
这是一个创建于 4101 天前的主题,其中的信息可能已经有所发展或是发生改变。
引子:我接触过很多编程语言,接触过各种各样的服务器端开发,Java,Go,Ruby,Javascript等语言,Spring,Node.js,Rails等等常见服务器端框架和编程模型都有接触。这里谈一下我个人对高性能服务器端程序的一些看法,希望给各位读者一些认识。这片文章提到的内容也是 Coding(https://coding.net) 代码托管乃至整站都在使用的一些概念和技术。
此外,阅读这篇文章,有如下几个前提:不谈硬件,不评论编程语言以及框架的好坏,不谈高级算法,可拍砖,拒绝喷子
三个关键词
Cache,Asynchronous,Concurrent
我们一个一个来讲。
#Cache#
Cache 翻译成中文就是缓存,台湾的叫法叫做快取,其本质是将获取缓慢或者计算缓慢的数据结果暂时存储起来,以便以后再次获取或者计算同样的数据可以直接从存储中取得结果,从而可能提升性能的一种手段。Cache 最早是应用在计算机的 CPU 中,这篇文章不谈硬件,所以有需要了解 CPU 的缓存的同学可自行搜索。
可以想象,如果让一个人一遍一遍的从 1+2+3+4+…+99+100=? 这样去算,他加到最后发现等于5050,而这个过程耗费了他大量的时间,耗费了大量的脑力,在此期间,他可能把所有精力都放在这个计算上面而无暇顾及其他事情。等到他累得满头大汗,加完了结果,他告诉你是 5050。没过多久,你又让他做同样的事情,我相信这家伙会不加思索的再次告诉你 5050。为什么?你会笑我说,人又不是傻子,这为同学肯定记得这个结果是5050啊。
可是,计算机不一样,计算机就是你上面要嘲笑的那个傻子,他傻到,完全不会记得刚在做了什么事情,他会傻乎乎的再重新算一遍告诉你结果。没错如果你问他一万遍,这头没有脑子的机器会算一万遍的。虽然上面这个从1加到100这个例子对于一款现代化的计算机来讲简直是小菜一碟,但是计算机往往面临的计算难题是我们人类所无法企及的。
Cache 就是为了来解决这个事情的,因为事情往往是这样的:你会发现一些非常复杂的过程的计算结果是可重用的,而且把这个结果暂时存储在某些地方,查找起来也是极为方便的。
所以,现在你理解了缓存,那可以来思考一些缓存的设计策略了。这里做一点说明,不同的缓存策略跟具体的业务系统关系非常大,制定缓存策略需要根据具体的情况来分析。常用的策略:
最终结果型缓存。这种缓存往往提升性能效果最为明显,但是命中率却低,也就是可重用性不高。
中间结果型缓存。还拿上面的例子来说,1加到100,你可以构建出是个缓存分别是1加到10,10加到20,20加到30 … 一直到 90加到100 这9个缓存。好处是你如果被请求到 1加到60 的时候,仍然可以使用这些缓存结果。可坏处也很明显,你取到几个缓存的结果后不得不再进行一次运算。所以实际情况,往往是在最终结果和中间结果之间找到平衡点,或者是两者配合使用。
不知不觉中,你有没有发现,1+2+3+4+…+99+100=5050 是个永远都成立的事实,这也就意味着,它永远不用被清除。可事实是往往是,缓存是有有效期的,例如需要缓存今天的天气情况,今天是 2014年11月16日,到了明天就是 11月17日,天气就不一样了。再例如需要缓存 Coding 的最新冒泡列表,当有人发布了新的冒泡,那么这个列表就得被更新。从这个角度来看,缓存的策略又有如下常见的几种:
1.永久式缓存:结果在任何情况下都不发生改变,无需清除或者更新
2.有有效期的缓存:在特定时间点或者时间段后失效
3.触发式失效缓存:当某一事件产生时,缓存失效,当然有有效期式缓存也可以理解成时间点和时间段到期为触发条件的触发式失效缓存
嗯,既然提到了缓存的更新或者清除,那么就牵扯到缓存的更新策略。例子永远好过大段的理论:假如我们要缓存 Coding 的冒泡列表。有这么一种策略:当用户请求时我们检查下是否已存在这样的缓存,如果有直接返回缓存数据,否则我们生成这个列表(计算机的计算过程),返回给用户并且把冒泡列表(计算结果)存储起来,以便以后的用户访问时直接获取。当用户发布了一个新的冒泡的时候,我们清除这个缓存,再有用户请求时将重复以上过程。这是其中一种完整的缓存清除策略。另外一种是,每当我们收到一个用户发布的冒泡时,都重新构建这个缓存,用户每次查看冒泡列表都是取的缓存数据。这两种缓存分别称之为:
1.被动式缓存:需要用到时才构建
2.主动式缓存:预先构建
关于 Cache 还有很多很多需要注意和设计上的思路和策略,这里不再一一赘述。这些缓存在不同的维度有不同的策略,我们需要根据具体的业务情况来选择合适的策略。Coding 的很多业务中使用了上述很多种策略,例如我们常见的分支列表和标签列表就是使用触发式失效缓存,我们的广场项目列表就是使用主动式缓存构建。
#Asynchronous#
Asynchronous 的意思是异步。什么是异步呢?就是不在第一时间告知调用者结果,告诉他我已经收到这个任务了,我会处理,处理完毕后通知你结果,如果你不是等不到结果就无法进行下去的话,你完全可以先干别的事情。
嗯,好像我描述的比较拉杂。还是例子:你去咖啡厅点一杯咖啡,服务员告诉你现磨咖啡需要15分钟才可做好,那么在咖啡做好之前,你不可能盯着服务员或者咖啡师15分钟,你肯定会干点别的,比如说玩手机上一下网,或者跟你女朋友商量下去看电影什么的,总之你不会傻乎乎等着的。等到咖啡做好了,服务员会记得给你端过来的。这就是异步过程,你的大脑不必为一个漫长的过程卡住,可以继续其他的事情。
服务端程序设计往往也是这样,在你等待一个很缓慢的过程的时候,如果你不是必须要得到这个过程的结果才能继续下去,你完全可以先进行别的过程,等到那个缓慢的过程执行完毕后,它会通知你结果的。
异步已经在现在的各种编程领域有了很广泛的应用,例如 Ajax 技术,就是一种异步的手段,在浏览器和服务器交互的时候,完全不影响你在网页上的其他操作。
异步在各种编程语言和框架中都有相应的支持,这里简单介绍一下 Javascript 的异步支持。熟悉它的人的人请无视这段。它使用回调的方式支持异步,大致意思是,A 交代给 B 一个任务,并且告知 B 任务完成后继续执行哪段程序(往往包装成一个匿名function),B执行完任务后,执行这个匿名的 function,这样来完成异步过程。在 Javascript 中大量的使用这种回调的异步方案,已经不再局限于对一个缓慢的过程了,可以对几乎所有的过程都采用异步处理。
在服务端程序中,除了使用线程,协程,回调之外,另外一种常见的异步的支持方式就是消息队列。其原理是,生产者发送消息到消息队列中,消费者从中取出消息,做出相应处理,并把结果存储起来或者通过某种方式告知生产者。
异步在很多时候可以运用现代化计算机 CPU 的多核特性和分布式计算特性,能显著的提升应用的性能,但是一个前提就是,异步的任务的结果必须是主进程进行下一步操作所不依赖的,否则主进程必须等待,直到这个任务执行结束,拿到结果再进行下一步,这时就变成了传统的同步计算了。
