
我们总有一种感觉,机器学习门槛高、难入门。这是因为这里有太多晦涩的概念「神经网络」、「评估指标」、「优化算法」等让初学者老是有种盲人摸象的感觉。甚至连理解一个 Tensorflow 官方 Demo 都感觉吃力,因此不少开发者就有过「机器学习从入门到放弃」的经历。 本文站在全局视角,通过分析一个 TensorFlow 官方的 Demo 来达到俯瞰一个「机器学习」系统的效果,从而让读者看清这个头大象的全貌,帮助初学者入门「机器学习」。
如何理解机器学习系统
「机器学习」的目标就是利用已有答案来寻找规则,从而做出预测。 这与「传统系统」的区别在于:
- 「传统系统」的目标是获得答案
- 「机器学习」的目标是利用已有答案获得规则
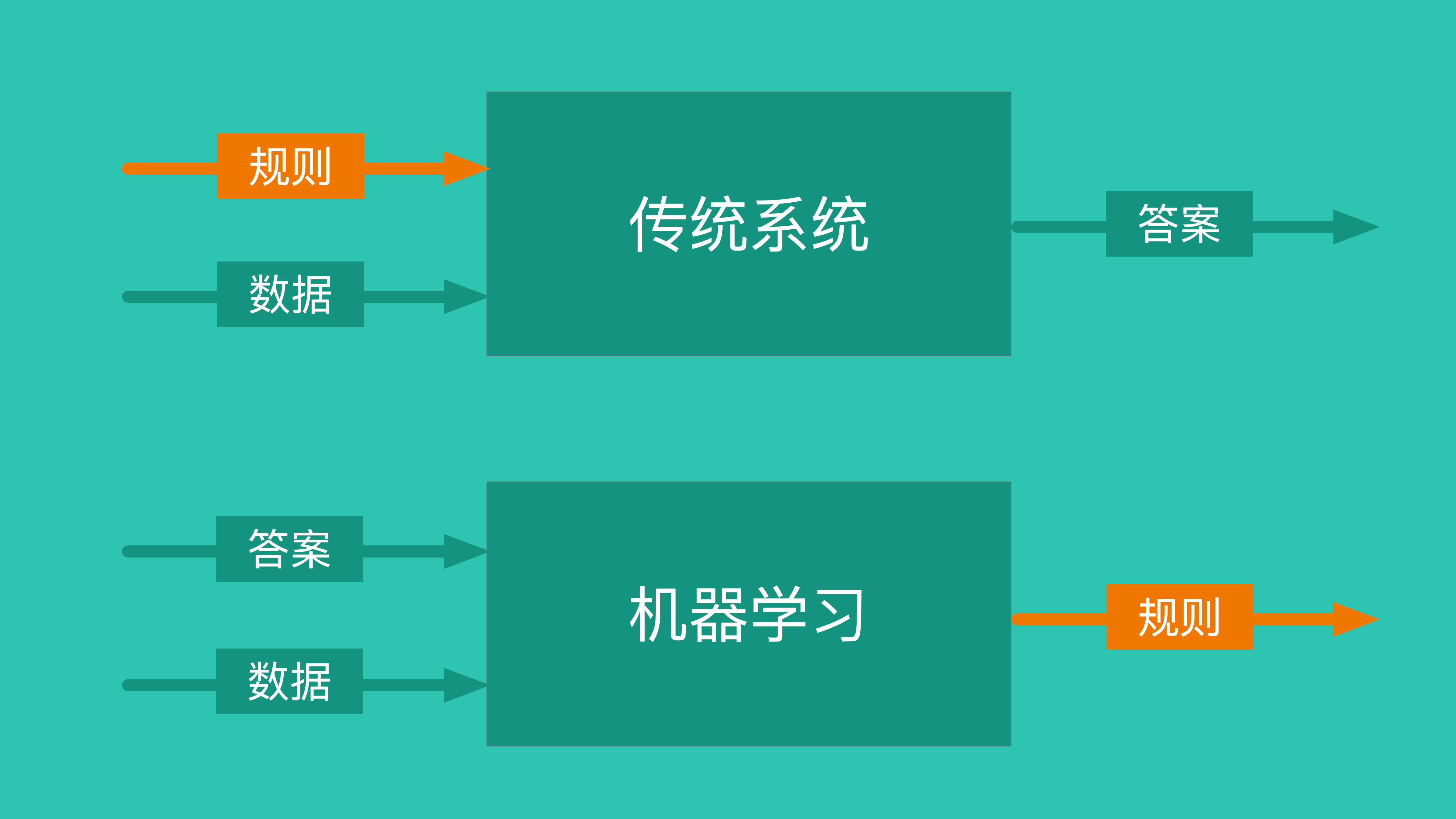
正是因为「机器学习」的目标是获得规则,人们便可以拿它来做各种预测:股票走势、彩票号码、服饰推荐、甚至预测员工何时离职。 图片识别本质上也是找到规则。比如要识别一张图片物体是否有一只猫咪,那么胡须、耳朵、绒毛等都可以作为猫咪的特征值,而定义特征值就是在定义成为一只猫的组成规则。
详解一个机器学习 Demo
学习一项技能最好方法就是去使用它。这部分我们来看一个 TensorFlow Demo 。TensorFlow 是 Google 推出的深度学习框架,基本信息我就不多做介绍了。 我要介绍的是如何读懂这个 Demo 。你可能会问,一个 Demo 有那么难懂么? 对于「机器学习」的初学者来说,如若不懂「神经网络」、「损失函数」、「评估指标」等概念,还真是挺难读懂一个 Demo 的。
看下这个 Demo,代码不多,我全部贴出来了。
