库安装的 TensorFlow,那么 Linux 系统使用 CUDA 9.0,Windows 使用 CUDA 10.0,因为仓库中的 whl 安装文件都是根据对应的 CUDA 版本编译的。也就是版本绑定死了,如果有需要可以去搜索TensorFlow Wheel找第三方编译的版本,如果妄图自行编译我这里劝退一下,坑很多。
2.1 项目使用环境
在项目中的 requirements.txt 已经整理好所有依赖模块。一键pip install -r requirements.txt安装即可
1 )安装相关依赖
不用理会上面的清单,在项目中的 requirements.txt 已经整理好所有依赖模块。可以直接在项目路径下执行pip3 install -r requirements.txt安装所有依赖。
注意默认情况会安装到全局的 Python 环境下,笔者强烈建议在虚拟环境进行,做好项目间的环境隔离,可以借助Virtualenv或Anaconda等等实现。 笔者个人使用的是 Virtualenv,如果有修改代码需求的,可直接在 PyCharm 上操作。
virtualenv -p /usr/bin/python3 venv # venv 是虚拟环境的名称,也是路径名.
cd venv/ # 进入环境.
source bin/activate # 激活当前环境.
cd captcha_trainer # captcha_trainer 是项目名.
pip3 install -r requirements.txt # 在刚刚创建的环境下安装当前项目的依赖
2.1.2 Ubuntu 16.04 下的 CUDA/cuDNN
网上很多教程,但是靠谱的不多,自己在不同的机器上部署过几次,以身说法,14.04 桌面版支持不好,需要主板支持关闭 SecureBoot,Ubuntu 16.04 的坑少一点,大多的坑都发生在安装好之后,在登陆界面无限循环无法进入桌面。网上很多教程提示要加驱动黑名单什么的,笔者亲测没那个必要。就简单的几步: 1. 下载好安装包 必须下载 runfile 类型的安装包,即后缀名为.run 的安装包,因为 deb 安装包默认安装自带驱动,这是导致登陆循环的罪魁祸首。 NVIDIA 驱动下载: https://www.geforce.cn/drivers CUDA 下载地址: https://developer.nvidia.com/cuda-10.0-download-archive cuDNN 下载地址: https://developer.nvidia.com/cudnn (需要注册 NVIDIA 账号且登陆,下载 deb 安装包)
2. 关闭图形界面 进入字符界面,快捷键 Ctrl+alt+F1,将 GUI 服务关闭
sudo service lightdm stop
3. 安装 Nvidia Driver
命令中的版本自己对应下载的版本改,在上面的下载地址根据自己的显卡型号下载最新版,切记是 runfile 格式的安装包。以下 3xx.xx 为版本号,请下载最新驱动。
sudo chmod a+x NVIDIA-Linux-x86_64-3xx.xx.run //获取执行权限
sudo ./NVIDIA-Linux-x86_64-3xx.xx.run –no-x-check –no-nouveau-check –no-opengl-files //安装驱动
安装后使用 nvidia-smi 命令验证,若出现显卡信息,则表示安装成功
4. 安装 CUDA
1 )先安装一些系统依赖库
sudo apt-get install build-essential libx11-dev libxmu-dev libxi-dev libglu1-mesa-dev libgl1-mesa-glx libglu1-mesa freeglut3-dev
- 执行安装程序,按提示继续就好了,直到出现是否安装驱动选项,选择不安装即可。
sudo sh cuda_9.0.176_384.81_linux.run
安装完成还需要配置环境变量,将以下内容就追加到 ~/.bashrc 文件的尾部
