
这是一个创建于 589 天前的主题,其中的信息可能已经有所发展或是发生改变。
最近借着 AIGC 的潮流, 用 Tauri 做了个基于 OpenAI 和 Azure OpenAI Service 的聊天机器人, 目前正式版已经放出, 欢迎大家去 https://hyperchat.yancey.app/ 下载和使用. 代码放在了 https://github.com/orgs/HyperChatBot, 欢迎一起建设和优化.
Functions
Hyper Chat 的跨平台基于 tauri, 老实说比起 electron, 虽然 tauri 无需安装笨重的 chromium, 但 webkit 本身缺失了太多的功能, 如 window.navigator.onLine, onCompositionStart 等等, 所以在实现上一些效果并不令人满意.‘
Hyper Chat 的初衷是绝不收集用户信息, 如 OpenAI Secret Key 和聊天记录. 因此我们使用 indexedDB 来存储数据. 在设置中, 我们支持导入和导出数据. 当然如果你有兴趣提供一个服务端, 前端代码也是很容易修改的, 你只需要将 src/hooks/useDB.ts 中的函数换成你的 API 接口即可.
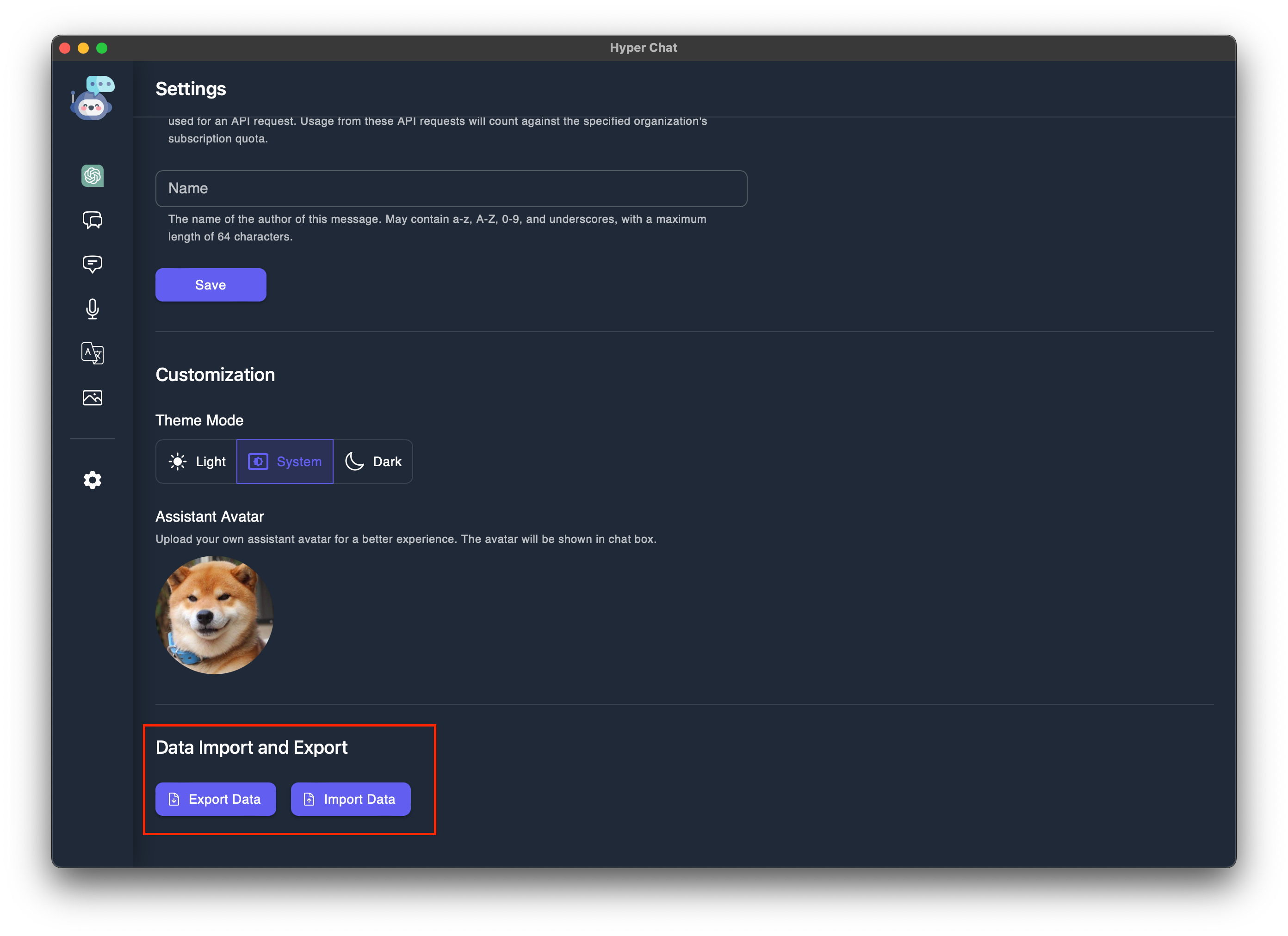
在大前端上, 主要使用了 React + Vite + TailwindCSS + Recoil 的组合. 这也是我第一次使用 TailwindCSS, 从抵触到真香, 往往只有一步之遥.