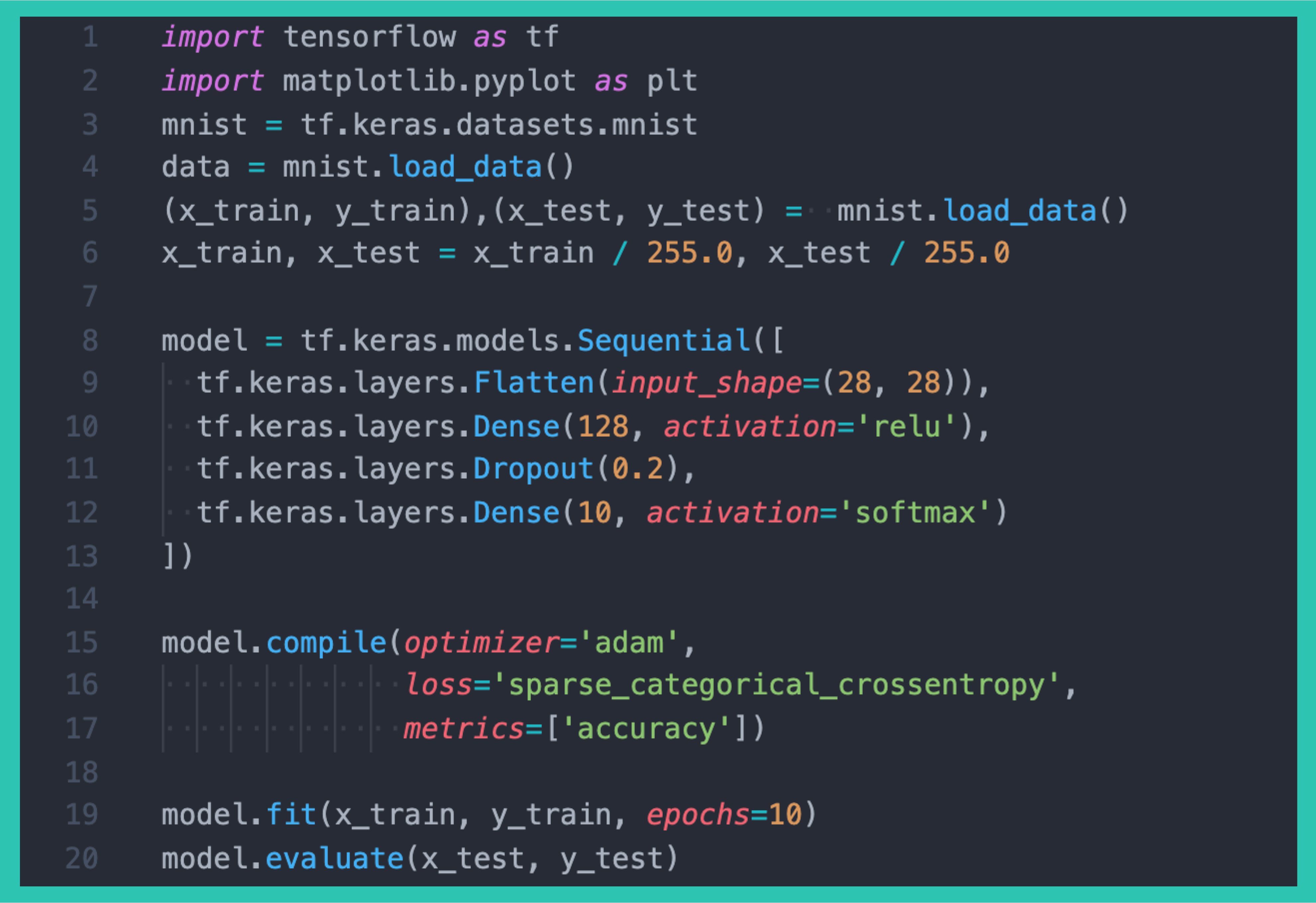
看到这部分代码的全貌,什么感觉? 我第一次读到的感觉是:「语法都能看懂,但就是不知道你这是要干啥!」 如果你也有这样的感觉,那么我建议你认真把这篇文章读完。 这个 Demo 实际上是要训练一个可以识别手写数字的模型( Model ), 要识别的手写数字长这样:

你也许一下子会有很多问号。手写数字? 图片在哪?怎么识别? 别急,下面我来为大家详解这个 Demo 。
数据准备
人工智能领域中的数据是什么?我们从 TensorFlow 这个框架的名字中就能看出来 -- Tensor (张量)形成的 Flow (流)。 在「人工智能」领域,绝大部分数据都是以 Tensor 的形式存在,而 Tensor 可以直接理解成多维数组。
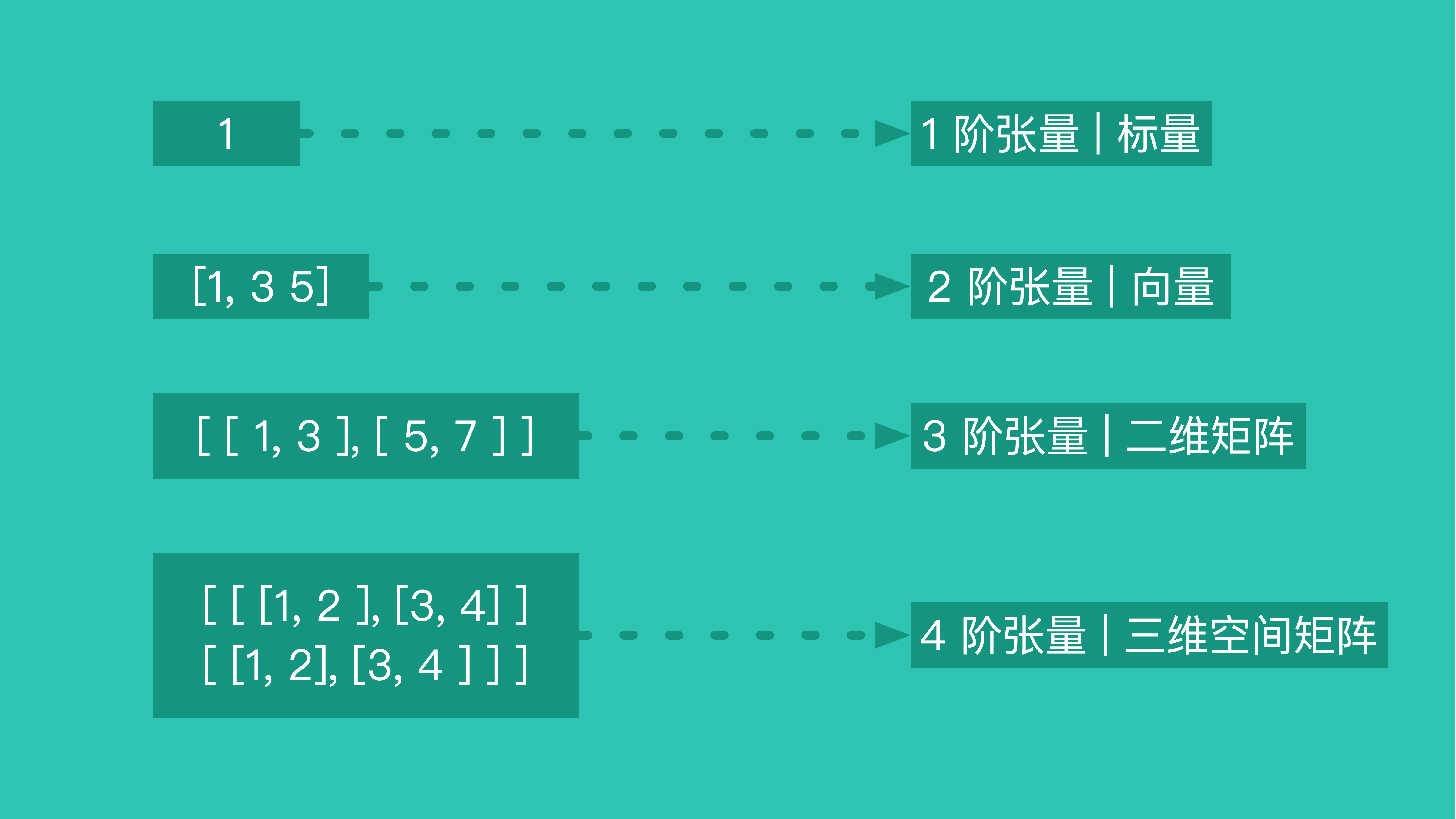
举个例子: 要把一张图片输入到人工智能模型中。 我们第一反应是要先把图片数字化,用 Base64 来表示这张图、或者用二进制等等。但是对于人工智能系统,最佳方式是把图片转换成 Tensor 。 我们试试用 Tensor 来表示一张 像素 3*3 、背景为白色、对角线为黑色的图片:

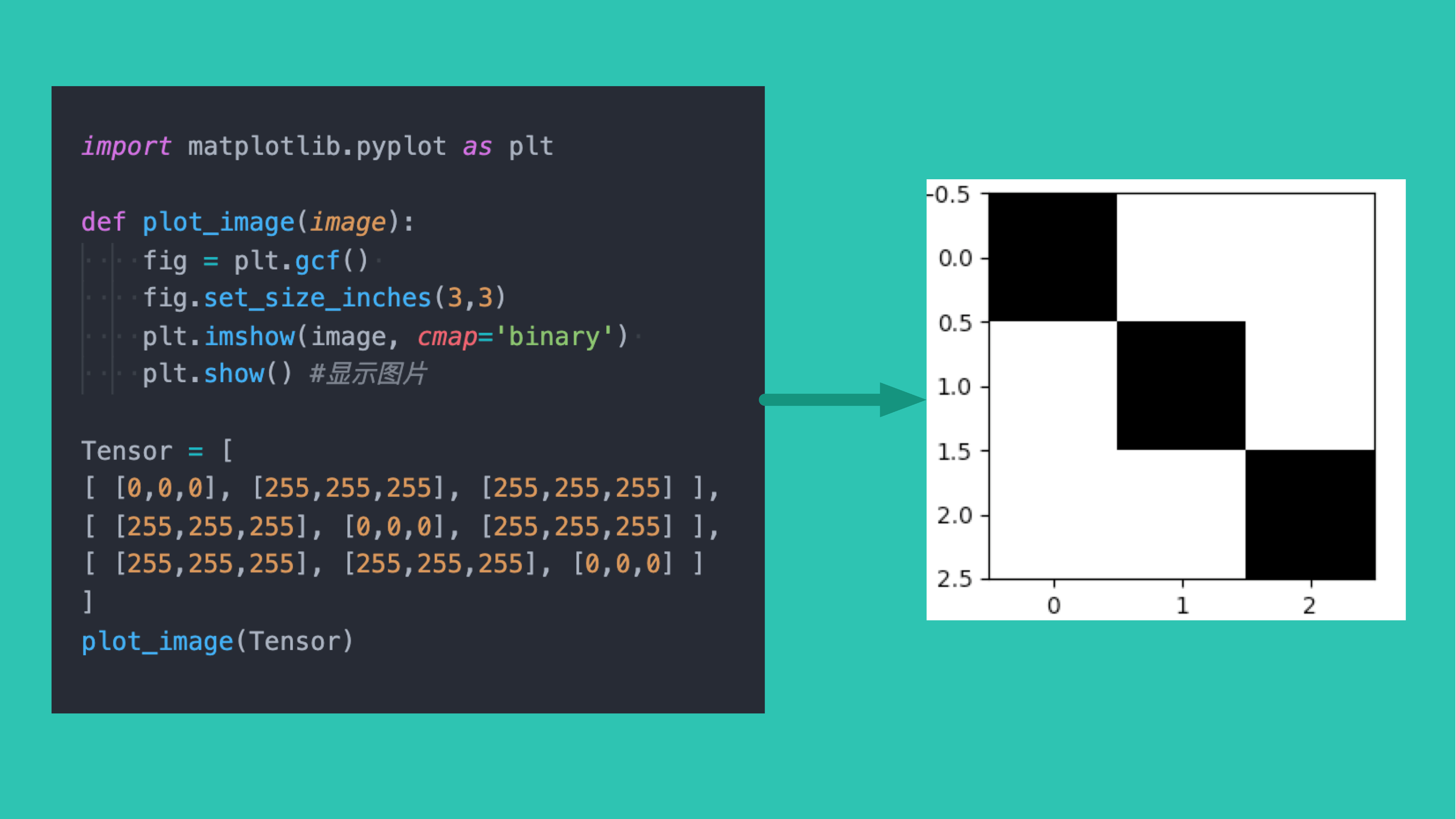
运行代码之后,我们就得到了那张对角线是黑色的 33 图片。
这就是用一个四阶 Tensor 表示一张图片,Tensor 形状为 (1, 3, 3) 。
同理如果要表示 6000 张 2828 的图片,那么 Tensor 的形状就是 (6000, 28, 28)。
现在我们阅读第一部分的代码:
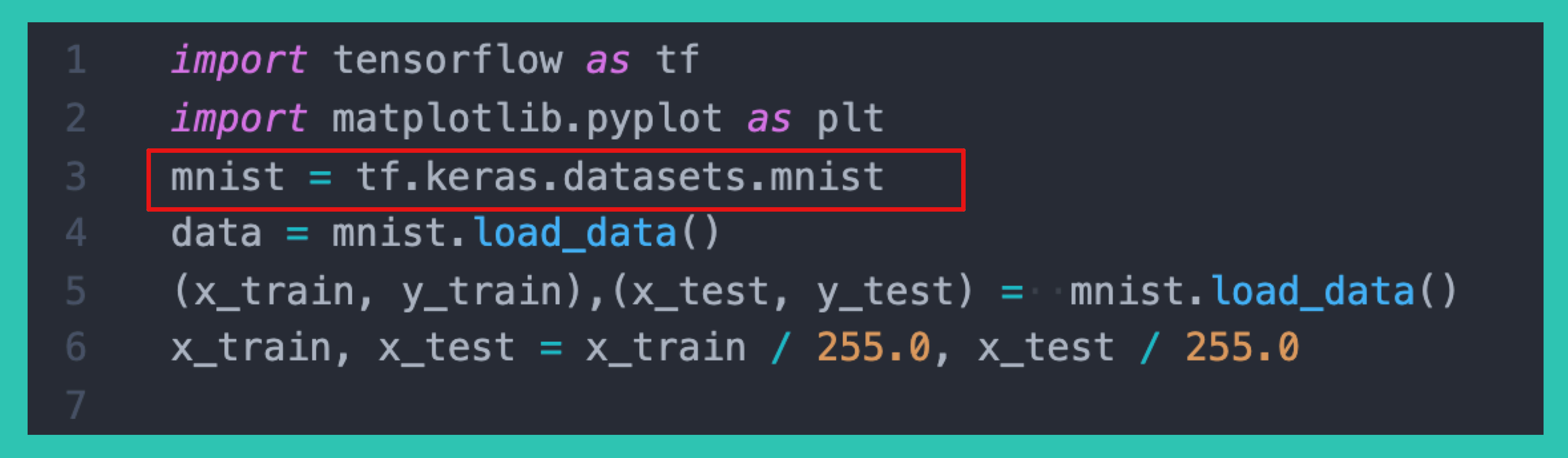