export PATH=/usr/local/cuda-9.0/bin${PATH:+:${PATH}}
export LD_LIBRARY_PATH=/usr/local/cuda-9.0/lib64${LD_LIBRARY_PATH:+:${LD_LIBRARY_PATH}}
最后在终端执行 sudo ldconfig命令更新环境变量,重启机器,重新启用 GUI 即可。
sudo service lightdm start
2.1.3 Windows 系统
一直有人说 Windows 不适合做深度学习,其实笔者觉得还是蛮友好的。巨硬的系统安装环境简单一百倍,只要到官网下载对应的安装包,本项目建议 CUDA 10.0,Windows 2019 的话可以使用 Win10 版替代,CUDA 安装的时候同样不安装驱动,包括一个 VS 的选项也去掉(不取消安装会很慢并可能安装失败),然后下载对应的 cuDNN 替换到 CUDA 安装路径即可,一般为:C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.0。
3 使用
开始之前,先解决一个世纪疑惑,有不少朋友常常私信我“训练一个 x 位数英文数字验证码需要多少样本?”诸如此类的问题,笔者在此统一回复,样本需要多少数量需要根据样本的特征复杂程度来决定。
特征复杂度评价指标:
- 变形
- 旋转
- 模糊
- 背景干扰
- 前景干扰
- 字体种类
- 标签数目 /验证码位数
- 分类数目 /字符集大小
一般只包含以上 1-2 种的为简单,2-3 种为复杂,3 种以上属于特别复杂。样本量依次递增,从几百,几千,几万,到几十万不等,其中,分类数目(字符集带)多寡对数量级影响较大,例如中文几千字符集的验证码一般 10w 起步,笔者文中末尾的验证码用了 100w 样本。
PS:亲们不要再考验框架的健壮性了,样本量连一个 Batch Size 都达不到的,千万不要尝试,根本跑不起来。
目前为止,入坑准备工作还差一步,巧妇难为无米之炊,首先,既然是训练,得要先有数据,笔者这里提供一份路人皆知的 mnist 手写识别的数据集。
可以在腾讯云下载: https://share.weiyun.com/5pzGF4V,现在万事俱备,只欠东风。
3.1 定义一个模型
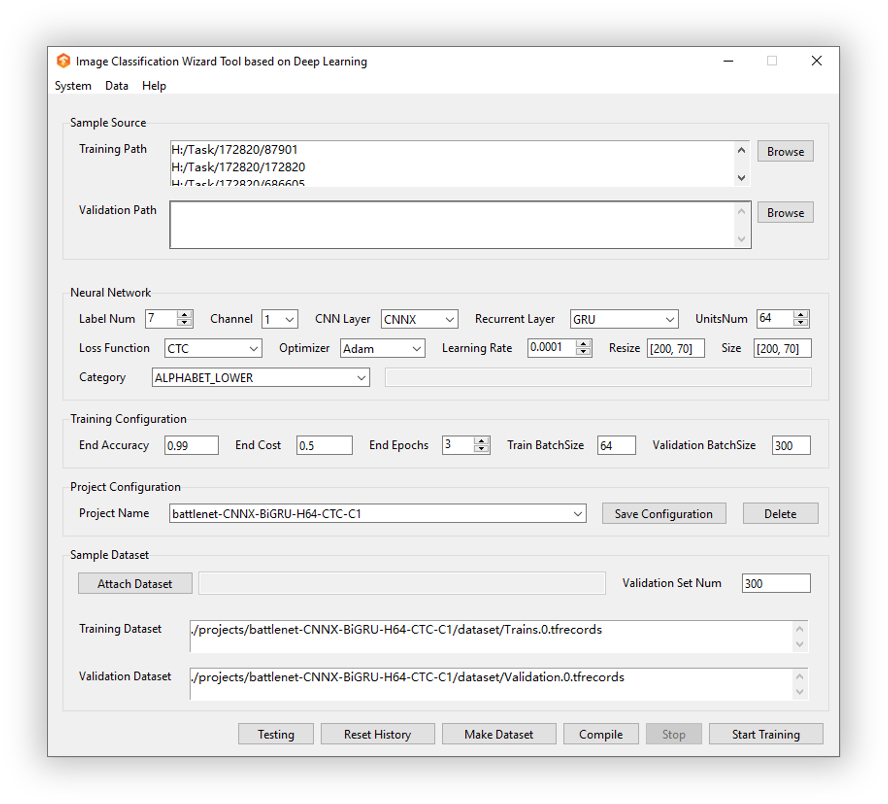
本项目所有配置都是参数化的,不需要改动任何代码,可以直接通过可视化界面操作,训练几乎图片验证码。训练框架界面可以大致划分为几个部分:
- Neural Network - 神经网络区

- Project Configuration - 项目配置区

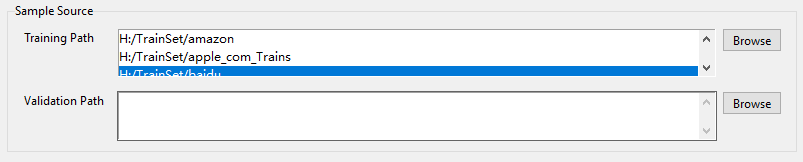
- Sample Source - 样本源配置区
- Training Configuration - 训练配置区

- Buttons - 功能控制区

依此类推的训练配置的步骤如下:
- 神经网络区 的配置项看起来很多,对于新手来说,只需先选择好使用的网络,在样本配置区选择样本路径之后,会自动配置图片有关的参数,保持默认推荐参数即可。笔者一般使用 CNNX+GRU+CTC 网络进行不定长验证码的训练。
- 项目配置区 的配置项在网络选好之后配置项目名,按回车或者点击空白处确认。
- 样本源配置区 的配置项用来配置样本源的路径,训练样本是根据此路径进行打包成 TFRecords 格式,验证样本可以不指定,使用[Validation Set Num]参数随机从训练集总抽样成验证集,这里默认随机抽取数目为 300 个,可以在界面上自行修改。
- 训练配置区 的配置项负责定义训练完成的条件如:结束准确率,结束 COST,结束 Epochs,批次大小。如果最后无法满足可以手动停止,然后点击[Compile]编译导出最新的训练模型。
- 功能控制区 的配置项,设置完上面步骤,先点击[Make Dataset] 打包样本,再点击[Start Training]开始训练。