此外, 我们支持 OpenAI 和 Azure OpenAI Service 两种接口, 后续会考虑增加 Claude 2 和 Google Bard. 我们还支持亮色, 暗色, 以及跟随系统主题视觉效果. 为提高趣味性, 在聊天框中, 我们支持修改助理的头像.
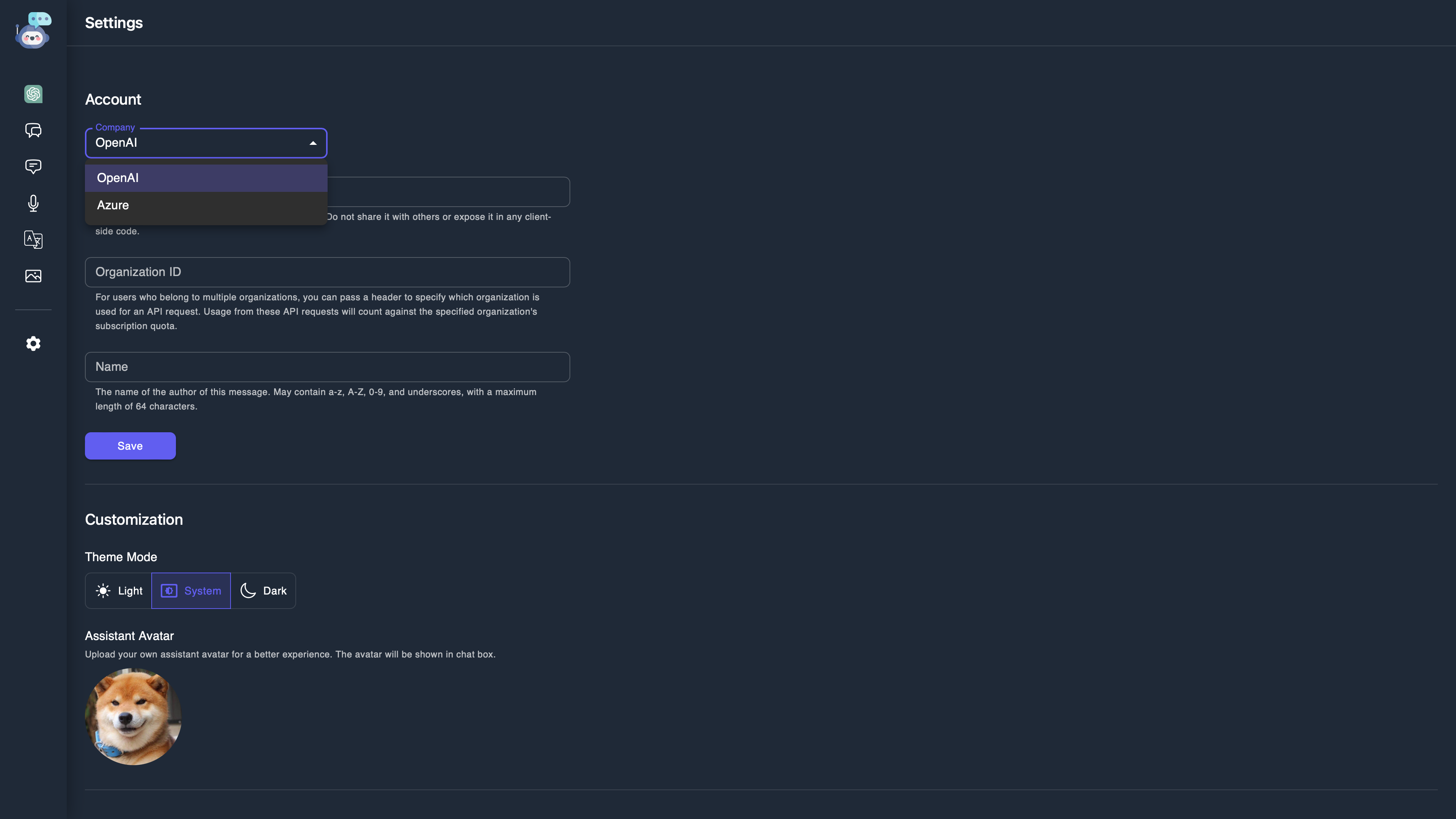
Customizable ChatBox
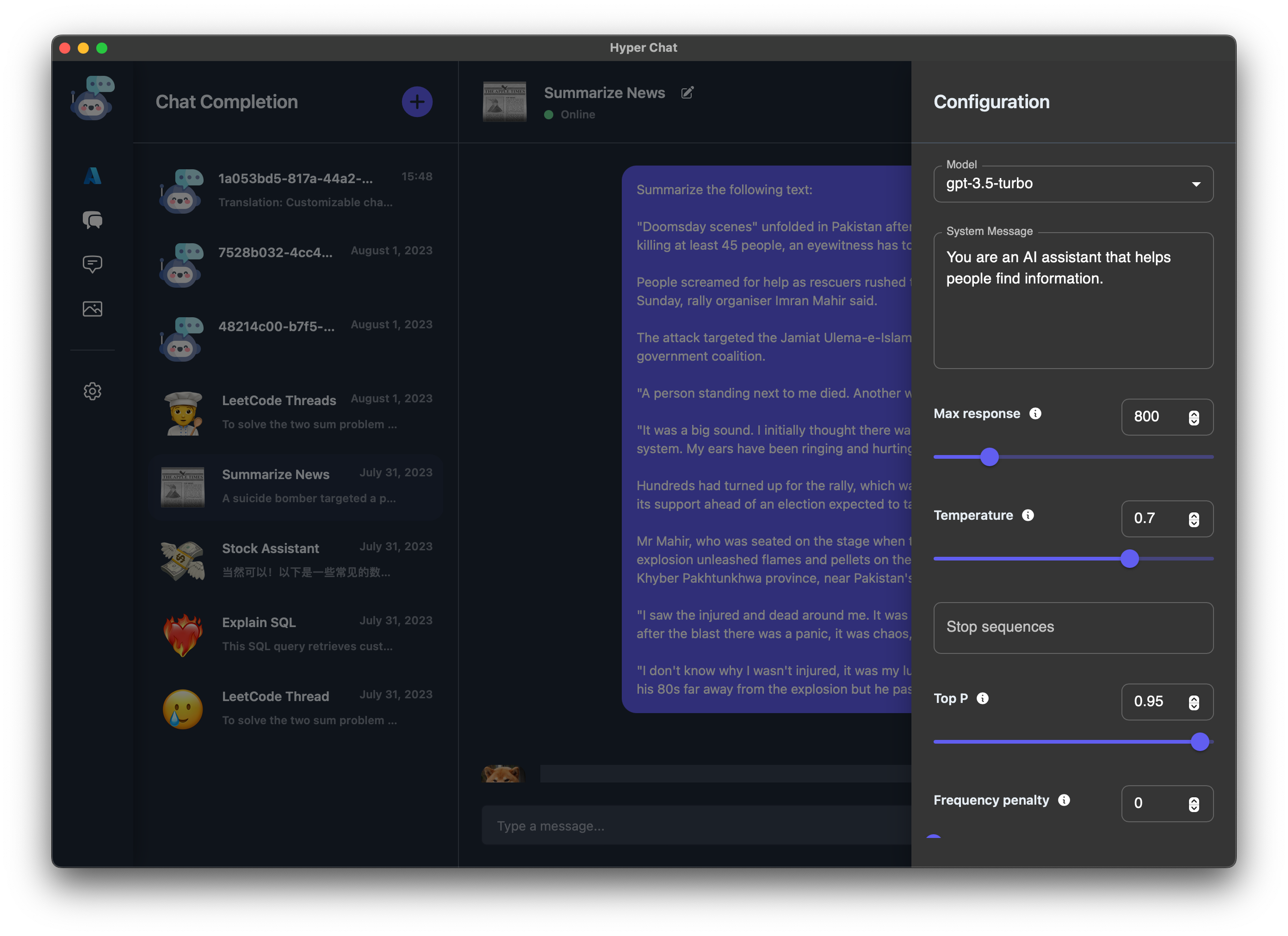
在聊天框区域, 对于每种模型 API, 我们都有和官方一致的配置参数可供用户选择.