异步操作在 Coding 中也有非常广泛的应用。例如当用户执行完一次 Push,Coding 需要生成一条 Push 的动态,需要清理掉相应的缓存,需要触发相关的 WebHook 等等,这些操作都是通过消息队列来异步完成的。因为这些操作非常的耗时,而且完全不需要即时完成,所以用户在 Push 的时候等待着这些操作完成是很不合理的。异步操作在这里即展示出了其应用多核和多台服务器的优势,在某种程度上还能提升用户体验。
Golang 是 Google 2009 年发布的一门现代化语言,其语言特性对异步提供了良好的支持。这里举个例子体现一下异步的魅力:

这一段程序涉及到了 Golang 的 goroutine 和 channel,不了解的可以去查一下相关资料。
这段程序实现了在还为准备好参数时就已经调用一个 function 。当我们调用 addProject 的时候还不知道项目的名字,但是这完全不影响我们去检查用户权限。程序完全可以一边去检查权限,一边去获取项目名字,当程序执行到不得不拿到项目的名字才能继续的时候,它将阻塞,直到我们告诉他项目名字。
#Concurrent#
Concurrent 的意思是并行。现代化的 CPU 往往具有多个核心,而且有些 CPU 也具有超线程能力。如果我们可以将单个过程拆分成小的任务,交给 CPU 的多个核心,或者是分布式计算系统的多个计算节点,就可以充分利用并行计算来提升性能。前提是这些任务相互之间不要有相互依赖的关系。依然是例子:需要计算网站上某一批用户的活跃度积分,传统的,我们会查出这一批用户,然后写一个循环,然后轮流计算他们的积分,最后得到结果。其实每个用户的积分的计算都是独立的,相互不依赖,那么我们就可以利用这一点来并行化这个计算。
下面给出一段 Coding 代码托管中的程序,这段程序是指定条件获取一个提交列表,使用了并行计算的一种 并发循环:
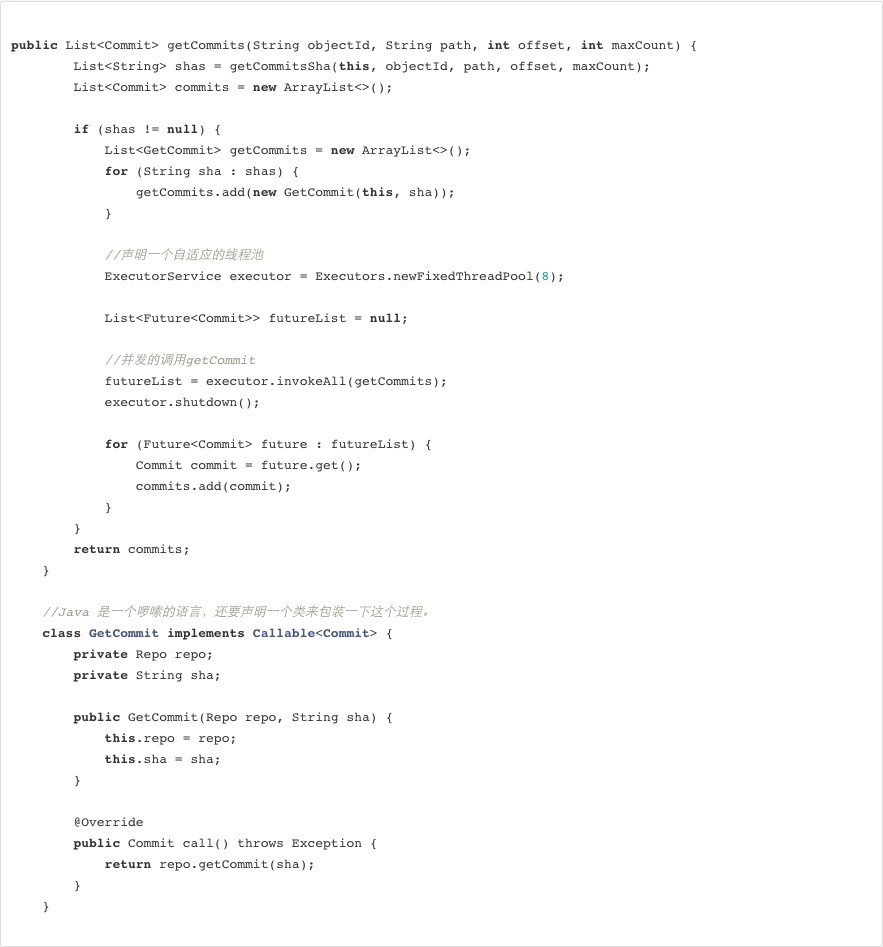
这段程序是一个并发循环的例子,例子中需要根据一些参数查询到 Commit 的列表,而 repo.getCommit 这个过程完全不需要一个一个轮流查询,因为他们是完全独立的,所以可以使用 Java 的 Cocurrent 包来做并发循环,充分利用多核来尽快得到执行结果。
#总结#
关于高性能服务器程序需要关注的点还有很多,这里只是简单的介绍了下三个利器(Cache,Asynchronous,Concurrent)。而即便是这三个利器,我的介绍也只是冰山一角,但是请相信你看懂了我介绍的这些东西,重新去思考服务端编程会获得不少收获的。
这三者也是相辅相成的关系,很多时候都是配合着使用才能起到很好的效果。异步和并行在某种程度上是有重叠的,而我们经常使用异步的方式去主动构建缓存。
最后再给一些小提示:
1.不要让 CPU 闲着(CPU 正常情况下压力大的时候自然不会闲着,这里指的是CPU负载低谷时,可以让他主动的构建缓存,或者做一些准备工作等等。)
2.提升 CPU 效率,即不要总让 CPU 做重复的劳动,用空间换时间的理念去减轻 CPU 的压力
3.不要让无关紧要的附属的任务卡住主进程,让他们在后台慢慢做
4.可以提前做好准备工作,这个比较抽象,但是举例子就很明白,连接池,主动缓存,以及我举得那个 Golang 的例子都是很好的例子
(完)