以下部分有基础的读者们可以了解一下:
如若使用 CrossEntropy 作为解码器需要注意标签数 LabelNum 和图片尺寸需要满足的关系,因为网络为多标签而设计(一般的多标签采用直接连接多个分类器,这也是有一部分网上的开源代码你们修改了图片就无法运行的原因之一),卷积层的输出 outputs 经过了以下变换:
Reshape([label_num, int(outputs_shape[1] / label_num)])
为了保证 int(outputs_shape[1] / label_num) 运算能够得到正整数维度,这意味着他们之间存在某种数学关系,对 CNN5+Cross Entropy 网络结构而言,Conv2D 层的步长皆为 1,那么需要保证以下等式成立:
$$ mod(\frac{输入宽度\times 输入高度\times 输出层参数}{池化步长^{池化层数}\times 标签数})= 0 $$
所以有时候需要对输入的图片 Resize,一般 4 位验证码不容易出现这种问题,位数为 3,5,6,7 容易出现不满足等式的问题,这个等价关系如果不好计算的话,建议使用 CTC Loss 。
例如使用 CNN5+CrossEntropy 组合,则输入宽度与输入高度需要满足: $$ mod(\frac{输入宽度\times 输入高度\times64}{16\times 标签数})= 0 $$ 同理如果 CNN5+RNN+CTC,卷积层之后的输出经过以下变换:
Reshape([-1, outputs_shape[2] * outputs_shape[3]])
原输出(batch_size, outputs_shape[1], outputs_shape[2], outputs_shape[3]),RNN 层的输入输出要求为(batch, timesteps, num_classes),为了接入 RNN 层,经过以上的操作,又引出一个 Time Step (时间步长)的概念。
可以把 timesteps 可以理解为图片切片,每个切片需要和标签对应。进入 RNN 层之后 timesteps 的值也是经过卷积池化变换之后 outputs_shape[1],而 CTC Loss 的输入要求为 [batch_size, frames, num_labels],若 timesteps 小于标签数目,可以理解为图片切片数小于标签数,一个切片对应了多个标签,那么肯定是无法计算损失的,也就是无法从损失函数中找到极小值,梯度无法下降。
timesteps 最合理的值一般是标签数的 2 倍,为了达到目的,也可以通过对输入 Resize 来间接调整卷积池化之后的 outputs_shape[1],一般情况下 timesteps 直接关联于图片宽度,大多情况只需按比例 Resize 宽度即可。
ExtractRegex 参数:
注意:如果训练集的命名方式和我提供的新手训练集不一样,可以根据实际情况修改 ExtractRegex 的正则表达式。强烈建议不知道如何写正则表达式的朋友按照笔者的定义规范命名。目前这个功能只支持在 yaml 配置文件中修改,GUI 界面尚不支持修改该参数。 DatasetPath 和 SourcePath 参数允许配置多个路径,如果需要把多种样式的图片混合一起训练,或者打算训练一套通用识别模型的用户,这非常方便。 分类数目 /字符集( Category )已经包括了大多数验证码和 OCR 的情况,大多数情况下不需要自定义,一般的图形验证码是大小写不敏感的,一般不要轻易选择区分大小写的分类,推荐默认的 ALPHANUMERIC_LOWER,会自动将大写的转为小写,字符集定义很灵活,除了配置备注上提供的几种范式,还支持训练中文,自定义字符集用 list 表示,参考如下:
Category: ['你', '好', '世', '界', '北', '京', '大', '学']
如果是单标签分类,可以配合 LabelNum=1,例如:
Category: ["飞机", "鞋子", "水杯", "面包", "横幅", "订书机", "壁画", "猫砂", ......]
