
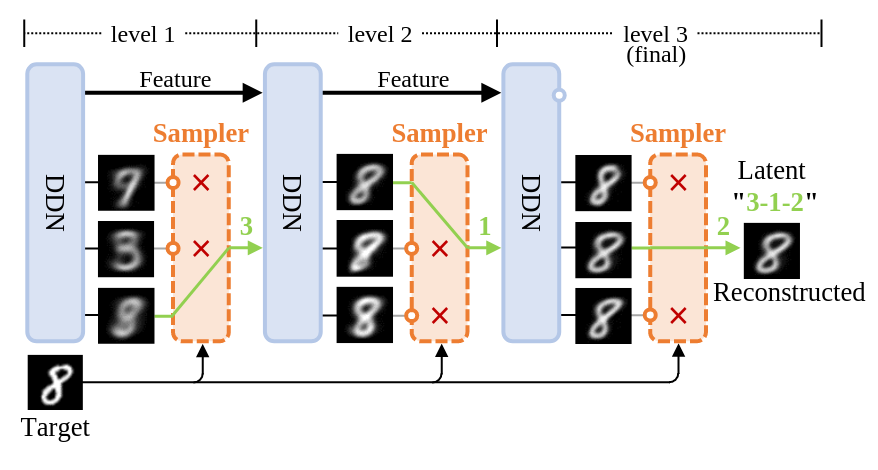
我在之前 ICLR 2025 的论文中提出了一种全新的生成模型——「离散分布网络」(Discrete Distribution Networks)
前两天在 Hacker News 上宣传,反响热烈,竟然来到了日榜第二名,给项目的网页带来了近 1.5 万的访问量。
所以,现在想在 V2EX 也宣传交流一下~
一句话介绍:「离散分布网络」是一个原理简单、性质独特的全新生成模型,有着非常多有趣的性质。期待 DDN 能给更多人带来灵感~
PS. GitHub 五万关注者的算法大 V lucidrains 也复现了 DDN 算法: https://github.com/lucidrains/discrete-distribution-network
详情:
英文介绍: https://x.com/diyerxx/status/1978531040068321766 ( twitter 冷启动实在太难啦,求互动一下鼓励鼓励🥺)
中文介绍: https://zhuanlan.zhihu.com/p/1935903948990047972
项目网页: https://discrete-distribution-networks.github.io/
GitHub: https://github.com/DIYer22/discrete_distribution_networks
