「 MNIST 」(Mixed National Institute of Standards and Technology database) 是美国国家标准与技术研究院收集整理的大型手写数字数据库,包含 60,000 个示例的训练集以及 10,000 个示例的测试集,里面的图片长这样。

这些图片都是通过空间的矩阵的方式存储的:

这样我们就明白这段代码的意思了,是从 mnist 中获取用于训练的的数据集集( x_trian,y_train ),以及用于测试的数据集( x_test,y_test )。
- x_trian 形状为 (6000, 28, 28) ,表示 6000 张 28*28 的图片。
- _trian 形状为 (6000,),表示 x_train 对应的数字答案。
模型( model )是什么
得到了数据集之后,是不是可以开始训模型了?别急,我们要搞清楚模型是什么,Tensorflow 文档是这样定义模型:
我来帮你们翻译一下这个定义:模型是个函数,这里面内置了很多参数,这些参数的值会直接影响模型的输出结果。有意思的是这些参数都是可学习的,它们可以根据训练数据的来进行调整来达到一组最优值,使得模型的输出效果最理想。
- 那么模型里参数又是什么?
- Demo 当中模型传入的 4 个 Layer 又是什么含义?

- 模型又是如何训练的? 想要知道这些问题答案,那么:「先生小姐,泳泳健身,呃不。神经网络,了解一下」
神经网络 ( Neural Network )
神经网络 ( Neural Network )顾名思义,就是用神经元 ( Neuron )连接而成的网络( Network )。 那么什么是神经元?