本文转载自 Coding 官方技术博文,http://blog.coding.net/,作者:王振威
Coding 官方技术博文是 Coding 小团队在日程工作学习中对于技术、产品、设计等等方面的积累和分享。希望大家共同学习共同进步。如转载请注明出处与作者。
此外,阅读这篇文章,有如下几个前提:不谈硬件,不评论编程语言以及框架的好坏,不谈高级算法,可拍砖,拒绝喷子
三个关键词
Cache,Asynchronous,Concurrent
我们一个一个来讲。
#Cache#
Cache 翻译成中文就是缓存,台湾的叫法叫做快取,其本质是将获取缓慢或者计算缓慢的数据结果暂时存储起来,以便以后再次获取或者计算同样的数据可以直接从存储中取得结果,从而可能提升性能的一种手段。Cache 最早是应用在计算机的 CPU 中,这篇文章不谈硬件,所以有需要了解 CPU 的缓存的同学可自行搜索。
可以想象,如果让一个人一遍一遍的从 1+2+3+4+…+99+100=? 这样去算,他加到最后发现等于5050,而这个过程耗费了他大量的时间,耗费了大量的脑力,在此期间,他可能把所有精力都放在这个计算上面而无暇顾及其他事情。等到他累得满头大汗,加完了结果,他告诉你是 5050。没过多久,你又让他做同样的事情,我相信这家伙会不加思索的再次告诉你 5050。为什么?你会笑我说,人又不是傻子,这为同学肯定记得这个结果是5050啊。
可是,计算机不一样,计算机就是你上面要嘲笑的那个傻子,他傻到,完全不会记得刚在做了什么事情,他会傻乎乎的再重新算一遍告诉你结果。没错如果你问他一万遍,这头没有脑子的机器会算一万遍的。虽然上面这个从1加到100这个例子对于一款现代化的计算机来讲简直是小菜一碟,但是计算机往往面临的计算难题是我们人类所无法企及的。
Cache 就是为了来解决这个事情的,因为事情往往是这样的:你会发现一些非常复杂的过程的计算结果是可重用的,而且把这个结果暂时存储在某些地方,查找起来也是极为方便的。
所以,现在你理解了缓存,那可以来思考一些缓存的设计策略了。这里做一点说明,不同的缓存策略跟具体的业务系统关系非常大,制定缓存策略需要根据具体的情况来分析。常用的策略:
最终结果型缓存。这种缓存往往提升性能效果最为明显,但是命中率却低,也就是可重用性不高。
中间结果型缓存。还拿上面的例子来说,1加到100,你可以构建出是个缓存分别是1加到10,10加到20,20加到30 … 一直到 90加到100 这9个缓存。好处是你如果被请求到 1加到60 的时候,仍然可以使用这些缓存结果。可坏处也很明显,你取到几个缓存的结果后不得不再进行一次运算。所以实际情况,往往是在最终结果和中间结果之间找到平衡点,或者是两者配合使用。
不知不觉中,你有没有发现,1+2+3+4+…+99+100=5050 是个永远都成立的事实,这也就意味着,它永远不用被清除。可事实是往往是,缓存是有有效期的,例如需要缓存今天的天气情况,今天是 2014年11月16日,到了明天就是 11月17日,天气就不一样了。再例如需要缓存 Coding 的最新冒泡列表,当有人发布了新的冒泡,那么这个列表就得被更新。从这个角度来看,缓存的策略又有如下常见的几种:
1.永久式缓存:结果在任何情况下都不发生改变,无需清除或者更新
2.有有效期的缓存:在特定时间点或者时间段后失效
3.触发式失效缓存:当某一事件产生时,缓存失效,当然有有效期式缓存也可以理解成时间点和时间段到期为触发条件的触发式失效缓存