此外是一些零零散散的小功能, 如支持修改会话的头像和标题, 删除会话, 添加会话等.
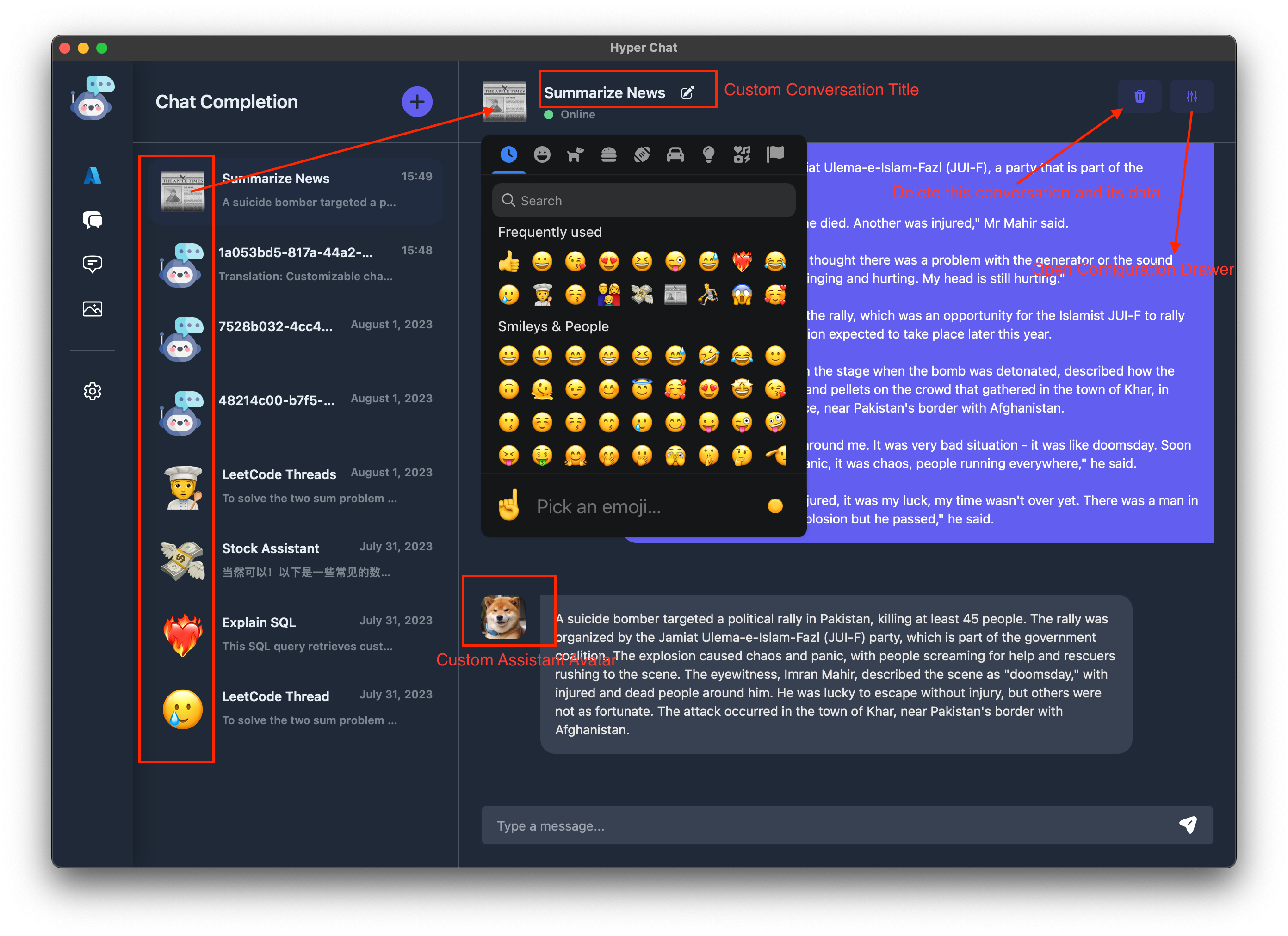
Chat Completion
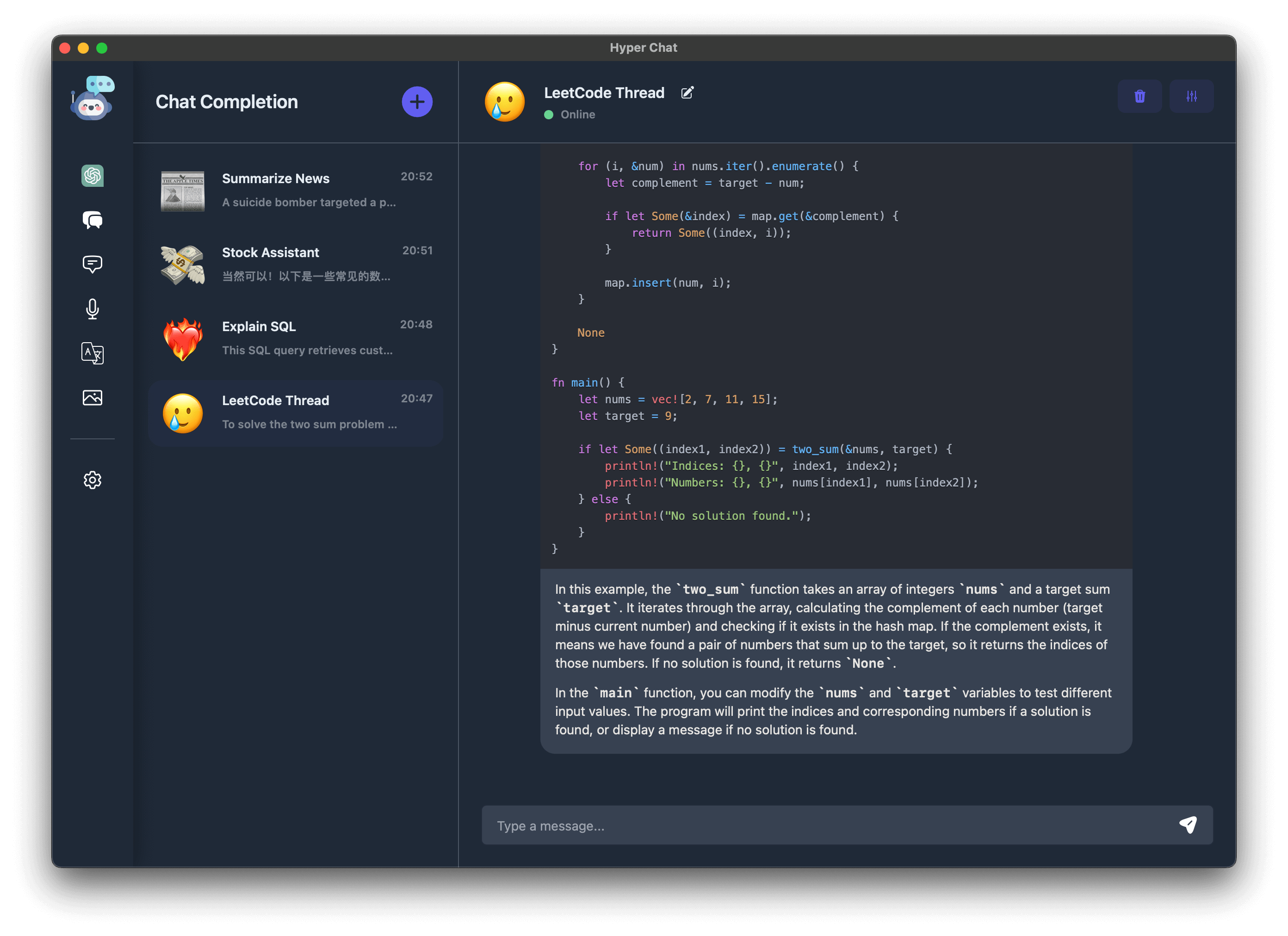
Hyper Chat 最核心的功能是支持 Chat Completion, 整个 APP 最花心思的便是这个模块. 和 ChatGPT 网页效果一样, 我们默认支持 stream 模式. 此外, 我们采用贪心策略, 每次回话中尽可能多的带上下文:
// 获取用户 prompt 的 token 数
const userMessageTokensCount = getTokensCount(prompt, model);
// 总的 token 数等于用户 prompt 的 token 数 + 系统消息的 token 数 + 本次希望 Assistant 返回的最大 token 数
let tokensCount = userMessageTokensCount + systemMessageTokensCount + maxTokens;
