vec = DictVectorizer()
X = vec.fit_transform(feature_list).toarray()
数据格式如下:
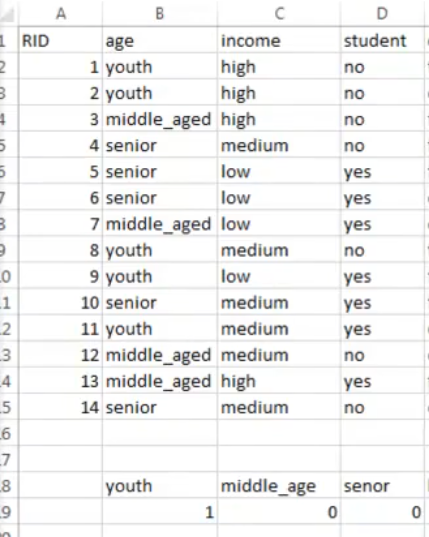
age 特征有 3 个值
youth, middle_age , sesor
然后向量化后就变成了
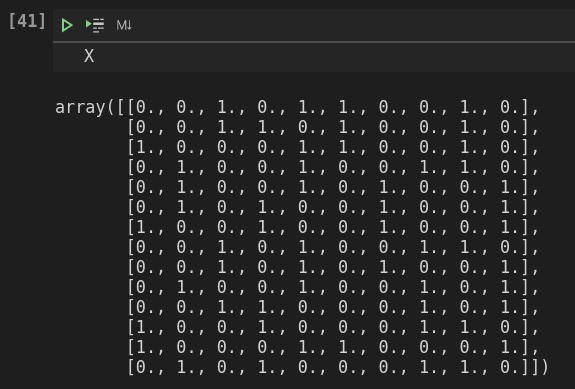
这样得到的结果是不是就不准了?

vec = DictVectorizer()
X = vec.fit_transform(feature_list).toarray()
数据格式如下:
age 特征有 3 个值
youth, middle_age , sesor
然后向量化后就变成了
这样得到的结果是不是就不准了?
 |
1
necomancer Jul 20, 2021
取决于你对 feature 的理解和怎么建模,比如你可以 low=1, medium=2, high=3,因为 low-high 之间距离大于 medium 到 high 的距离似乎也挺合理的。但向量化
low medium high (01) (01) (01) 比如你有一个 feature 对应 low,则给出向量 1 0 0 high 则是 0 0 1 这样做是为了两两间等距,并且是一组正交基。一般用于你的离散 feature 之间等权且没什么关联。 |
 |
2
yagamil OP @necomancer 谢谢回复.
如果特征里面的不同值有 4 个,5 个,是不是就无法用 0 和 1 表达了你? |
|
3
necomancer Jul 22, 2021
|
 |
4
princelai Jul 22, 2021
更常用的是 one hot 方法,特征处理是为了让计算机知道怎么区分,通常连续数字不需要做处理,分类 /非连续内容需要做处理,或者说不可以比较大小的都需要处理,能比较大小的直接替换为数字就能用。
|
|
5
yagamil OP 谢谢大神回复
@princelai 这个倒经常用. 不过对于随机森林这种算信息商的, 不同类别只是一个符号作用, 并不涉及距离. 好像 onehot 没用的 ? |
|
6
princelai Jul 23, 2021
@yagamil #5 你可以看看西瓜书,我印象中以上来就讲的挑西瓜对西瓜分类。比如西瓜有很多性状,根蒂曲直,瓜皮花纹,瓜皮颜色,瓤颜色等等,瓤颜色有红色、青色、分红三种,这一个特征做完 onehot 就是 001,010,100,最终结果恰好是红色的就是熟瓜,那么这个特征熵最低,从这里分裂可以使结果误差最小,那么其他特征都可以不用,只用到瓜瓤颜色 onehot 后的三列特征即可 100%预测准确了。
|