嗯,既然提到了缓存的更新或者清除,那么就牵扯到缓存的更新策略。例子永远好过大段的理论:假如我们要缓存 Coding 的冒泡列表。有这么一种策略:当用户请求时我们检查下是否已存在这样的缓存,如果有直接返回缓存数据,否则我们生成这个列表(计算机的计算过程),返回给用户并且把冒泡列表(计算结果)存储起来,以便以后的用户访问时直接获取。当用户发布了一个新的冒泡的时候,我们清除这个缓存,再有用户请求时将重复以上过程。这是其中一种完整的缓存清除策略。另外一种是,每当我们收到一个用户发布的冒泡时,都重新构建这个缓存,用户每次查看冒泡列表都是取的缓存数据。这两种缓存分别称之为:
1.被动式缓存:需要用到时才构建
2.主动式缓存:预先构建
关于 Cache 还有很多很多需要注意和设计上的思路和策略,这里不再一一赘述。这些缓存在不同的维度有不同的策略,我们需要根据具体的业务情况来选择合适的策略。Coding 的很多业务中使用了上述很多种策略,例如我们常见的分支列表和标签列表就是使用触发式失效缓存,我们的广场项目列表就是使用主动式缓存构建。
#Asynchronous#
Asynchronous 的意思是异步。什么是异步呢?就是不在第一时间告知调用者结果,告诉他我已经收到这个任务了,我会处理,处理完毕后通知你结果,如果你不是等不到结果就无法进行下去的话,你完全可以先干别的事情。
嗯,好像我描述的比较拉杂。还是例子:你去咖啡厅点一杯咖啡,服务员告诉你现磨咖啡需要15分钟才可做好,那么在咖啡做好之前,你不可能盯着服务员或者咖啡师15分钟,你肯定会干点别的,比如说玩手机上一下网,或者跟你女朋友商量下去看电影什么的,总之你不会傻乎乎等着的。等到咖啡做好了,服务员会记得给你端过来的。这就是异步过程,你的大脑不必为一个漫长的过程卡住,可以继续其他的事情。
服务端程序设计往往也是这样,在你等待一个很缓慢的过程的时候,如果你不是必须要得到这个过程的结果才能继续下去,你完全可以先进行别的过程,等到那个缓慢的过程执行完毕后,它会通知你结果的。
异步已经在现在的各种编程领域有了很广泛的应用,例如 Ajax 技术,就是一种异步的手段,在浏览器和服务器交互的时候,完全不影响你在网页上的其他操作。
异步在各种编程语言和框架中都有相应的支持,这里简单介绍一下 Javascript 的异步支持。熟悉它的人的人请无视这段。它使用回调的方式支持异步,大致意思是,A 交代给 B 一个任务,并且告知 B 任务完成后继续执行哪段程序(往往包装成一个匿名function),B执行完任务后,执行这个匿名的 function,这样来完成异步过程。在 Javascript 中大量的使用这种回调的异步方案,已经不再局限于对一个缓慢的过程了,可以对几乎所有的过程都采用异步处理。
在服务端程序中,除了使用线程,协程,回调之外,另外一种常见的异步的支持方式就是消息队列。其原理是,生产者发送消息到消息队列中,消费者从中取出消息,做出相应处理,并把结果存储起来或者通过某种方式告知生产者。
异步在很多时候可以运用现代化计算机 CPU 的多核特性和分布式计算特性,能显著的提升应用的性能,但是一个前提就是,异步的任务的结果必须是主进程进行下一步操作所不依赖的,否则主进程必须等待,直到这个任务执行结束,拿到结果再进行下一步,这时就变成了传统的同步计算了。