其文件名示例:飞机_0123456789012.png
如果是多标签分类,可以配合 LabelSplit=&,例如:
Category: ["飞机", "鞋子", "水杯", "面包", "横幅", "订书机", "壁画", "猫砂", ......]
其文件名示例:飞机&鞋子&水杯_1231290424123.png
注意:中文字符集一般比数字英文大很多,收敛时间较长,同样也需要更多的样本量,千万不要想着几千张图片训练几千字符集的验证码,毕竟机器也不是神
 形如上图的图片能轻松训练到 98%以上的识别率。
形如上图的图片能轻松训练到 98%以上的识别率。
ImageWidth 、ImageHeight 参数只要和当前图片尺寸匹配即可,其实这里的配置主要是为了方便后面的部署智能策略。
Pretreatment 参数:
这个 Pretreatment 参数主要是图片预处理用的,例如下面这个有趣的 GIF 动图,

通过观察,滚动匀速,位数固定,那么一定存在某两个固定的帧,完全包含前三和后三位的内容。这种就可以采用拼接的形式,将包含完整 6 位的内容的图片拼接为一张,使用 Pretreatment/ConcatFrames 参数,选取前后两个帧进行水平拼接,适用于处理滚动型 GIF,而闪烁型 GIF 可以使用 BlendFrames 参数进行图层融合。
3.2 开始训练
- 经过 采集标注样本形如 xxx_随机数.png
- 样本打包 可以通过 GUI 界面的 [Make Dataset],或者使用 make_dataset.py 手动配置打包样本,打包的目的主要是为了减少硬盘的 IO 读写。有时候准备的样本比较少,训练结果不满意,重新采集了一部分样本怎么加入训练呢?对于增量的样本打包可以使用[Attach Dataset],无需重新打包。 PS:使用源码的同学需要具备一定的编程基础,尽量不去修改核心函数和静态定义以免出现错误,修改代码的时候请确保配套的部署项目对应的地方也一并修改了。
按照上面的介绍,讲解虽多,但实际上只需要配置极少数的参数,就可以开始训练了,高级玩家一般配置不超过 10 秒。
开始训练:
- 创建好项目后,在 PyCharm 中运行 trains.py ,也可以在激活 Virtualenv 下使用终端亦或在安装依赖的全局环境下执行
- 本文建议全程使用 GUI 界面进行操作,源码使用 GUI 仅需启动 app.py 即可。
python3 trains.py
下图为训练通用模型的过程截图,耐心等待训练结束即可。
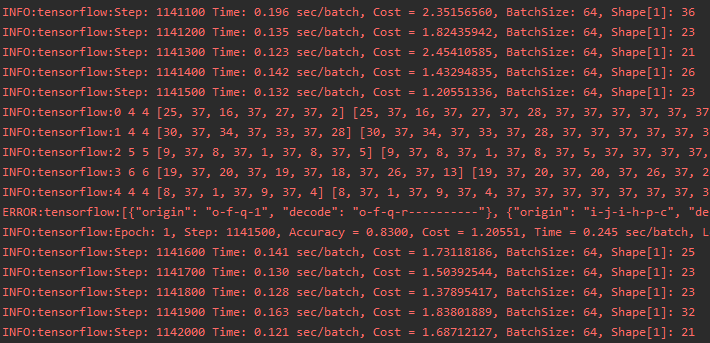
训练结束会在项目路径的 out 下看到以下结构的文件,pb 为模型,yaml 为模型配置文件,下面该到部署环节了。
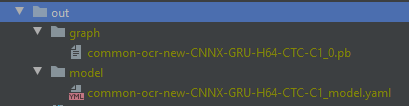
3.3 部署
一般验证码识别在企业中很少以 SDK 的形式被使用,大多是以微服务出现的,独立于其他的业务,独立运营和维护,那么企业级的部署服务又是怎样的呢?
