最近我们开源了一个 PDF 处理工具 - pdf-craft,专注于解决扫描书籍 PDF 转换的痛点,让书籍数字化更智能。pdf-craft 支持将 PDF 转为 Markdown 和 EPUB ,智能处理文本、图表、公式等内容,适用于技术文档、书籍数字化、论文研究等场景。
痛点与解决方案
- PDF 不便于移动设备阅读:将 PDF 转为 EPUB ,适配各种屏幕大小
- 书籍结构混乱:智能分析章节、目录,重建结构化内容
- 注释和引用难以追踪:使用 LLM 智能处理注释和引用
- OCR 识别错误多:结合 LLM 自动矫正识别错误
- 扫描件 PDF 难以被 AI 、代码处理:分析并结构化 PDF 扫描件,以供 AI 、代码读取
主要特性
-
PDF 转 Markdown
- 纯本地运行,GPU 加速支持
- 智能过滤页眉页脚等无关元素
- 自动处理跨页文本顺接
- 图表、公式自动提取为图片
-
PDF 转 EPUB
- 智能构建书籍结构和目录
- 提取并保留注释和引用,并在 EPUB 中以合适的方式重新组织
- 支持中断恢复分析
- LLM 辅助校正 OCR 错误
-
技术亮点
- 结合 DocLayout-YOLO 布局分析
- 使用 OnnxOCR 进行文本识别
- 集成 layoutreader 优化阅读顺序
- 可接入 DeepSeek 等 LLM 服务
技术细节
项目基于 Python 开发,可通过 pip 安装:
pip install pdf-craft
核心使用方法示例:
# PDF 转 Markdown (纯本地处理)
from pdf_craft import PDFPageExtractor, MarkDownWriter
extractor = PDFPageExtractor(
device="cuda:0", # GPU 加速
model_dir_path="/path/to/model/dir/path",
)
with MarkDownWriter(markdown_path, "images", "utf-8") as md:
for block in extractor.extract(pdf="/path/to/pdf/file"):
md.write(block)
对于更复杂的 EPUB 转换,可以接入 LLM:
from pdf_craft import LLM, analyse, generate_epub_file