异步操作在 Coding 中也有非常广泛的应用。例如当用户执行完一次 Push,Coding 需要生成一条 Push 的动态,需要清理掉相应的缓存,需要触发相关的 WebHook 等等,这些操作都是通过消息队列来异步完成的。因为这些操作非常的耗时,而且完全不需要即时完成,所以用户在 Push 的时候等待着这些操作完成是很不合理的。异步操作在这里即展示出了其应用多核和多台服务器的优势,在某种程度上还能提升用户体验。
Golang 是 Google 2009 年发布的一门现代化语言,其语言特性对异步提供了良好的支持。这里举个例子体现一下异步的魅力:

这一段程序涉及到了 Golang 的 goroutine 和 channel,不了解的可以去查一下相关资料。
这段程序实现了在还为准备好参数时就已经调用一个 function 。当我们调用 addProject 的时候还不知道项目的名字,但是这完全不影响我们去检查用户权限。程序完全可以一边去检查权限,一边去获取项目名字,当程序执行到不得不拿到项目的名字才能继续的时候,它将阻塞,直到我们告诉他项目名字。
#Concurrent#
Concurrent 的意思是并行。现代化的 CPU 往往具有多个核心,而且有些 CPU 也具有超线程能力。如果我们可以将单个过程拆分成小的任务,交给 CPU 的多个核心,或者是分布式计算系统的多个计算节点,就可以充分利用并行计算来提升性能。前提是这些任务相互之间不要有相互依赖的关系。依然是例子:需要计算网站上某一批用户的活跃度积分,传统的,我们会查出这一批用户,然后写一个循环,然后轮流计算他们的积分,最后得到结果。其实每个用户的积分的计算都是独立的,相互不依赖,那么我们就可以利用这一点来并行化这个计算。
下面给出一段 Coding 代码托管中的程序,这段程序是指定条件获取一个提交列表,使用了并行计算的一种 并发循环:

这段程序是一个并发循环的例子,例子中需要根据一些参数查询到 Commit 的列表,而 repo.getCommit 这个过程完全不需要一个一个轮流查询,因为他们是完全独立的,所以可以使用 Java 的 Cocurrent 包来做并发循环,充分利用多核来尽快得到执行结果。
#总结#
关于高性能服务器程序需要关注的点还有很多,这里只是简单的介绍了下三个利器(Cache,Asynchronous,Concurrent)。而即便是这三个利器,我的介绍也只是冰山一角,但是请相信你看懂了我介绍的这些东西,重新去思考服务端编程会获得不少收获的。
这三者也是相辅相成的关系,很多时候都是配合着使用才能起到很好的效果。异步和并行在某种程度上是有重叠的,而我们经常使用异步的方式去主动构建缓存。
最后再给一些小提示:
1.不要让 CPU 闲着(CPU 正常情况下压力大的时候自然不会闲着,这里指的是CPU负载低谷时,可以让他主动的构建缓存,或者做一些准备工作等等。)
2.提升 CPU 效率,即不要总让 CPU 做重复的劳动,用空间换时间的理念去减轻 CPU 的压力
3.不要让无关紧要的附属的任务卡住主进程,让他们在后台慢慢做
4.可以提前做好准备工作,这个比较抽象,但是举例子就很明白,连接池,主动缓存,以及我举得那个 Golang 的例子都是很好的例子
(完)
本文转载自 Coding 官方技术博文,http://blog.coding.net/,作者:王振威
Coding 官方技术博文是 Coding 小团队在日程工作学习中对于技术、产品、设计等等方面的积累和分享。希望大家共同学习共同进步。如转载请注明出处与作者。
 |
1
wiviam 2014 年 11 月 19 日
