遇到过类似的问题,说下解决的方法
假设我们需要存储视频近 10 分钟内的访问量
存储方面,我们可以把 10 分钟,分割成 10 个 1 分钟,使用 Redis 的 bitmap 来存储这 10 个量
在命令方面,redis 的 BITFIELD 命令可以对 bitmap 的多个域同时操作,对每个域支持 GET 、SET 、INCRBY 子命令,可以满足需求
如图:
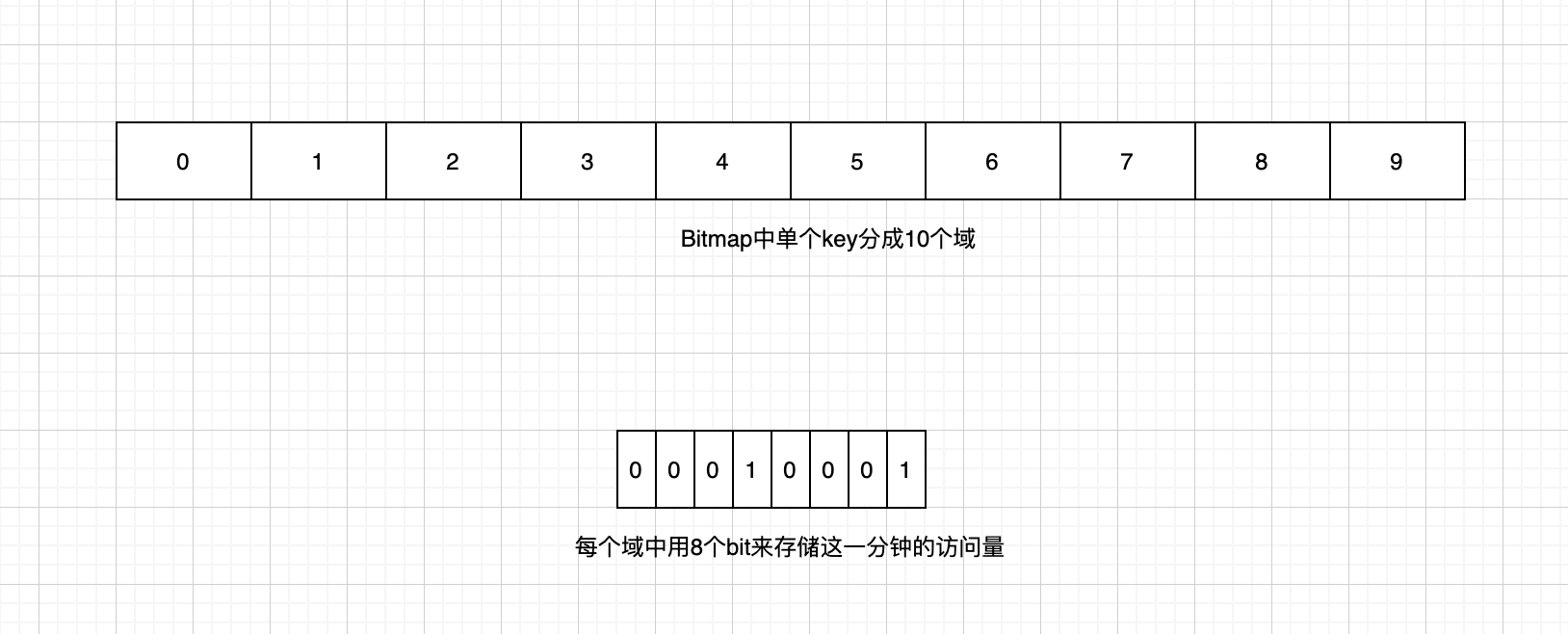
我们把 bitmap 分割成 10 个域,每个域代表 1 分钟的访问量,那么每次获取某个视频的访问量时,可以取到这 10 个域的值求和即可
假设每分钟视频的访问量的上限是 255 ( 2^8,这里是为了控制溢出,值可以无限大小,只要是 2 的正整数倍即可)
新增访问量时,只需计算应该往哪个 /哪些域( offset )里增加就可以了,如 22:13 的视频 123456 的访问量新增 17,根据时间计算 offset 为 3,命令:
`BITFIELD v:123456:cnt:bit OVERFLOW SAT INCRBY u8 0 17
这条命令返回对 offset 为 0 的域进行了+17 的操作,u8 表示按照 10 个 bit 分域,上限 255,0 标识 offset,即第 0 分钟,`OVERFLOW SAT`表示如果 incr 后的结果超过上限(这里是 2^8 ),那么结果保持在最大值 255 ( 8 位全 1 )
获取视频 123456 近 10 分钟的访问量,命令:
`BITFIELD v:123456:cnt:bit GET u8 GET u8 1 GET u8 2 GET u83 GET u8 4 GET u8 5 GET u8 6 GET u8 7 GET u8 8 GET u8 9`
这条命令会返回每个域(即每分钟)的值,求和后即为近 10 分钟的累计访问量
BITFIELD 的每个子命令的复杂度是 O(1)的,如果访问 /操作 N 个视频的近 10 分钟的访问量,也就是操作 N 次 Redis 即可
方案的优点
1. 省空间,bitmap 占用空间很小
2. 支持批量,BITFIELD 的子命令可以多个同时操作
缺点:
1. 不是严格的滑动窗口,有一定的精度损失
这个可以通过拆细粒度来解决,如 10 秒(甚至 1 秒)一个域,相应地,这样会增加一定的存储
2. 设计时需要考虑单个单位时间内的上限,超过上限时,统计不准,因为我们在溢出控制时使用了饱和算法( SAT )
这个可以在设计初期尽量预留一个保险的值,当然了,越大的话,存储也会越大
3. 对于读写分离的场景(即读从写主),BITFIELD 被 Redis 标识为写命令,所以所有的 BITFIELD 都会在主节点上执行
这个问题我们遇到了,但没有造成很高的负载,所以没有处理;不过阿里云有篇文章可以参考:
https://developer.aliyun.com/article/757841


