// 获取当前模型最大支持的 token 数, 如 GPT-3.5-turbo 最多支持 4097 个 token
const tokensLimit = models.find((m) => m.name === model)?.tokensLimit || 0;
// 如果用户输入的 prompt 的 token 数已经超过阈值, 就提示错误
if (tokensCount > tokensLimit) {
toast.error(
`This model's maximum context length is ${tokensLimit} tokens. However, you requested ${tokensCount} tokens (${
tokensCount - maxTokens
} in the messages, ${maxTokens} in the completion). Please reduce the length of the prompt.`
);
return;
}
// 从新到旧依次遍历过往的 message, 尽可能的多的将上下文交给模型处理
const context: CreateChatCompletionRequest["messages"] = [];
currConversation.messages
.slice()
.reverse()
.forEach(({ tokensCount: historyTokensCount, content, role }) => {
tokensCount += historyTokensCount;
if (tokensCount > tokensLimit) return;
context.unshift({
role,
content,
});
});
Text Completion
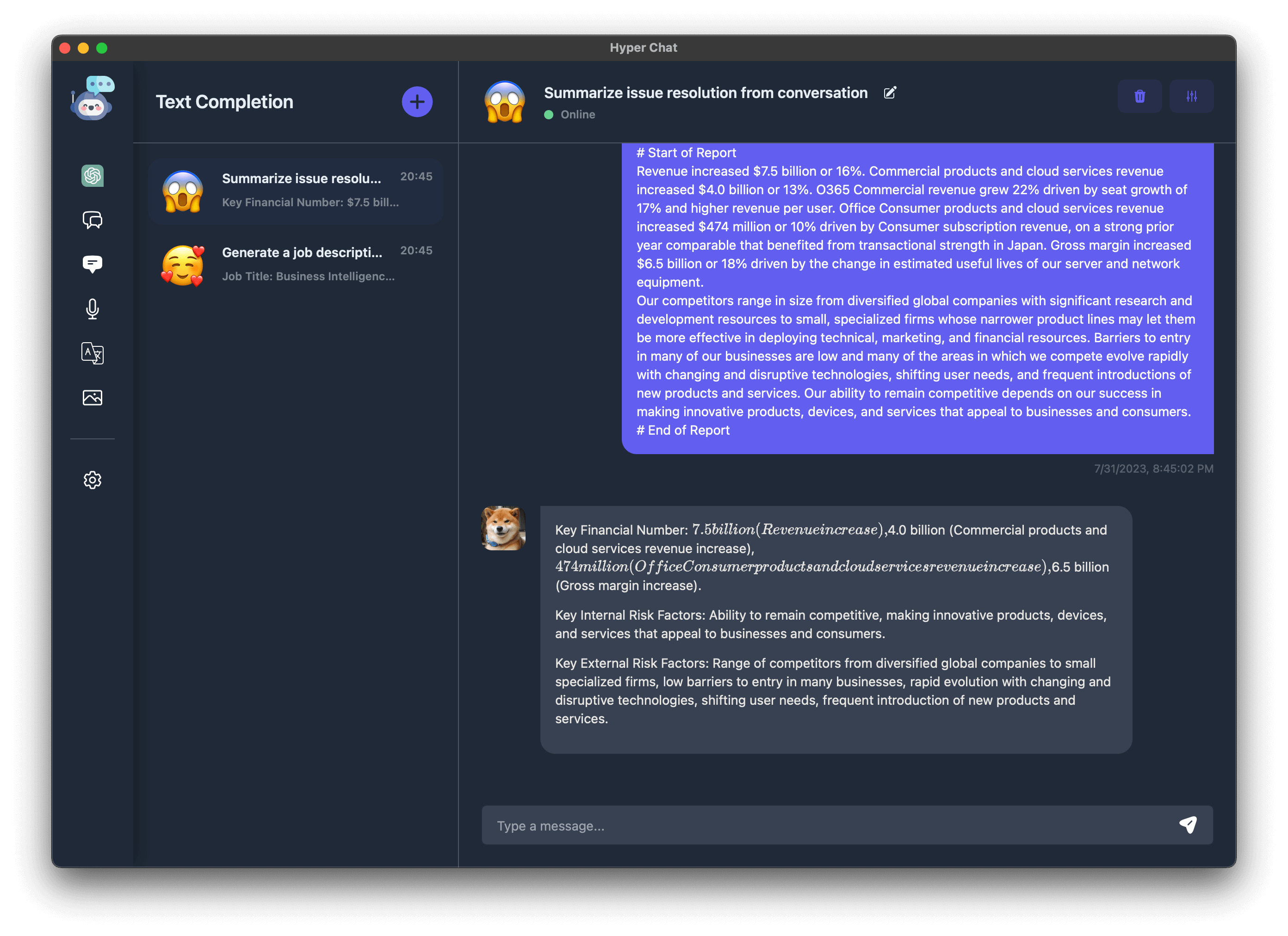
我们也支持 Text Completion, 不过 OpenAI 最新官方文档表示这个 API 属于 legacy, 可能后面就废弃了, 且用且珍惜.