# 配置 LLM
llm = LLM(
key="sk-XXXXX",
base_url="https://api.deepseek.com",
model="deepseek-chat",
token_encoding="o200k_base",
)
# 分析 PDF
analyse(
llm=llm,
pdf_page_extractor=extractor,
pdf_path="/path/to/pdf/file",
analysing_dir_path="/path/to/temp",
output_dir_path="/path/to/output",
)
# 生成 EPUB
generate_epub_file(
from_dir_path="/path/to/output",
epub_file_path="/path/to/book.epub",
)
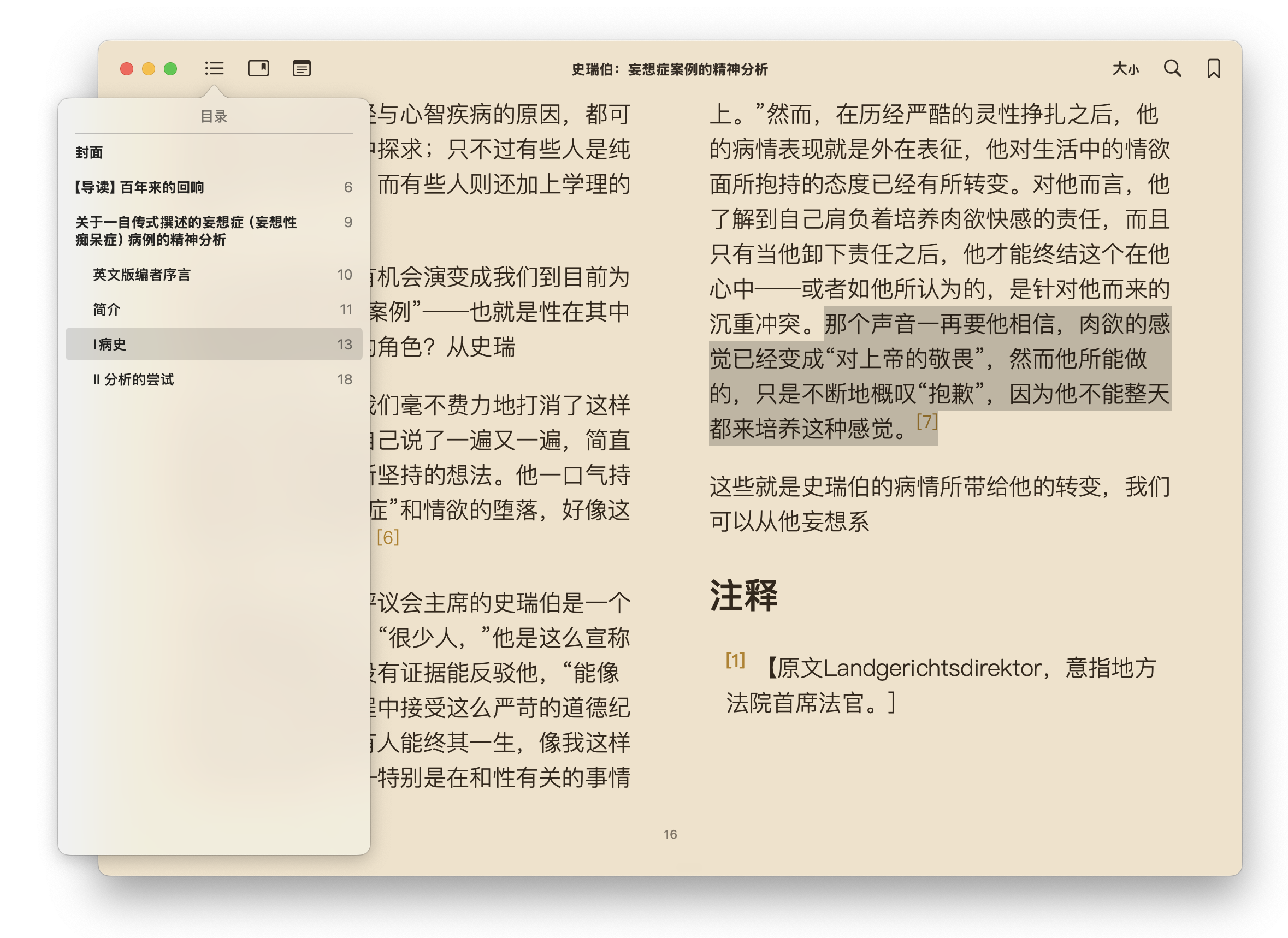
实际效果


立即体验,无需环境配置
想快速尝试 pdf-craft 而不想折腾环境配置?我们提供了更简单的方式: 使用 OOMOL Studio 一键体验:pdf-craft for OOMOL studio
OOMOL Studio 是我们开发的工作流 IDE ,内置了隔离的运行环境,无需复杂配置,即可立即体验 pdf-craft 的全部功能。 关于 OOMOL Studio 可以查看之前的介绍: 一款全新的工作流 IDE。
当然,pdf-craft 仍然完全开源,你依然可以按照上述方法在自己的环境中配置使用。
适用场景
- 技术文档阅读:将繁杂的技术文档转为结构化内容
- 书籍数字化:把纸质扫描书转为便携的电子书
- 论文研究:快速提取论文内容并方便引用
- 学习材料整理:将课程讲义处理为易于学习的格式
- 代码文档提取:从 PDF 教程中提取可用代码
开源与社区
项目刚刚起步,我们非常欢迎各位 V 友参与:
- GitHub 地址:https://github.com/oomol-lab/pdf-craft
- 问题反馈:https://github.com/oomol-lab/pdf-craft/issues
- 演示视频:Bilibili 链接
如果觉得不错,欢迎给项目点个 star ⭐,有什么想法也可以在评论区交流,或者提交 PR 一起完善这个工具。
你也可以通过 https://oomol.com/community/ 找到我们。