
这是一个创建于 1641 天前的主题,其中的信息可能已经有所发展或是发生改变。
该系列文章总共分为三篇:
Cgroup 是 Linux kernel 的一项功能:它是在一个系统中运行的层级制进程组,你可对其进行资源分配(如 CPU 时间、系统内存、网络带宽或者这些资源的组合)。通过使用 cgroup,系统管理员在分配、排序、拒绝、管理和监控系统资源等方面,可以进行精细化控制。硬件资源可以在应用程序和用户间智能分配,从而增加整体效率。
cgroup 和 namespace 类似,也是将进程进行分组,但它的目的和 namespace 不一样,namespace 是为了隔离进程组之间的资源,而 cgroup 是为了对一组进程进行统一的资源监控和限制。
cgroup 分 v1 和 v2 两个版本,v1 实现较早,功能比较多,但是由于它里面的功能都是零零散散的实现的,所以规划的不是很好,导致了一些使用和维护上的不便,v2 的出现就是为了解决 v1 中这方面的问题,在最新的 4.5 内核中,cgroup v2 声称已经可以用于生产环境了,但它所支持的功能还很有限,随着 v2 一起引入内核的还有 cgroup namespace 。v1 和 v2 可以混合使用,但是这样会更复杂,所以一般没人会这样用。
1. 为什么需要 cgroup
在 Linux 里,一直以来就有对进程进行分组的概念和需求,比如 session group,progress group 等,后来随着人们对这方面的需求越来越多,比如需要追踪一组进程的内存和 IO 使用情况等,于是出现了 cgroup,用来统一将进程进行分组,并在分组的基础上对进程进行监控和资源控制管理等。
2. 什么是 cgroup
术语 cgroup 在不同的上下文中代表不同的意思,可以指整个 Linux 的 cgroup 技术,也可以指一个具体进程组。
cgroup 是 Linux 下的一种将进程按组进行管理的机制,在用户层看来,cgroup 技术就是把系统中的所有进程组织成一颗一颗独立的树,每棵树都包含系统的所有进程,树的每个节点是一个进程组,而每颗树又和一个或者多个 subsystem 关联,树的作用是将进程分组,而 subsystem 的作用就是对这些组进行操作。cgroup 主要包括下面两部分:
- subsystem : 一个 subsystem 就是一个内核模块,他被关联到一颗 cgroup 树之后,就会在树的每个节点(进程组)上做具体的操作。subsystem 经常被称作
resource controller,因为它主要被用来调度或者限制每个进程组的资源,但是这个说法不完全准确,因为有时我们将进程分组只是为了做一些监控,观察一下他们的状态,比如 perf_event subsystem 。到目前为止,Linux 支持 12 种 subsystem,比如限制 CPU 的使用时间,限制使用的内存,统计 CPU 的使用情况,冻结和恢复一组进程等,后续会对它们一一进行介绍。 - hierarchy : 一个
hierarchy可以理解为一棵 cgroup 树,树的每个节点就是一个进程组,每棵树都会与零到多个subsystem关联。在一颗树里面,会包含 Linux 系统中的所有进程,但每个进程只能属于一个节点(进程组)。系统中可以有很多颗 cgroup 树,每棵树都和不同的 subsystem 关联,一个进程可以属于多颗树,即一个进程可以属于多个进程组,只是这些进程组和不同的 subsystem 关联。目前 Linux 支持 12 种 subsystem,如果不考虑不与任何 subsystem 关联的情况( systemd 就属于这种情况),Linux 里面最多可以建 12 颗 cgroup 树,每棵树关联一个 subsystem,当然也可以只建一棵树,然后让这棵树关联所有的 subsystem 。当一颗 cgroup 树不和任何 subsystem 关联的时候,意味着这棵树只是将进程进行分组,至于要在分组的基础上做些什么,将由应用程序自己决定,systemd就是一个这样的例子。
3. 将资源看作一块饼
在 CentOS 7 系统中(包括 Red Hat Enterprise Linux 7 ),通过将 cgroup 层级系统与 systemd 单位树捆绑,可以把资源管理设置从进程级别移至应用程序级别。默认情况下,systemd 会自动创建 slice、scope 和 service 单位的层级(具体的意思稍后再解释),来为 cgroup 树提供统一结构。可以通过 systemctl 命令创建自定义 slice 进一步修改此结构。
如果我们将系统的资源看成一块馅饼,那么所有资源默认会被划分为 3 个 cgroup:System, User 和 Machine。每一个 cgroup 都是一个 slice,每个 slice 都可以有自己的子 slice,如下图所示:
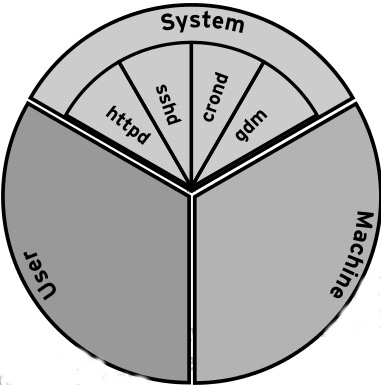
下面我们以 CPU 资源为例,来解释一下上图中出现的一些关键词。
如上图所示,系统默认创建了 3 个顶级 slice(System, User 和 Machine),每个 slice 都会获得相同的 CPU 使用时间(仅在 CPU 繁忙时生效),如果 user.slice 想获得 100% 的 CPU 使用时间,而此时 CPU 比较空闲,那么 user.slice 就能够如愿以偿。这三种顶级 slice 的含义如下:
- system.slice —— 所有系统 service 的默认位置
- user.slice —— 所有用户会话的默认位置。每个用户会话都会在该 slice 下面创建一个子 slice,如果同一个用户多次登录该系统,仍然会使用相同的子 slice 。