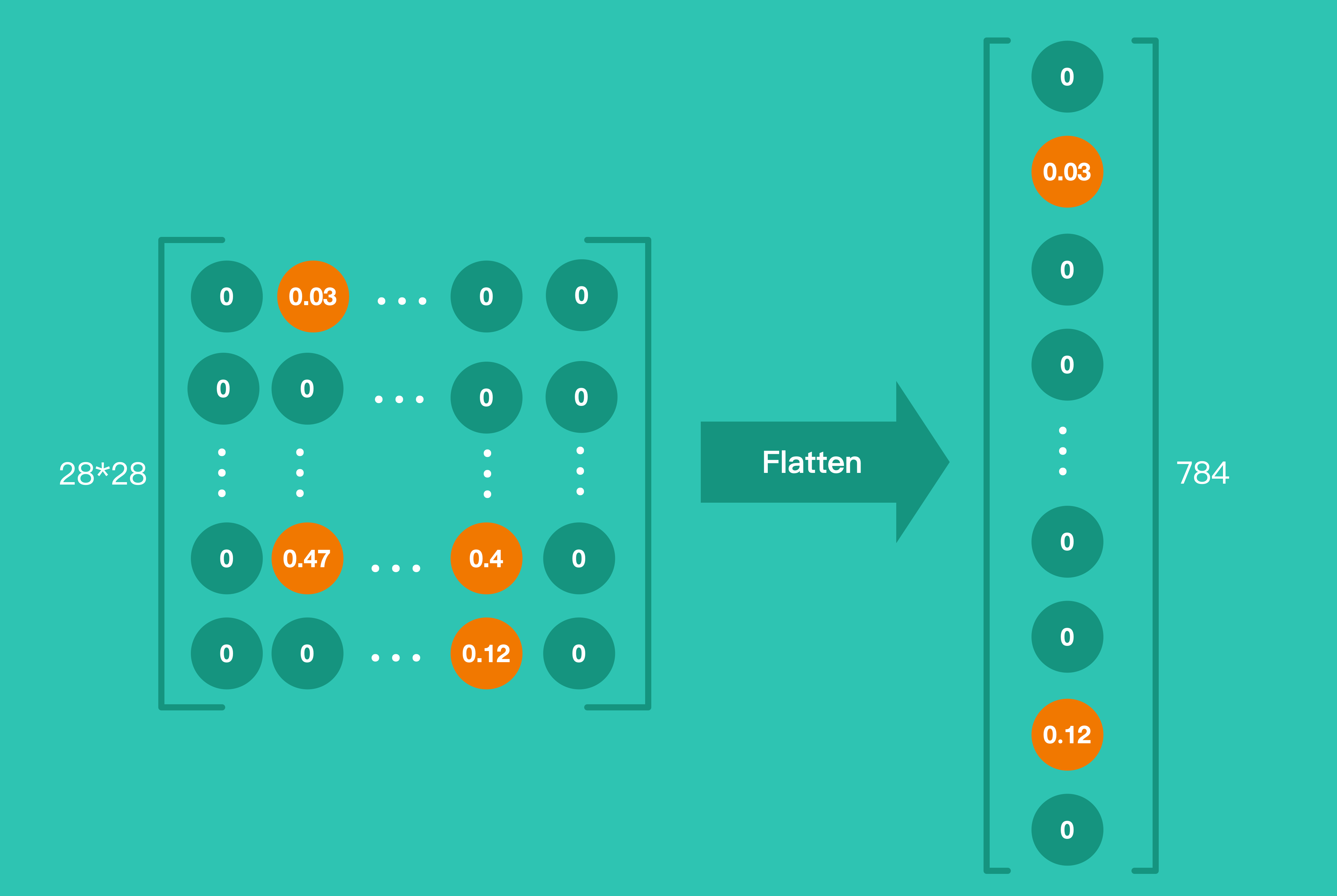
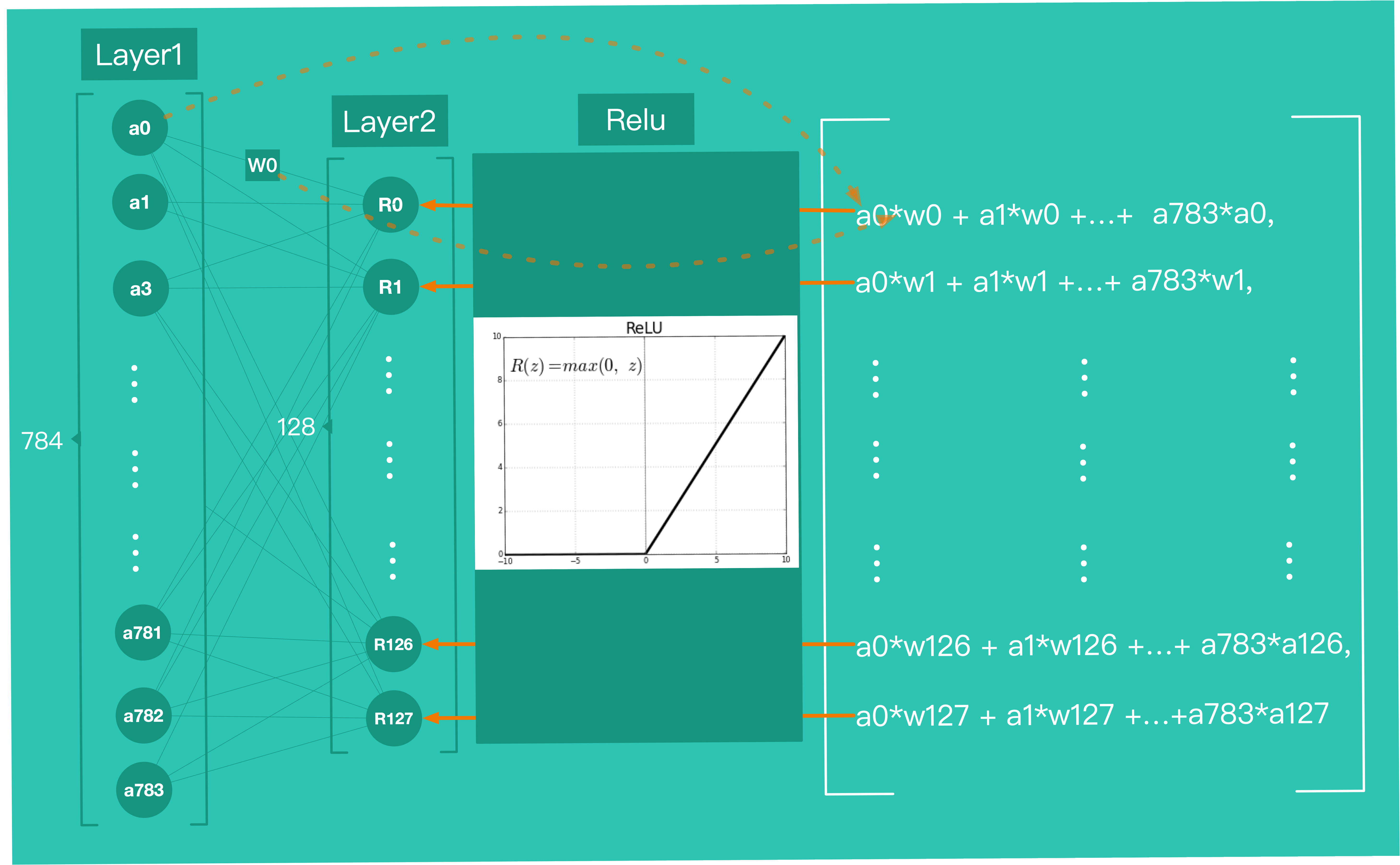
Demo 当中,第一个 Layer 就是把就是把 28*28 的图片展开成一个包含 784 个神经元一维数组。
...
# 第一个 Layer
# 神经元展开成一维数组
tf.keras.layers
.Flatten(input_shape=(28, 28)),
...
第二个 Layer:
...
tf.keras.layers
.Dense(128, activation='relu'),
...
Layer2 传入了参数 activation='relu',意思是用 relu 作为激活函数 。
我们先来理解下什么是「激活函数」,
所以 relu 是激活函数的一种,用于神经元的激活 -- 根据上一个 Layer 给予的刺激算出神经元最后输出(显示)的那个数字。
Layer2 层有 128 个神经元,这 128 个神经元会和 Layer1 中 728 个神经元相互连接,共将产生 728 * 128 =93184 权重( weights )各自不同的连接 。Layer1 中神经元的输出将与连接到 layer2 的权重值进行加权求和,得到的结果会被带入 relu 函数,最终输出一个新的值作为 Layer2 中神经元的输出。
第三个 Layer
...
