
这是一个创建于 1204 天前的主题,其中的信息可能已经有所发展或是发生改变。
数据库用的是 mysql8.0 ,explain 如下
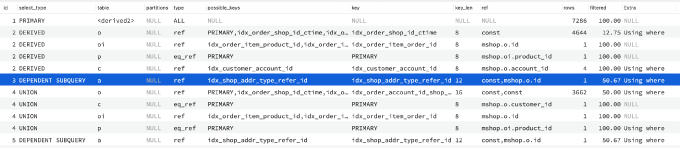
场景:带关键词分页查询某个店铺的订单,截图里 explain 的 SQL 是统计符合要求的订单总数,
表的关联关系如下:
订单表 o 会关联订单明细表 oi ,
订单明细表 oi 会关联商品表 p ,
订单表 o 会在非注册用户下单以及注册用户下单情况下,根据 account_id 是否有值关联到客户表 c 的不同字段,因为这个原因,不想写成 or 查询,这个会导致客户表 c 全表扫描,所以把 SQL 拆成了 union 的形式
订单表 o 会关联到收货地址表 a
从监控上看,这个 SQL 大概耗时在 600~700ms 左右,这个店铺的订单总数大概在 5k 左右,想问下有什么办法再优化这个 SQL 到 500ms 以下么?
感谢。
第 1 条附言 · 2022-07-05 16:51:11 +08:00
完整SQL如下:
explain
select count(distinct tmp.id)
from (
select o.id, o.created_date
from `order` o, order_item oi, product p, customer c
where o.deleted=false
and ((o.account_id>0 and o.account_id=c.account_id))
and o.shop_id=12345
and o.id=oi.order_id and oi.product_id=p.id
and
(
(
o.id like "%"'abc'"%"
or o.contact_information like "%"'abc'"%"
or c.last_name like "%"'abc'"%"
or c.email like "%"'abc'"%"
or p.title like "%"'abc'"%"
or exists (
select refer_id from address a where o.id=a.refer_id
and ( a.last_name like "%"'abc'"%"
or a.address like "%"'abc'"%")
)
)
)
union all
select o.id, o.modified_date
from `order` o, order_item oi, product p, customer c
where o.deleted=false
and o.account_id=0 and o.customer_id=c.id
and o.shop_id=12345
and o.id=oi.order_id and oi.product_id=p.id
and
(
(
o.id like "%"'abc'"%"
or o.contact_information like "%"'abc'"%"
or c.last_name like "%"'abc'"%"
or p.title like "%"'abc'"%"
or exists (
select refer_id from address a where o.id=a.refer_id
and ( a.last_name like "%"'abc'"%"
or a.address like "%"'abc'"%")
)
)
)
) tmp
 |
1
gy123 2022-07-05 16:02:21 +08:00
1.减少联表查询,拆出来放在应用里查询 merge 数据?
2.非实时性很高的类似地址用户信息,使用缓存?也同 1? |
 |
2
shanghai1943 OP @gy123 #1 忘了说了。关键词查询会查到地址信息,客户姓名,商品名称之类的,所以没法拆出来。
|
|
3
gy123 2022-07-05 16:18:02 +08:00
@shanghai1943 不能用关键词单独查询用户信息吗~看看是否联表过多导致的
|
 |
4
luman 2022-07-05 16:38:45 +08:00
完整 sql 贴下
|
|
5
shanghai1943 OP @sunjiayao #4 贴了。限于字数限制,做了一些精简。应该不影响 explain 的结果。
|
|
6
luman 2022-07-05 17:37:14 +08:00
看扫描行数不应该这么慢。你们硬件环境是什么?
|
|
7
shanghai1943 OP @sunjiayao #6 阿里云 1c2g
|
 |
8
sadfQED2 2022-07-05 18:35:26 +08:00 via Android
别瞎优化了,加钱吧😂1c2g 做线上业务的数据库,别难为自己了
|
|
9
shanghai1943 OP @sadfQED2 #8 主要是用户还不多,想省着点 😂
|
 |
10
mmdsun 2022-07-06 19:01:22 +08:00 via iPhone
好多 like 的模糊搜索,考虑用 MySQL 的全文索引或者 es?
|