Audio Transparent and Translation
虽然 OpenAI 早已开源了 Whisper-1, 但我们还是接入了它的接口, 我们支持音频的转录和翻译. 在右下角先选择音频文件, 再敲击回车即可提交, 你也可以输入 prompt, 不过在 Audio 中, 它是可选的.
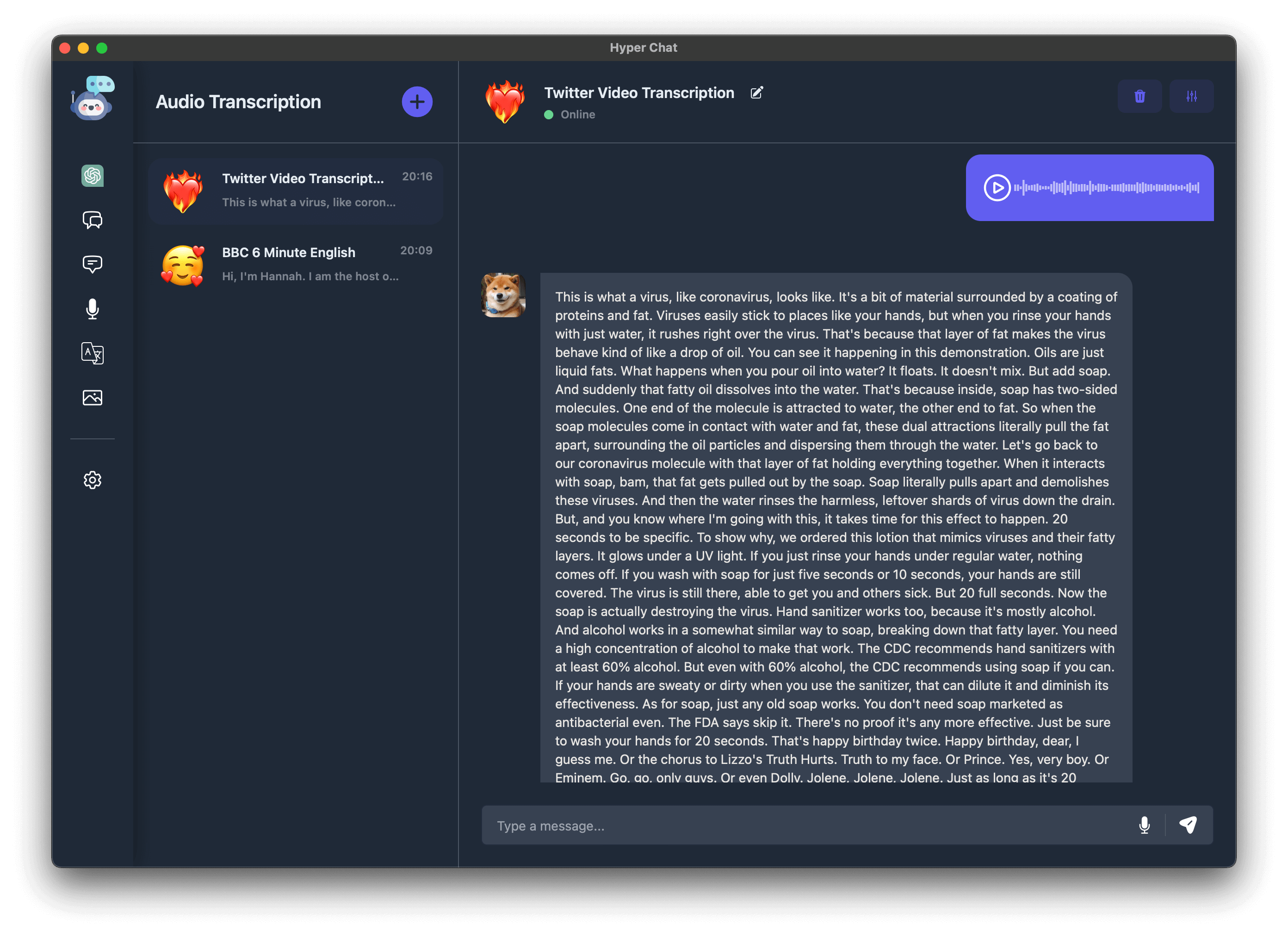
Image Generation
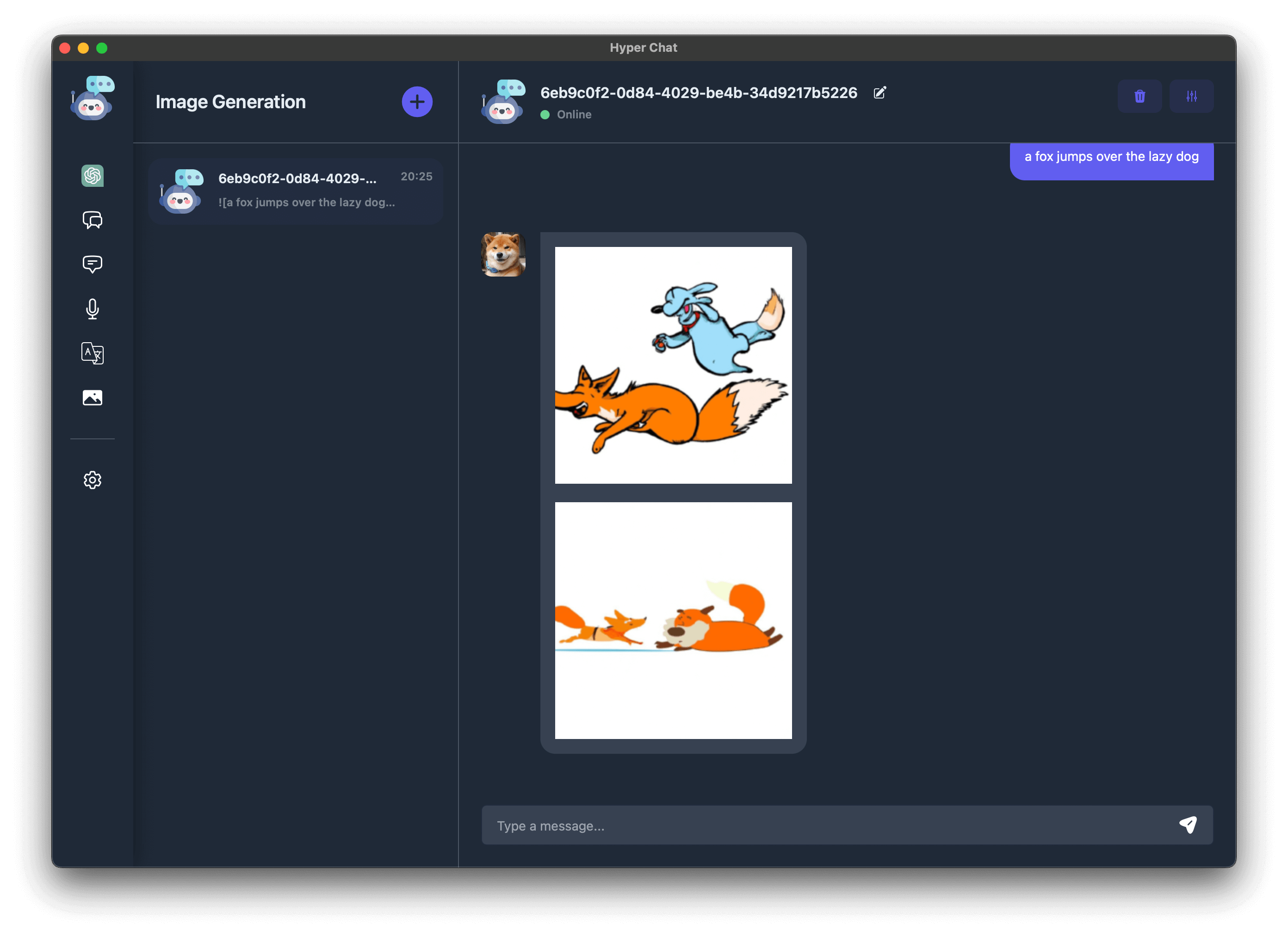
我们支持基于 DALL-E 的图片生成接口, 建议在配置中选择更小尺寸的图片, 这样生成起来会比较快. 此外, 图片有过期时间(约为 1 天), 请及时将生成的图片下载到本地.
最后
欢迎大家体验和使用, 有任何建议都可以通过 Official Discussion 一起讨论.
1 条回复
 |
1
horizon 2023-08-03 18:54:19 +08:00
完成度不错。
不过我还是用 poe 吧,哈哈 |