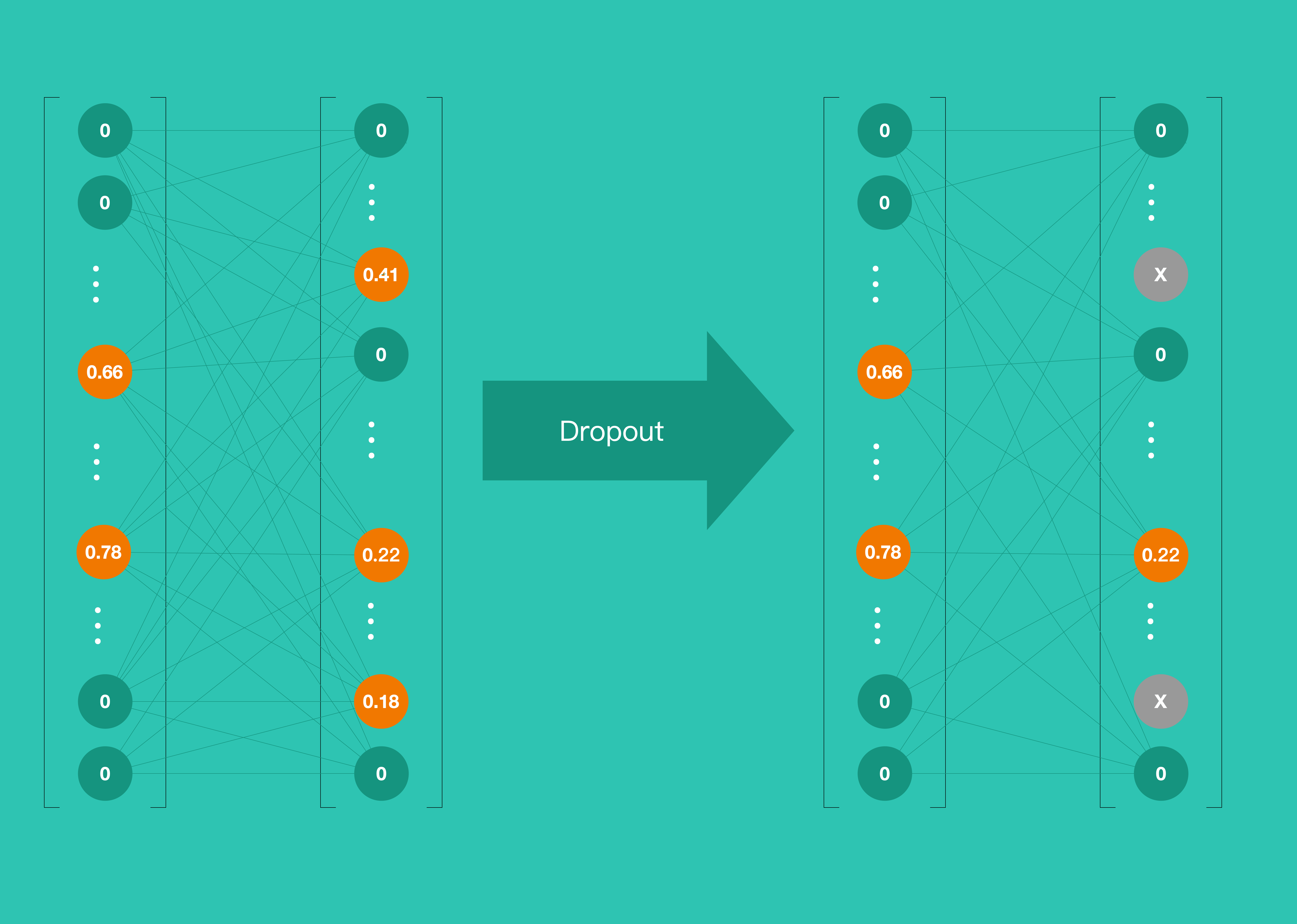
tf.keras.layers.Dropout(0.2),
Dropout layer 的主要作用就是防止过度拟合。过渡拟合现象主要表现是:最终模型在训练集上效果好;在测试集上效果差。模型泛化能力弱。 Dropout 解决过度拟合的办法之一,就是随机丢弃一部神经元。Demo 中就是使用 Dropout 随机丢弃 20% 神经元。
第四个 Layer
...t
tf.keras.layers
.Dense(10, activation='softmax')
...
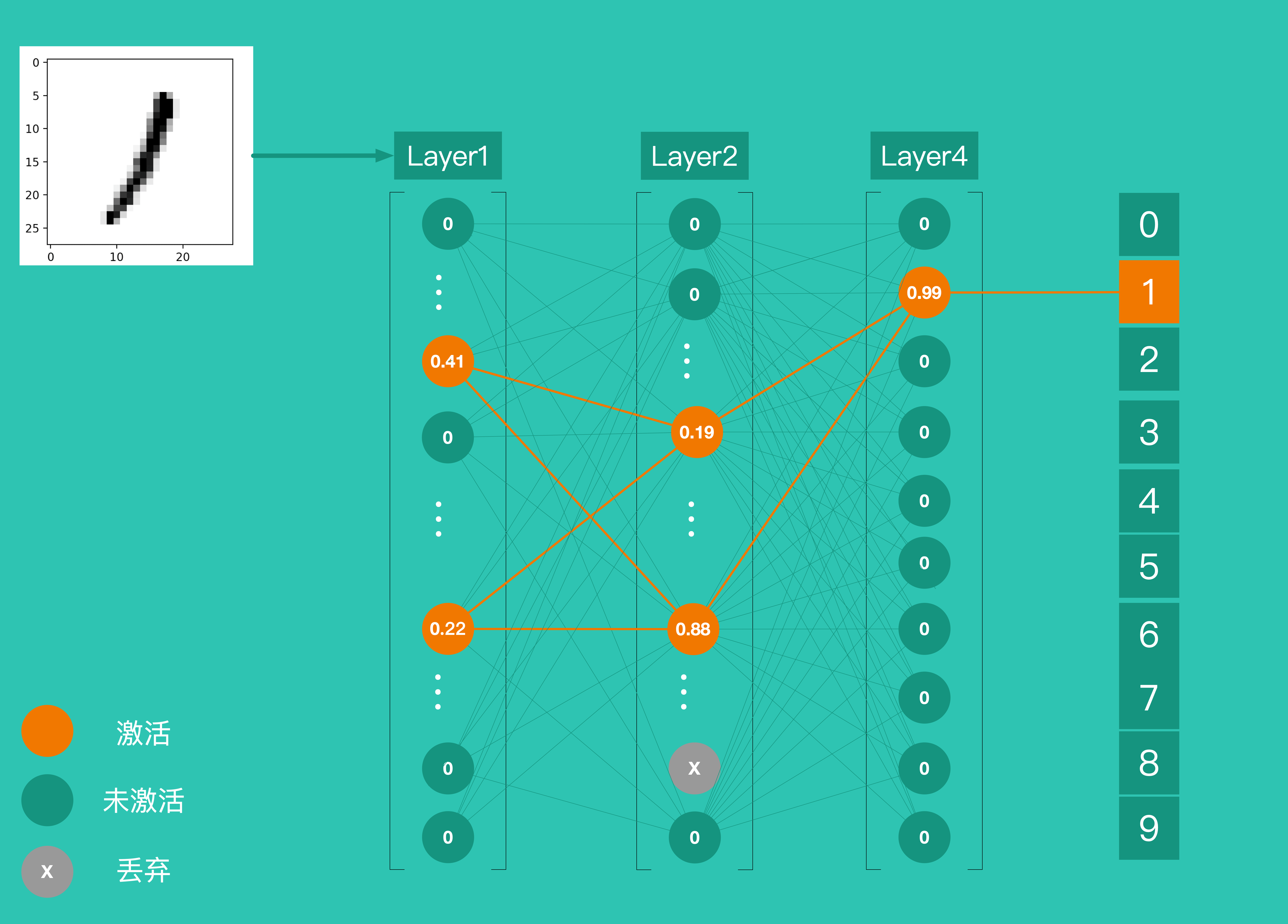
Layer4 上有 10 个神经元,并使用 softmax作为激活函数,这 10 个神经元的输出就是最终结的结果。下图为识别一个手写数字 1 的整个过程,各层神经元逐层激活,最终输出预测结果。
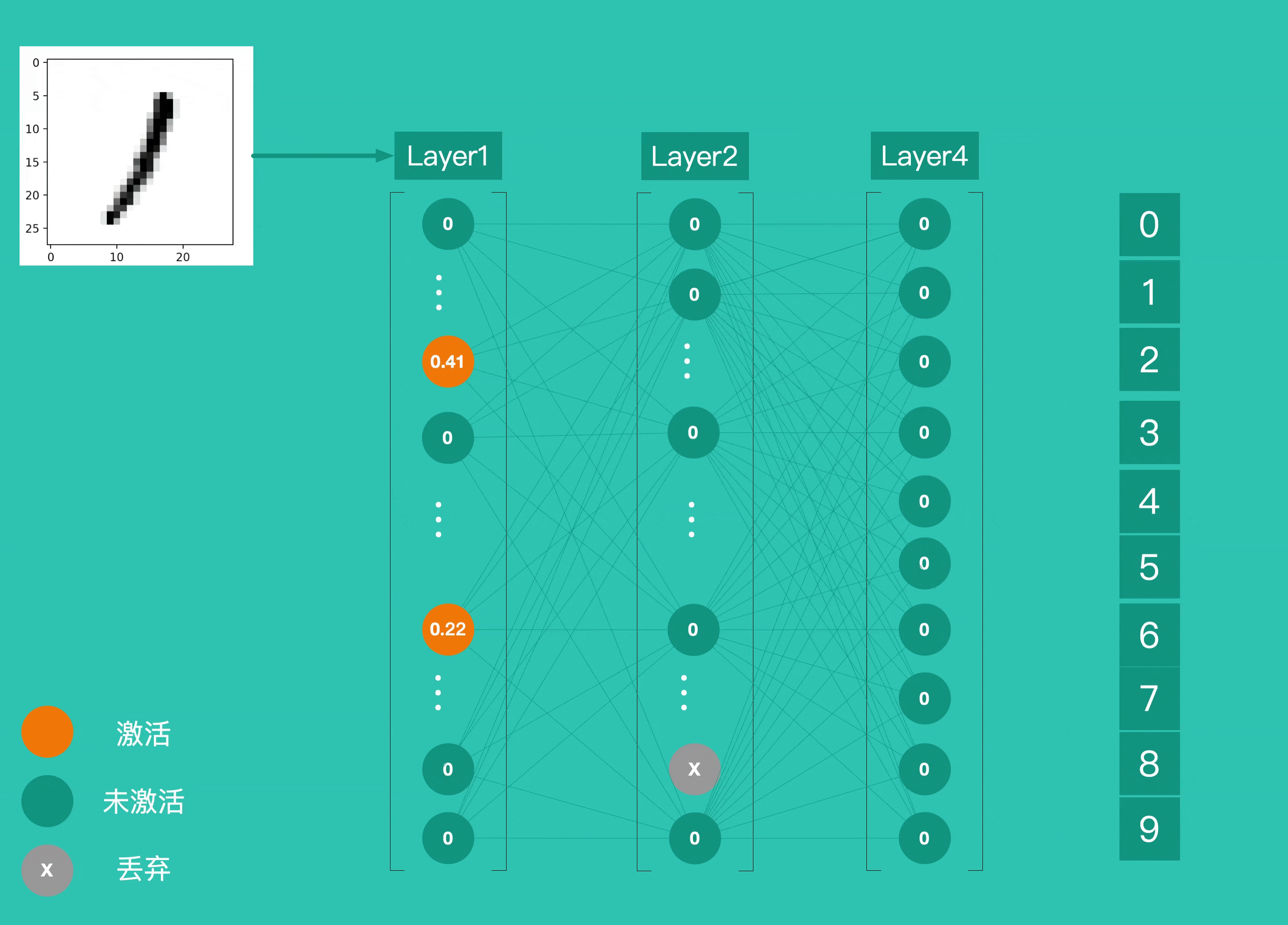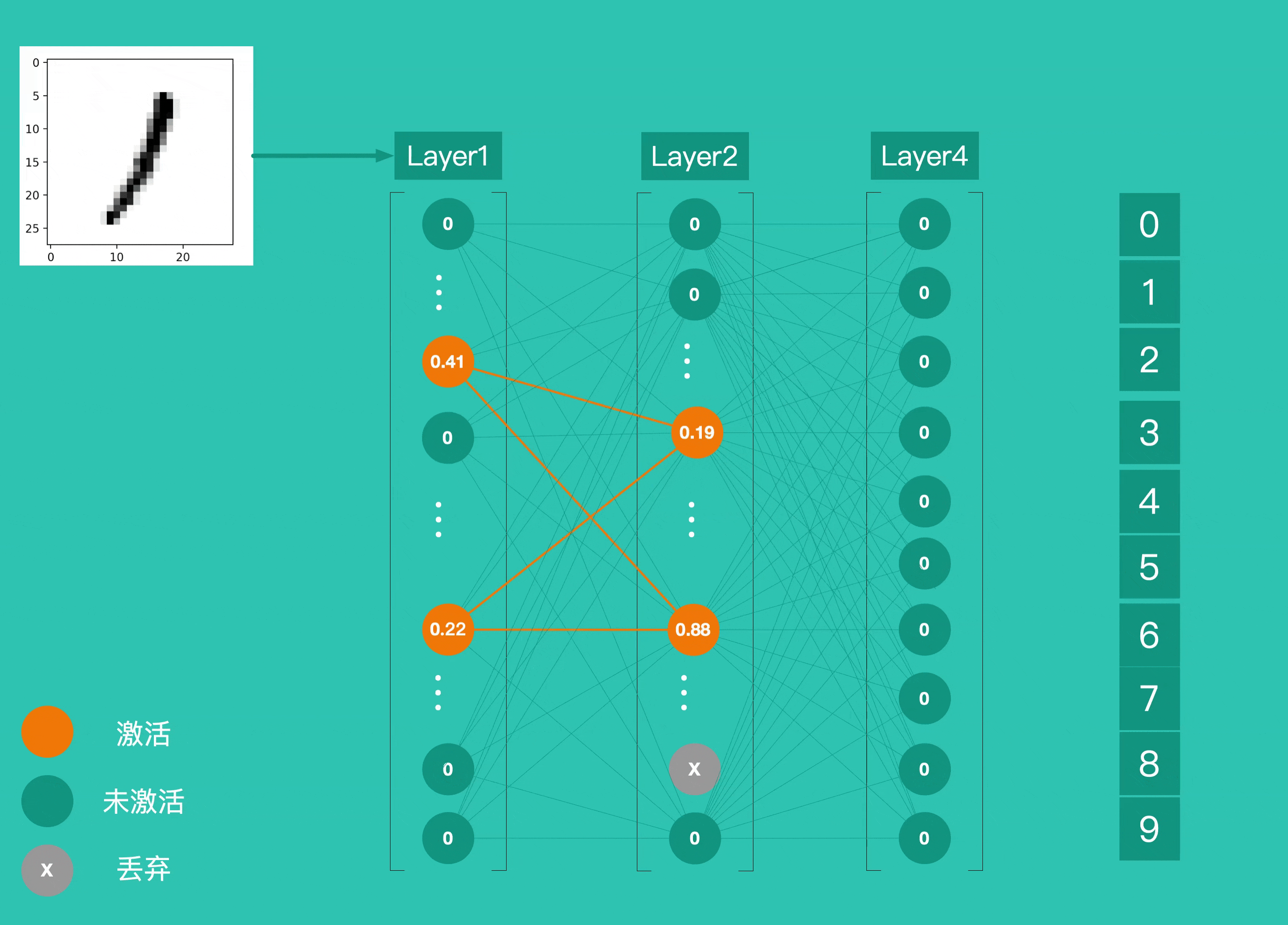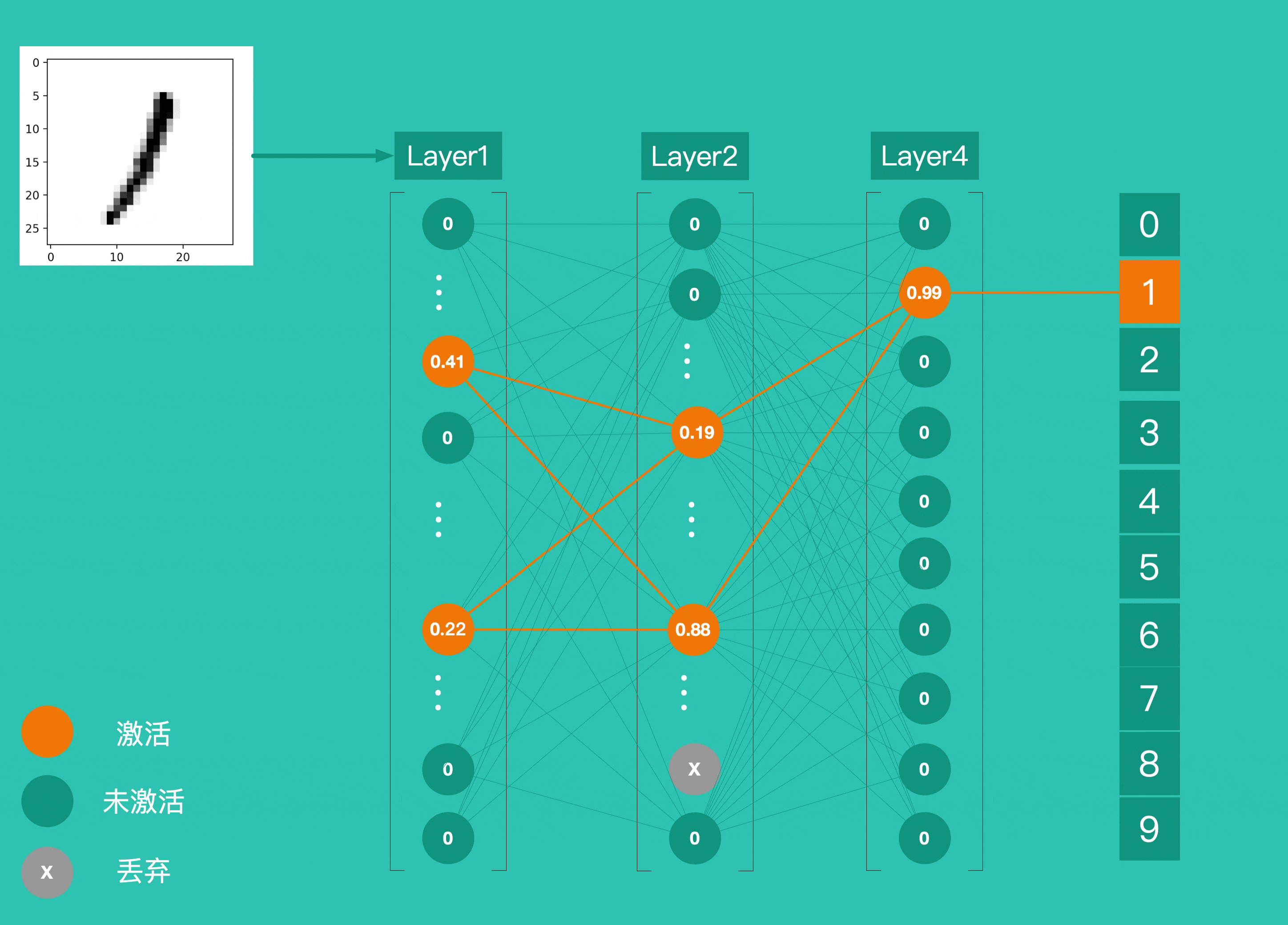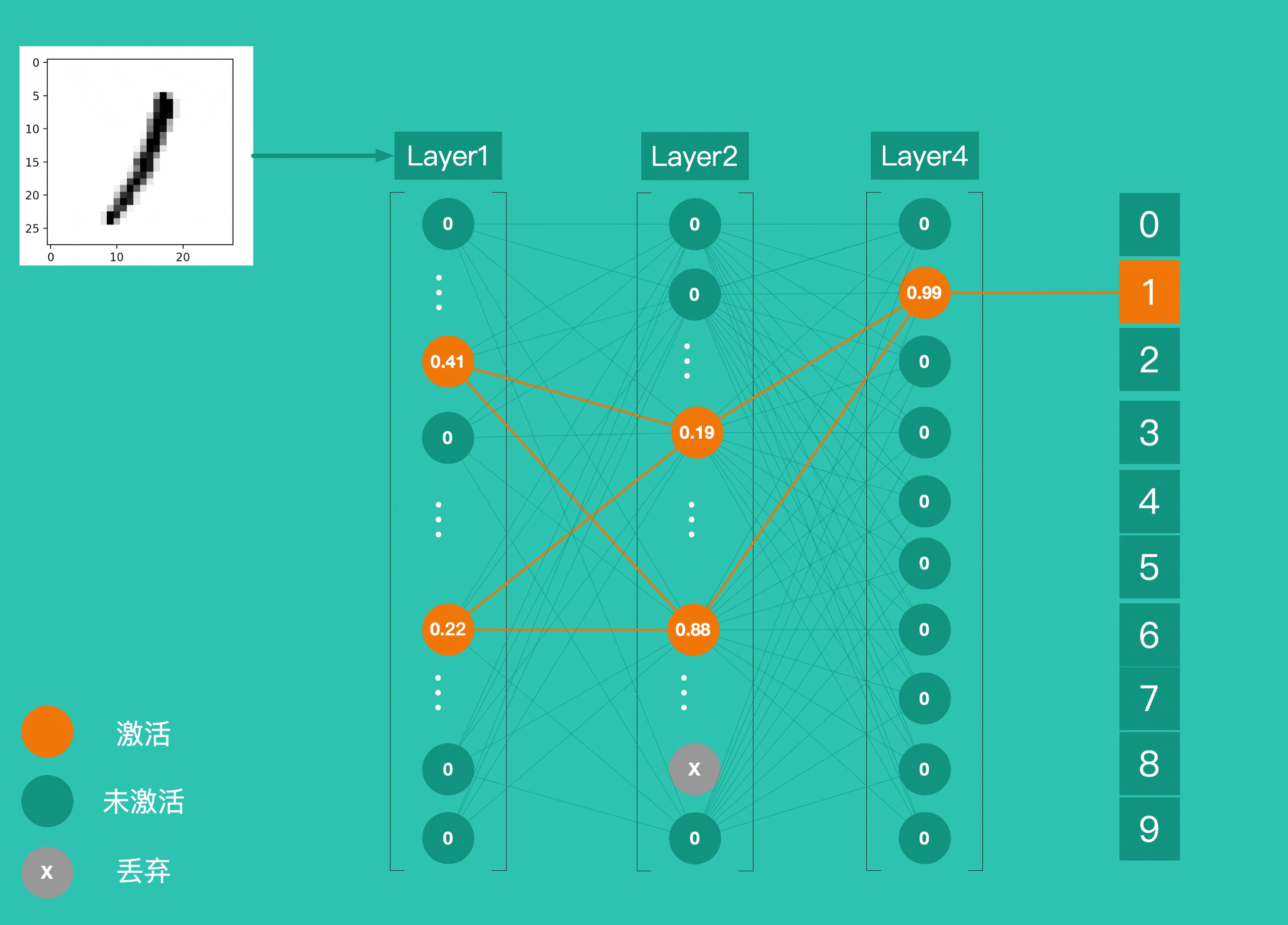
