
https://zhuanlan.zhihu.com/p/627566068
看了这篇文章,对 DDR 有两个疑问。求各位大佬不吝赐教。
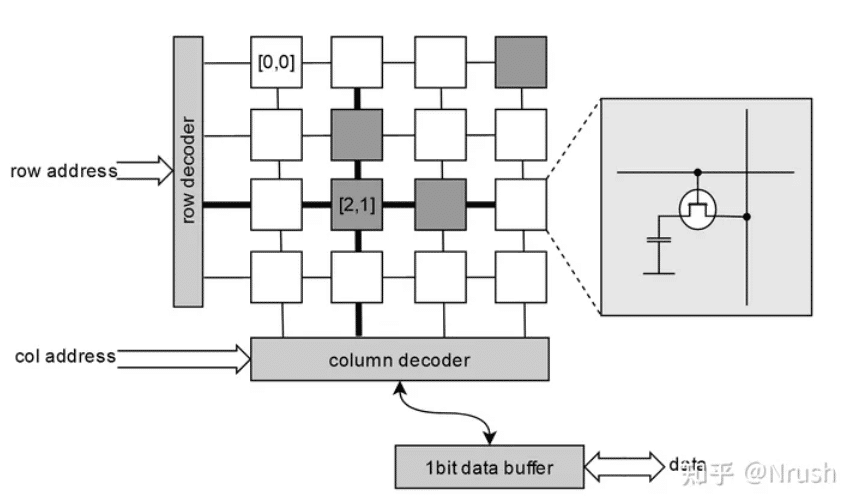 首先为什么说“column line 上的功能要远比 row line 上的器件复杂”,就因为 column 线连接着 data buffer 吗?还是说有着其他理由?
首先为什么说“column line 上的功能要远比 row line 上的器件复杂”,就因为 column 线连接着 data buffer 吗?还是说有着其他理由?
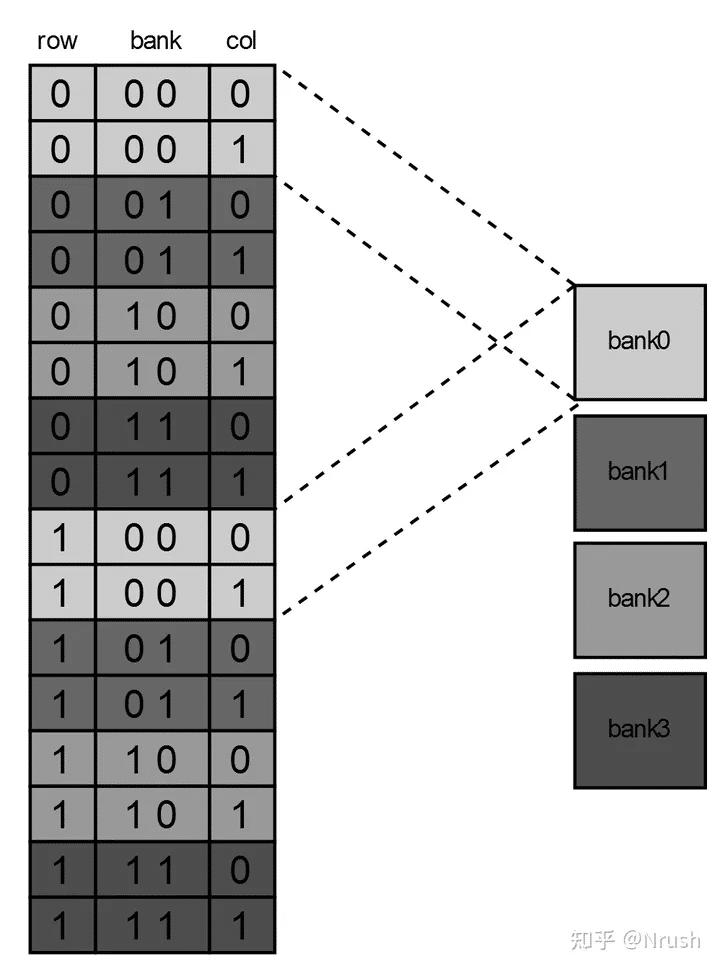
原文提到:多 bank 情况下,交叉读写不同 bank ,可以有效提高读写带宽。一个 bank 完成对一行的数据读写后,如果需要再次读取同一 bank 的另外一行上的数据,那必须耗费较长的时间重新打开一行,如果只有一个 bank ,那此时总线必须处于等待状态。这就叫做“交织”。
上面这一段话我理解它的意思,但是为什么上面这个图是这么画的? 但我觉得应该这样画吧:
- 0 0 0 0 [ bank0 ]
- 0 0 0 1 [ bank1 ]
- 0 0 1 0 [ bank2 ]
- 0 0 1 1 [ bank3 ]
- 以此类推...
这样我在对 地址 [ 0 0 0 0 ] 请求还没结束的时候,就可以去请求 [ 0 0 0 1 ] 地址了。或者说,这样的地址排布才是最“交织”的呀。( PS:原文说:该编码保证对同一 bank 的连续地址访问都是在同一行上的,我好像没有理解到 这个好处)