- machine.slice —— 所有虚拟机和 Linux 容器的默认位置
控制 CPU 资源使用的其中一种方法是 shares。shares 用来设置 CPU 的相对值(你可以理解为权重),并且是针对所有的 CPU (内核),默认值是 1024 。因此在上图中,httpd, sshd, crond 和 gdm 的 CPU shares 均为 1024,System, User 和 Machine 的 CPU shares 也是 1024。
假设该系统上运行了 4 个 service,登录了两个用户,还运行了一个虚拟机。同时假设每个进程都要求使用尽可能多的 CPU 资源(每个进程都很繁忙)。
system.slice会获得33.333%的 CPU 使用时间,其中每个 service 都会从 system.slice 分配的资源中获得1/4的 CPU 使用时间,即8.25%的 CPU 使用时间。user.slice会获得33.333%的 CPU 使用时间,其中每个登录的用户都会获得16.5%的 CPU 使用时间。假设有两个用户:tom和jack,如果 tom 注销登录或者杀死该用户会话下的所有进程,jack 就能够使用33.333%的 CPU 使用时间。machine.slice会获得33.333%的 CPU 使用时间,如果虚拟机被关闭或处于 idle 状态,那么 system.slice 和 user.slice 就会从这33.333%的 CPU 资源里分别获得50%的 CPU 资源,然后均分给它们的子 slice 。
如果想严格控制 CPU 资源,设置 CPU 资源的使用上限,即不管 CPU 是否繁忙,对 CPU 资源的使用都不能超过这个上限。可以通过以下两个参数来设置:
cpu.cfs_period_us = 统计 CPU 使用时间的周期,单位是微秒( us )
cpu.cfs_quota_us = 周期内允许占用的 CPU 时间(指单核的时间,多核则需要在设置时累加)
systemctl 可以通过 CPUQuota 参数来设置 CPU 资源的使用上限。例如,如果你想将用户 tom 的 CPU 资源使用上限设置为 20%,可以执行以下命令:
$ systemctl set-property user-1000.slice CPUQuota=20%
在使用命令 systemctl set-property 时,可以使用 tab 补全:
$ systemctl set-property user-1000.slice
AccuracySec= CPUAccounting= Environment= LimitCPU= LimitNICE= LimitSIGPENDING= SendSIGKILL=
BlockIOAccounting= CPUQuota= Group= LimitDATA= LimitNOFILE= LimitSTACK= User=
BlockIODeviceWeight= CPUShares= KillMode= LimitFSIZE= LimitNPROC= MemoryAccounting= WakeSystem=
BlockIOReadBandwidth= DefaultDependencies= KillSignal= LimitLOCKS= LimitRSS= MemoryLimit=
BlockIOWeight= DeviceAllow= LimitAS= LimitMEMLOCK= LimitRTPRIO= Nice=
BlockIOWriteBandwidth= DevicePolicy= LimitCORE= LimitMSGQUEUE= LimitRTTIME= SendSIGHUP=
这里有很多属性可以设置,但并不是所有的属性都是用来设置 cgroup 的,我们只需要关注 Block, CPU 和 Memory。
如果你想通过配置文件来设置 cgroup,service 可以直接在 /etc/systemd/system/xxx.service.d 目录下面创建相应的配置文件,slice 可以直接在 /run/systemd/system/xxx.slice.d 目录下面创建相应的配置文件。事实上通过 systemctl 命令行工具设置 cgroup 也会写到该目录下的配置文件中:
$ cat /run/systemd/system/user-1000.slice.d/50-CPUQuota.conf
[Slice]
CPUQuota=20%
查看对应的 cgroup 参数:
$ cat /sys/fs/cgroup/cpu,cpuacct/user.slice/user-1000.slice/cpu.cfs_period_us
100000
$ cat /sys/fs/cgroup/cpu,cpuacct/user.slice/user-1000.slice/cpu.cfs_quota_us
20000
这表示用户 tom 在一个使用周期内(100 毫秒)可以使用 20 毫秒的 CPU 时间。不管 CPU 是否空闲,该用户使用的 CPU 资源都不会超过这个限制。
CPUQuota的值可以超过 100%,例如:如果系统的 CPU 是多核,且CPUQuota的值为200%,那么该 slice 就能够使用 2 核的 CPU 时间。
4. 总结
本文主要介绍了 cgroup 的一些基本概念,包括其在 CentOS 系统中的默认设置和控制工具,以 CPU 为例阐述 cgroup 如何对资源进行控制。下一篇文章将会通过具体的示例来观察不同的 cgroup 设置对性能的影响。
5. 参考资料

 |
2
Livid MOD |