到这里,我们通过了解 4 个 Layer 之间的作用关系简单的了解了一个神经网络的运作方式。
模型训练补充

要读懂这段代码,我们要先通过一个类比来理解下什么是: 损失函数( Loss Function )、优化算法( Optimization Algorithms )、评价指标( Evaluation Metrics ) 假如一名男士要开始锻炼身体,目标是胸围达到 120cm,且身材看起来匀称(别太壮):
- 经过反复训练,他的胸围达到了 110cm,那么我们可以把
Loss = |目标( 120cm )- 当前( 110cm )|作为一个最简单的**损失函数( Loss Function )。**而 Demo 中的 Loss Function 用的是 - 稀疏类别交叉熵( sparse_categorical_crossentropy ),这个算法的特点就是擅长分类。 - 是否达成目标,不能仅仅使用损失函数来判断。身材匀称、美观也很重要,而评价指标( Evaluation Metrics )的作用就给我们提供了一个评判标准。
- 接下来我们就要寻找产生 Loss 的规律,Loss 不仅仅是胸围小于 130cm 的损失,胸围大于 130cm 而导致美感损失也是 Loss 的一部分。因此想达到最佳效果,既不能练的太轻也不能练的太用力。我们给予训练要素不同的权重( Weights ),蛋白质补充权重为 w0 、胸肌上沿训练强度 w1 、胸肌中部训练强度 w2 、胸肌下沿训练强度 w3 、有氧运动训练强度 w4,等等的影响因素我们都加上不同的权重。最后得到一组 [w1, w2...wn] 。而通过不断调整[w1, w2...wn] 得出最佳胸肌锻炼的方法,就是优化算法( Optimization Algorithms )。 了神经网络的模型、层、权重、优化算法、损失函数以及评估指标等之后,我们就可以读懂 Demo 中那段代码了。现在尝试画一张神经网络的工作流程图,串一串一个神经网络的工作流程。
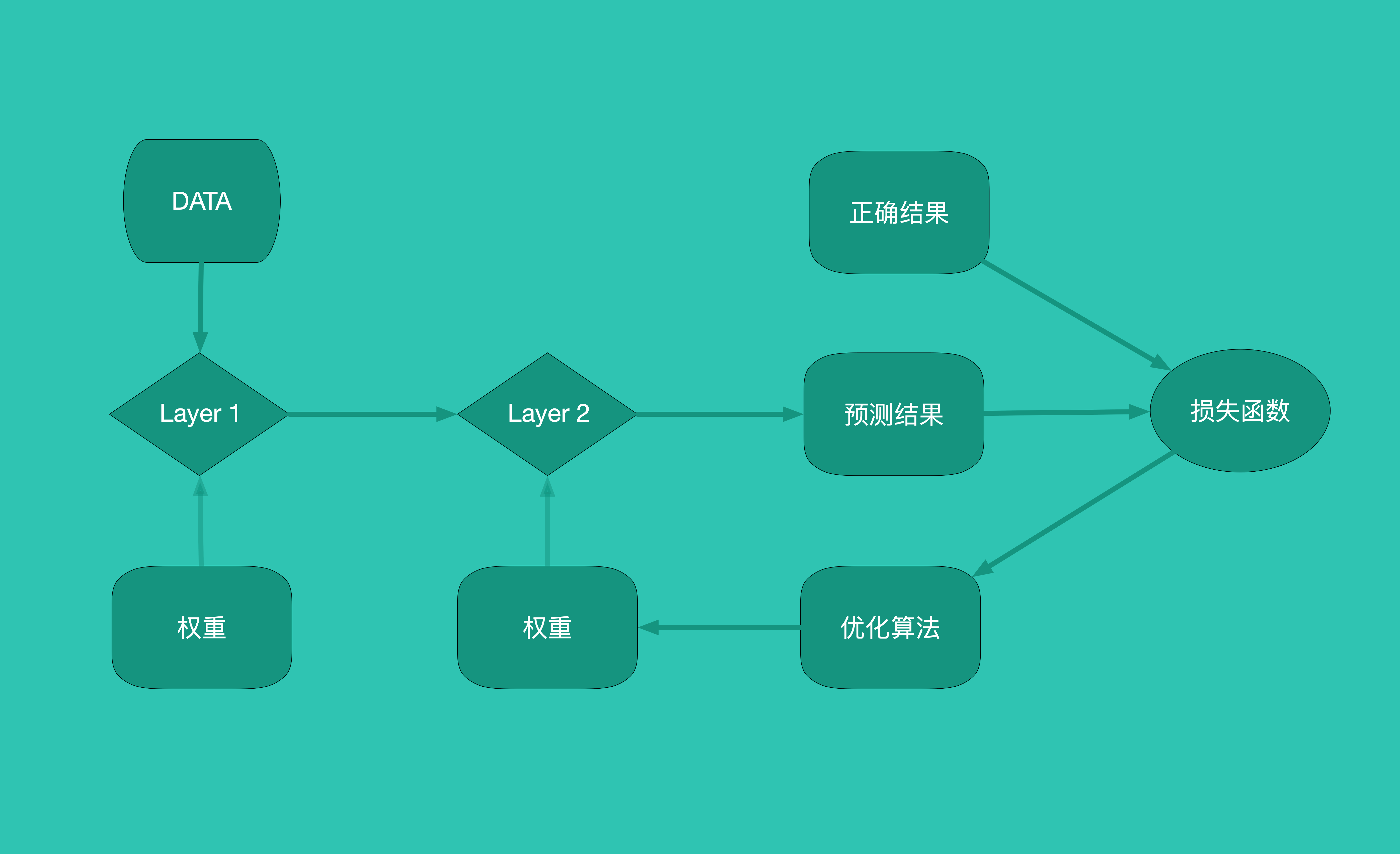
训练与测试

这部分很好理解,带入数据训练、测试就好。
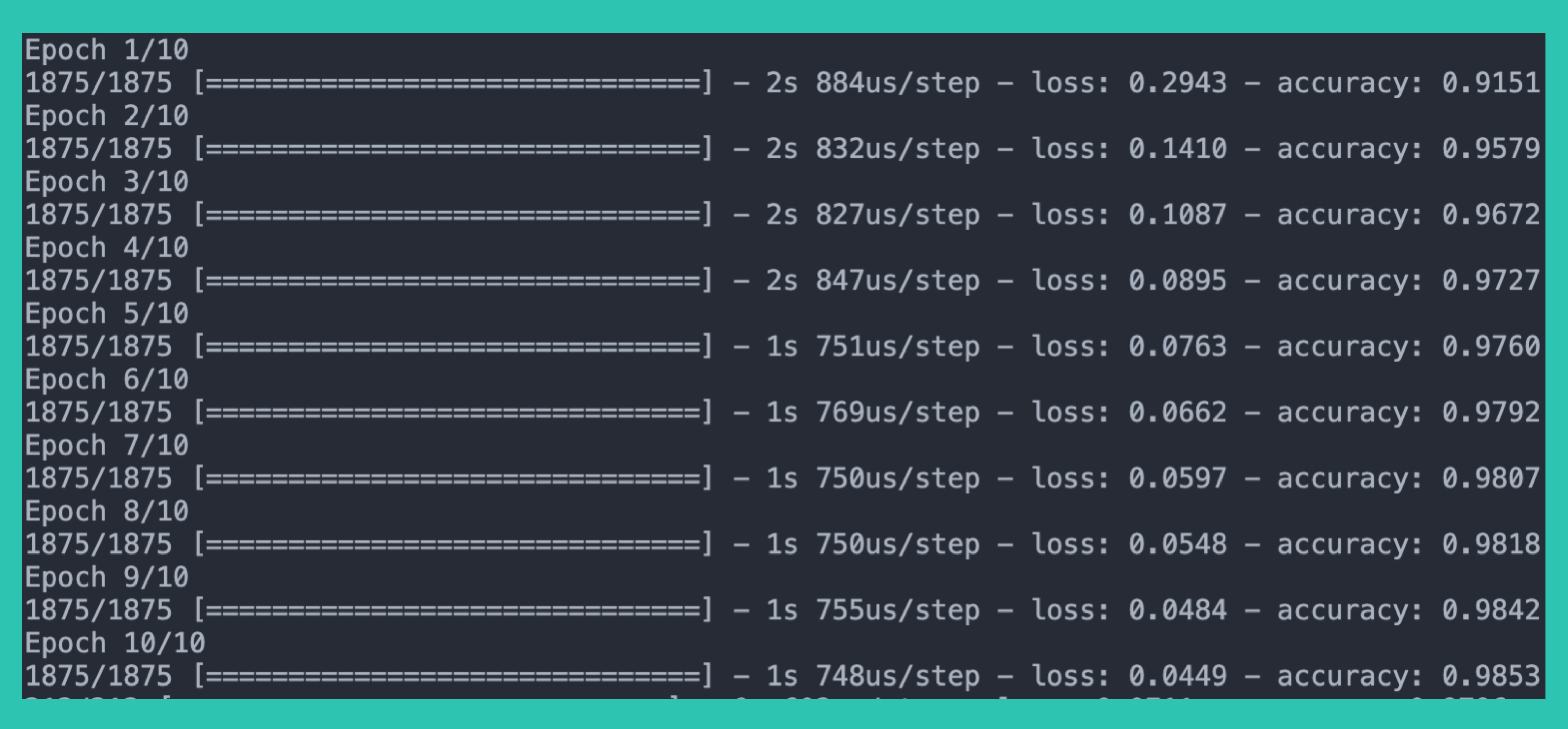
说一下 epochs 。
在神经网络领域,一个 epoch 是指整个训练数据集的训练一个周期。
1 epoch = 1 正向传播( forward pass )+ 1 反向传播( backward pass )(我们可以简单的理解,正向传播目的是为了获得预测结果,反向传播目的是调整到最优的权重( weights ),来让 Loss 最小化。)
Demo 中 epochs = 5 是因为 1 次 epoch 很可能得不到最优的权重( weights )。 既然 1 次不能满足,那就 5 次,5 次还不满足就 10 次,直到效果最小化 Loss 的效果不再变化。
总结
如果认真阅读了本文,那么我相信你已经对人工智能已经有了一点整体的认识,本文给了你一个鸟瞰人工智能的视角,摆脱了盲人摸象的感觉。这虽然不是魔法,能立刻把你变成人工智能大神,但对基本架构的进一步理解会增强你对人工智能的自学能力。无论你是从事前端、后端、全栈等技术开发者,或者只是对人工智能感兴趣,我都希望本文可以带给你一个新的视角去理解人工智能,让你读有所思,思有所得,得有所想,想有所获,或有所益。
如果你在阅读之后认为本文对你有帮助,请点关注我的公众号「东泽聊技术」。








