
我用了 qwen3.5-27B 能跑但是比较慢, 换成 9B 的比较快但不太聪明.
我本地用的推理框架是 omxl, 然后用小龙虾对接, 干活是能干活,就是有点慢, 当然和 codex 不能比, 可惜 codex/claude code 这些 key 烧的太快, 要等 7 天后, 这也是我本地跑大模型追去无限 token 的初衷.
请问各位能给予我的配置推荐几个更好更聪明的大模型吗?
另外基于刚出的谷歌 atomic chat, 这几天有人逆向优化了它, 号称在普通的 macbook 上也可流畅加载 35B 大模型,KV 缓存直接压缩 4.6 倍,不到一周就有 1.5K stars 了.
这是 github 仓库地址 https://github.com/TheTom/turboquant_plus
不过它是加载进 llama.cpp 部署, 这个切换模型需要手动, 我懒得折腾了, V 站有闲的人去折腾下, 然后告诉我实际效果吧, 可以的话我准备照抄作业.
另外附加上当前 qwen3.5-9b 的 tokens 用量, 真的很快, 随便让小龙虾干点活就上千万 token.
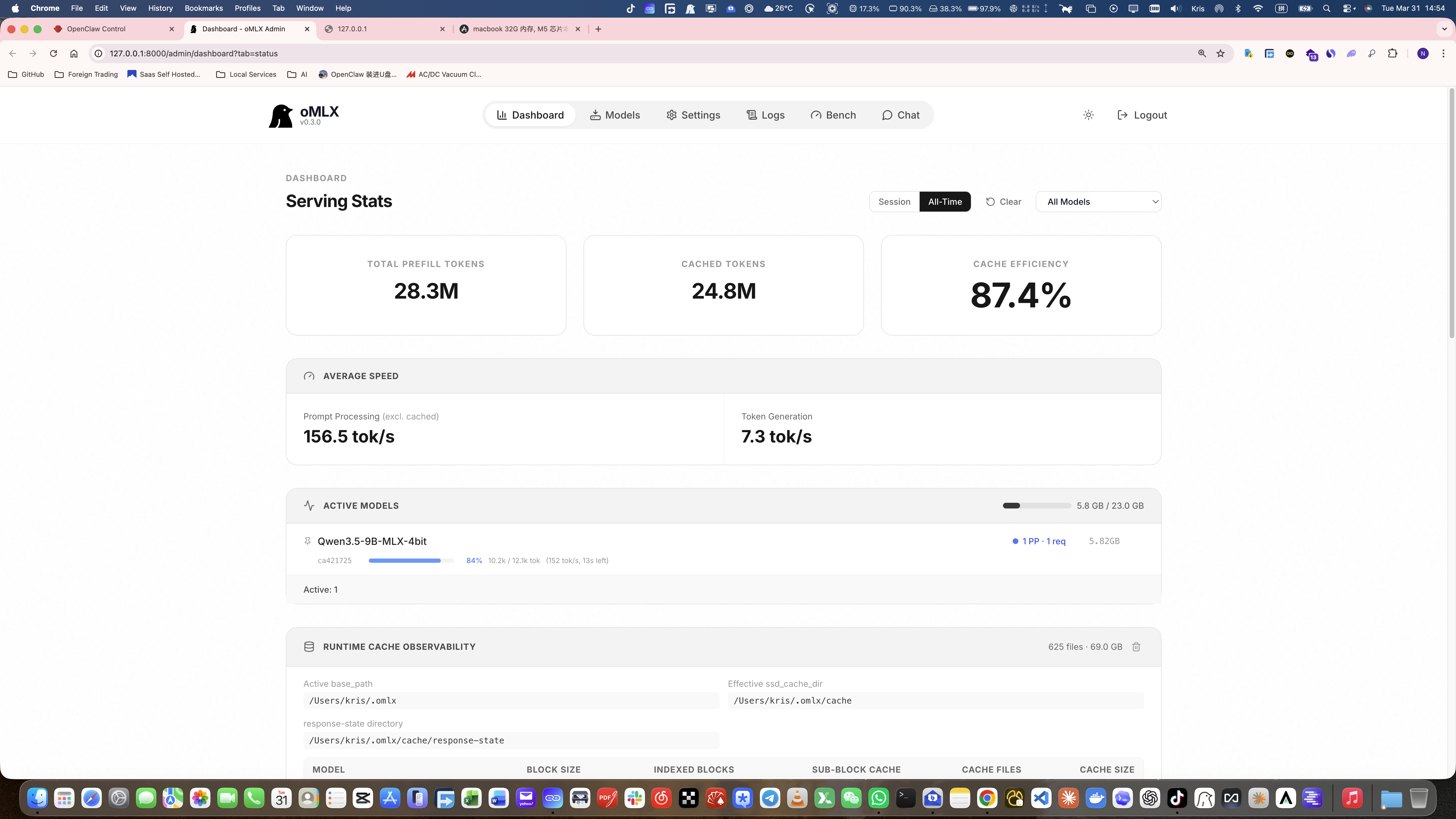
我本地用的推理框架是 omxl, 然后用小龙虾对接, 干活是能干活,就是有点慢, 当然和 codex 不能比, 可惜 codex/claude code 这些 key 烧的太快, 要等 7 天后, 这也是我本地跑大模型追去无限 token 的初衷.
请问各位能给予我的配置推荐几个更好更聪明的大模型吗?
另外基于刚出的谷歌 atomic chat, 这几天有人逆向优化了它, 号称在普通的 macbook 上也可流畅加载 35B 大模型,KV 缓存直接压缩 4.6 倍,不到一周就有 1.5K stars 了.
这是 github 仓库地址 https://github.com/TheTom/turboquant_plus
不过它是加载进 llama.cpp 部署, 这个切换模型需要手动, 我懒得折腾了, V 站有闲的人去折腾下, 然后告诉我实际效果吧, 可以的话我准备照抄作业.
另外附加上当前 qwen3.5-9b 的 tokens 用量, 真的很快, 随便让小龙虾干点活就上千万 token.


