项目地址: https://github.com/kerlomz/captcha_platform,可以为各位提供一个参考,Tornado 服务仅作为一个例子,企业一般采用 gRPC 集群远程调用。
如需要集成到项目里通过 sdk 调用的,可以参考 MuggleOCR 的做法,它的核心继承了 captcha_platform/sdk/pb/sdk.py:
https://pypi.org/project/muggle-ocr/
模型的调用方法:
-
可以通过 muggle-ocr 调用训练框架生产的模型( pypi 文档有介绍),
-
也可以提取 sdk.py 根据需要自行修改。
-
还可以直接使用编译版(免去安装 Python 和 TensorFlow 环境,目前同时支持 Ubuntu/MacOS/Windows 三大平台),第一章末尾有链接。
部署服务的特性:
- 支持多模型部署
- 支持模型热拔插
- 版本控制灵活
- 支持批量识别
- 智能模型分发
笔者封装了 Graph 会话管理,设计会话池,允许同时管理多模型,实现多模型动态部署方案。
1 ) 训练好的 pb 模型只要放在 graph 路径下,yaml 文件放在 model 路径下(操作顺序很重要,yaml 主要用于服务发现,通过 ModelName 参数定位对应的 pb 模型,如果顺序颠倒,服务是无法加载尚未放置进来的模型的)。
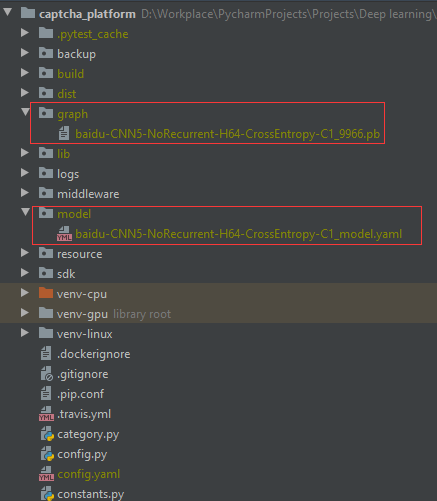
使用 SDK 调用时,yaml 和 pb 模型必须在同一路径下。

2 ) 卸载一个正在服务的模型,只需要删除 yaml 和对应的 pb 模型即可。(模型已加载于内存所以无所谓顺序)
3 ) 更新一个已经部署加载的模型,只需按先后顺序放置 pb 模型和高版本的 yaml 文件,服务会自动发现并加载,旧模型优先级被取代,不会再被调用,便可按上述方法卸载弃用的模型释放内存。 一切管理操作均无需重启服务,可以无感知切换,方便维护提高了可用性。
其次,如果读者有很多验证码需求需要逐个定制,训练时将所有尺寸一样的图片训练成一个模型,服务根据图片尺寸会自动定位对应的模型。当然也可以通过传递 model_name 参数精确控制多模型调用,这样的设计允许定制化和通用性共存,当读者们积累到一定量的样本集时可以像 MuggleOCR 一样训练一套通用识别模型作为备用模型。模型之间亦彼此独立,每增加部署一个模型,仅仅增加了少量的内存或显存占用,不少小企业也吃过定制模型的亏,找个人定制模型,每个模型都要独立启用一个服务,无形增加了成本,每个进程若重复加载一遍整个框架无疑是极大的资源浪费。
前面有提到批量识别,有这种需求的用户相对较少,这里只做简单介绍,给一个 12306 的例子,如图所示:

一张图中包含了多个需要识别的部分,而框架中的 CorpParams 支持将大图切割为小图一并传入,原本一个请求对于服务只能传一张图,现在可以通过裁剪功能一次传入 9 张图。代码如下:
FieldParam:
CorpParams: [
{
"start_pos": [118, 0],
"interval_size": [0, 0],
"corp_num": [1, 1],
"corp_size": [60, 30]
},
{
"start_pos": [5, 40],
"interval_size": [5, 5],
"corp_num": [4, 2],
"corp_size": [66, 66]
}
]
OutputCoord: True
FieldParam/CorpParams 参数可以裁剪合并批次,该用法可避免多次调用。
但是识别项目提供多种后端实现版本:Tornado/Flask/gRPC/Sanic,其中 Flask 和 Tornado 搭载了加密接口/captcha/auth/v2,类似于微信公众号开发接口的 SecretKey 和 AccessKey 接口,有兴趣的可以在 demo.py 中阅读调用源码了解。
部署服务可以使用 package.py 编译为可执行文件,本文中提供的编译版也是基于 Pyinstaller 打包编译的,编译版不需要考虑更换机器需要重新安装环境,若使用源码部署的话,环境配置同训练项目一样,使用项目中提供的 requirements.txt 一键安装全部依赖,部署服务默认推荐的是 CPU 版的 TensorFlow 。
部署服务推荐 Tornado 后端,目前最稳定的版本。
Linux:
- Tornado:
# 端口 19952
python3 tornado_server.py
- Flask
# 方案 1,裸启动, 端口 19951
python flask_server.py
# 方案 2,使用 gunicorn,端口 5000
pip install gunicorn
gunicorn -c deploy.conf.py flask_server:app
- Sanic:
# 端口 19953
python3 sanic_server.py
- gRPC:
# 端口 50054
python3 grpc_server.py
- 编译版(基于 Tornado)
# 前台运行
./captcha_platform_tornado
#后台运行
nohup ./captcha_platform_tornado &
Windows:
Windows 平台下都是通过python3 xxx_server.py启动对应的服务,注意,Tornado 、Flask 、Sanic 的性能在 Windows 平台都大打折扣,gRPC 是 Google 开源的 RPC 服务,有较为优越的性能。
编译版直接运行编译后的 exe 可执行文件即可。
3.4 调用 /测试