不错,学习了~
|
 |
2
caixiexin 2014 年 11 月 19 日
最近工作上刚好也涉及到这块。。
请问数据库方面的应对策略一般是啥? |
 |
3
pyKun 2014 年 11 月 20 日
这三点就是起步...
|
 |
4
66450146 2014 年 11 月 20 日
翻到最后居然没有招聘……
|
 |
5
canesten 2014 年 11 月 20 日 Concurrent是并发
Parallel才是并行 没有吐槽下去的动力了 |
 |
6
yakczh 2014 年 11 月 20 日
cache主要是失效策略和数据源
if( 没有cache 有效 (判断各种失效策略 ){ 获取 cache 里的数据 }else { 根据请求参数获取数据源 ... (各种数据源读取) 更新 cache } 返回 cache 如果这种代码到处写,感觉很丑陋,有没有比较统一的设计模式 ? |

 |
8
incompatible 2014 年 11 月 20 日
getCommits这里对concurrent的使用方式并不是一个良好的实践
试想如果前端向后段发送了大量的getCommits请求,且每个请求中的sha数目都超过了8,那么就会生成N*8个新线程。这样会导致jvm性能下降,也可能引发由线程栈爆满引起的OutOfMemoryError java工程中concurrent的最佳实践是这样的: 1. 使用一个service component来提供thread pooling功能,所有业务逻辑中的异步任务都提交到这一个thead pool中处理。 2. 不要使用Executors提供的工厂方法创建ExecutorService。推荐使用ThreadPoolExecutor的最复杂的那个构造方法。在这里你可以指定thread pool的大小、线程回收机制、队列大小、队列满员时的处理方式 做到以上两点,才能实现对concurrent线程数目的整体把控 |
|
9
incompatible 2014 年 11 月 20 日 @caixiexin
与数据库(以及其它外部repository)打交道的核心思想之一就是batching 能在一个请求中做完的就不要分拆成多个请求 正文这里的repo假如能提供一个getCommitsBatch(String[] sha)方法,也就没有必要动用concurrent了 |
 |
10
RoshanWu 2014 年 11 月 20 日
@incompatible 虽然看不太懂,但感觉很牛逼的样子,赞一个👍
|

|
12
caixiexin 2014 年 11 月 20 日
@incompatible 确实。。最近工作上就有一次被这个坑了。。
|
 |
13
humiaozuzu 2014 年 11 月 20 日
写的很虚,有些东西不需要结合业务都可以说的很细的。
|



 |
17
jack230230 2014 年 11 月 20 日
@incompatible getCommit 可不是简单的像数据库查询一条记录那样,而且这个过程不想数据库查询,batch 主要是解决数据库链接开销和往返的时延,这里明显不是为了解决时延。
|
|
18
incompatible 2014 年 11 月 20 日
@jack230230 对 正因为我不了解那个repo.getCommit具体是做什么用的,所以才用了“假如”的字样
|