1. Tornado 服务:
请求为 JSON+POST 格式,URIhttp://localhost:19952/captcha/v1 形如:{"image": "iVBORw0KGgoAAAANSUhEUgAAAFoAAAAjCAIAAA...base64 编码后的图像二进制流"}
返回结果:
该返回为 JSON 格式,形如:{'uid': "9b5a6a34-9693-11ea-b6f9-525400a21e62", "message": "xxxx", "code": 0, "success": true}
4. gRPC 服务: 需要安装依赖,grpcio 、grpcio_tools 和对应的 grpc.proto 文件,可以直接从项目中的示例代码 demo.py 中提取。
python -m grpc_tools.protoc -I. --python_out=. --grpc_python_out=. ./grpc.proto
grpcio 、grpcio_tools 是根据 grpc.proto 使用上述命令生成的。
class GoogleRPC(object):
def __init__(self, host: str):
self._url = '{}:50054'.format(host)
self.true_count = 0
self.total_count = 0
def request(self, image, model_type=None, model_site=None):
import grpc
import grpc_pb2
import grpc_pb2_grpc
channel = grpc.insecure_channel(self._url)
stub = grpc_pb2_grpc.PredictStub(channel)
response = stub.predict(grpc_pb2.PredictRequest(
image=image, split_char=',', model_type=model_type, model_site=model_site
))
return {"message": response.result, "code": response.code, "success": response.success}
if __name__ == '__main__':
result = GoogleRPC().request("base64 编码后的图片二进制流")
print(result)
3.5 奇技淫巧
举一个比较不常见的例子,以下例子不代表任何网站。
正常情况下会想到以下 1 和 2.1 的方法:
- 颜色提取的思路,可以采用 HSV/K-means 聚类进行颜色的分离提取:效果如下:
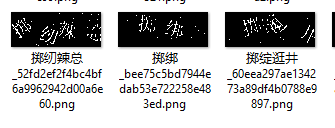 弊端显而易见,会有较大的特征丢失,识别率有较大的提升瓶颈,经过测试,中英文+汉字的识别率在 90%左右。
弊端显而易见,会有较大的特征丢失,识别率有较大的提升瓶颈,经过测试,中英文+汉字的识别率在 90%左右。 - 不分离颜色的思路,该方案有两种处理方法:
( 1 )同时预测颜色和字符内容,这种方法看起来比较正统,但是成本较高,需要标注每张图的颜色和字符内容,这个要求有多高呢,一般的打码平台是无法提供这样的结果的,打码平台只返回对应颜色的内容,只能人工标注,那么需要多少样本呢?按照笔者训练的识别率 98 的模型用了 100w 左右的样本。一张这样的样本标注假设需要 0.1 元,那么 100w 样本需要 10w 标注费用,假设 0.01 元,也要 1w 的标注费用。但是验证码高质量的人工标注几乎是不存在的,因为很多样本,人眼的识别率是不如机器的,总体标注的准确率大概也只能在 85 左右。看起来并不可取,有一种节约成本的办法,可以通过算法生成样本,但是呢,生成的识别率英文数字还可以,中文的识别率就低的可怜了。
( 2 )每个颜色分别训练一个模型, 这种方法看起来有点蠢,但是确实比较合适有效的办法了,可以轻松借助打码平台的返回结果标注样本。需要的颜色可以通过官网提供的字段取到,返回结果通过打码平台识别得到,这样一组合,样本就有了。这种方法的成本相对较低,样本数不变的前提下,打码价格低于人工标注的成本。但是笔者训练的是一种颜色的样本用了 100w 。每个颜色分别训练这样成本还是下不来。四种颜色就是 500w 样本。官网的每次获取图片的时候颜色随机出现的概率也不一定是 1/4 。
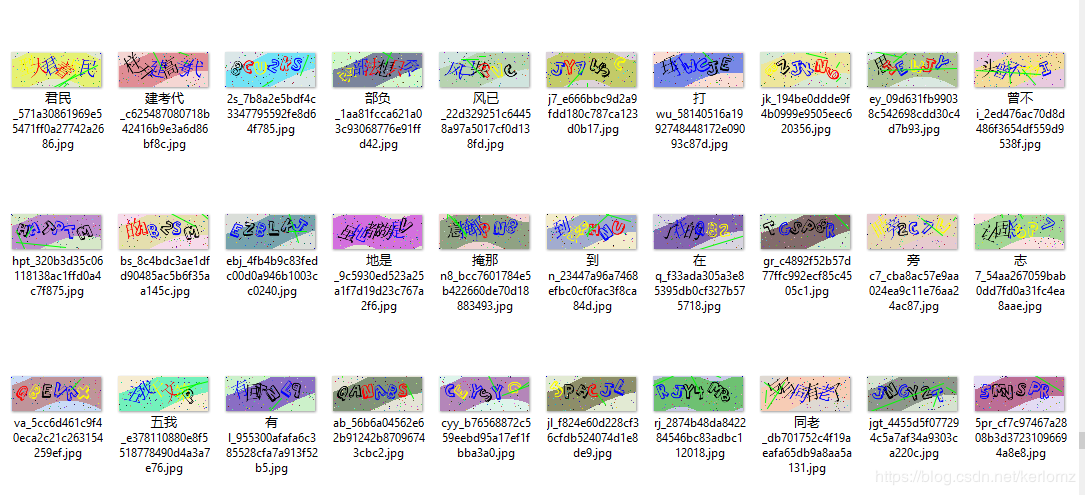
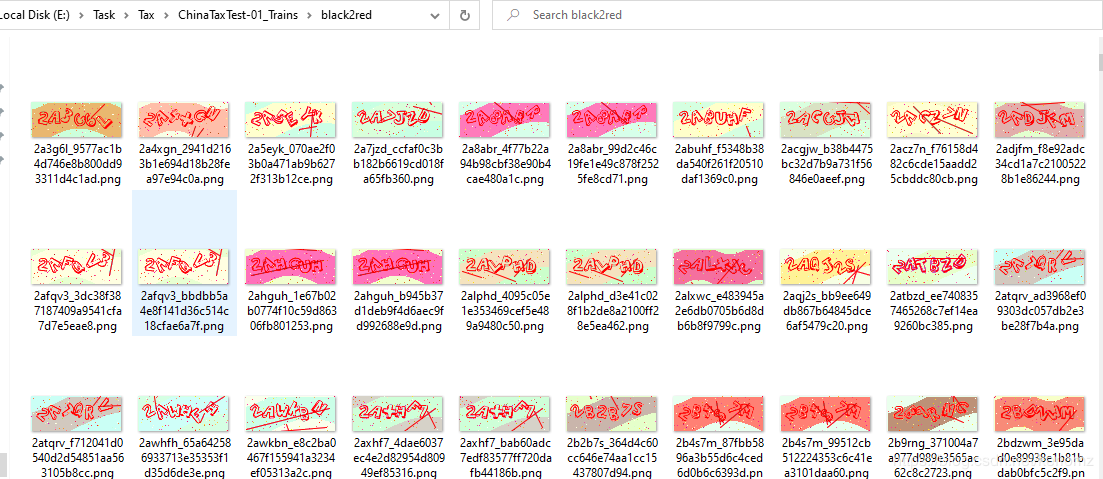
( 3 )把所有颜色都通过颜色变换为一种颜色,整体思路同( 2 )。如下图,笔者将黑色转换为红色,但是样本成本只有采集一种颜色的成本。看起来是目前位置最佳的方案了,事实也是如此的。但是呢,100w 的样本对于普通人来说也是一笔不小的花销,即便有了样本能做出来也需要花费不少的时间和精力。
不过采集样本不是单纯的接打码平台就完事了,需要经过官网判断,只有通过验证,正确的样本才保存下来。这样有效的样本对提高识别率才有帮助。
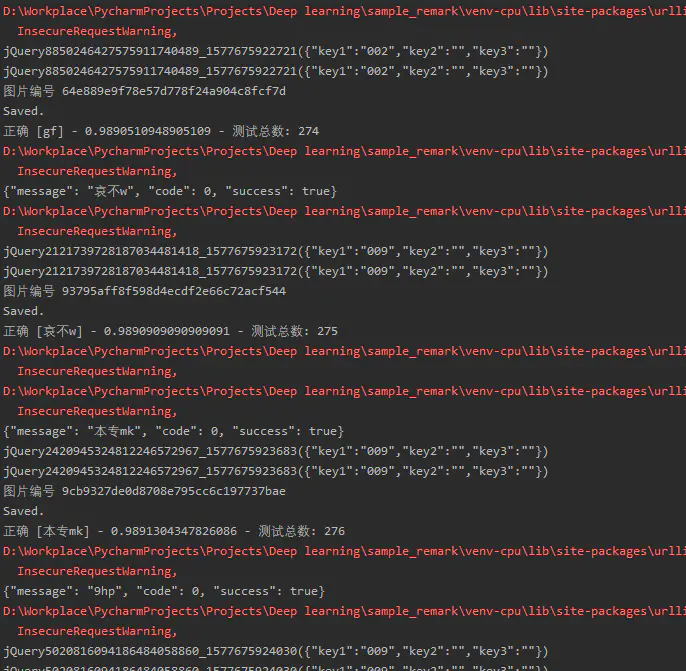
经过笔者实验,2.3 的方法性能效果最佳
笔者实时对接官网对实验模型进行检验,结果如上图,测试了 200+次,识别率达到 98%以上,识别速度的话,相较于 1.1 的方法省去了颜色提取,大大缩短了时间,CPU 大概 5-8 毫秒左右,模型大概 3mb 。
所以选择合适的方案解决问题才是最终的目的,希望这个项目和这篇介绍能带大家入门企业级的验证码识别。
